")
Sept mois après la livraison de Pentaho 7.0 qui permet aux utilisateurs métiers de visualiser les données préparées par la IT, la plateforme d’intégration open source bénéficie d’une série d’améliorations sur les technologies big data. En version 7.1, le support du moteur de traitement Spark se fait à toutes les étapes d’intégration des données dans un environnement visuel de type drag and drop, plus accessible à des non-développeurs. Pentaho permet de créer la logique d’intégration une fois pour toute avant de laisser le choix, au moment de l’exécution, du moteur de traitement de données qui sera le plus approprié pour chaque charge de travail. Pour l’instant la version 7.1 supporte Spark et Pentaho Kettle. D’autres moteurs seront pris en compte ultérieurement en fonction de la demande du marché. « Nous travaillons toujours davantage pour enlever la complexité sur les technologies big data qui évoluent très vite, les architectes ayant parfois du mal à anticiper celles qu’ils vont utiliser par rapport aux cas d’usage », nous a expliqué Urszula Radczynska, responsable des comptes Entreprise de Pentaho pour la France.
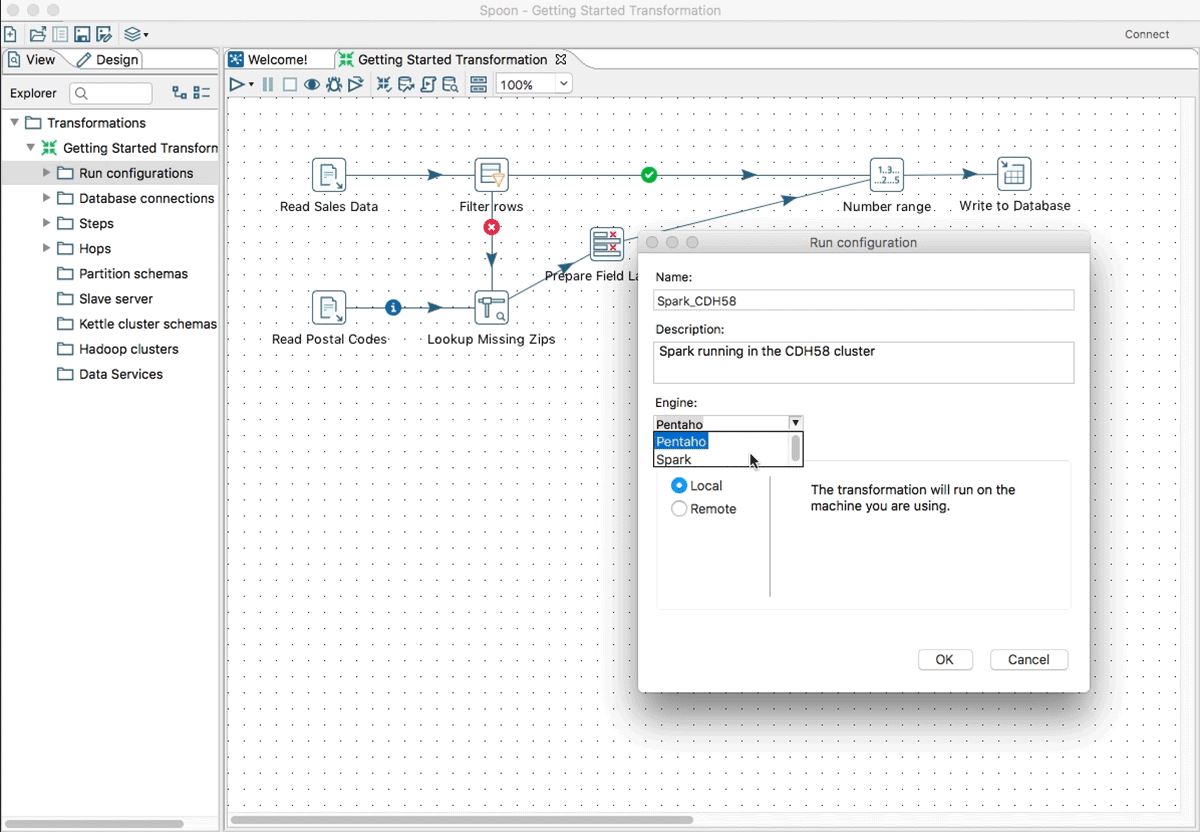
On choisit son moteur (Spark ou Pentaho Kettle) au moment de l'exécution... (agrandir l'image)

... sans avoir besoin de réécrire la logique d'intégration en fonction du moteur choisi. (agrandir l'image)
Du côté du cloud public, Pentaho supportait déjà le service Amazon Elastic MapReduce (EMR) qui permet d'exécuter des infrastructures Apache Hadoop, Spark, HBase, Presto et Hive. « Nous allons maintenant supporter aussi les déploiements avec Microsoft Azure HDInsight. Avec Pentaho 7.1, les clients peuvent choisir mener des projets analytiques hybrides avec des données on premise et dans le cloud », indique Urszula Radczynska. Les entreprises utilisant Azure HDInsight peuvent donc passer par Pentaho pour acquérir, agréger, nettoyer puis analyser leurs données à plus ou moins grande échelle. Le service de base de données cloud Azure SQL, ainsi que SQL Server dans des VM Azure peuvent également être utilisés.
Support de Kerberos et Ranger avec Hortonworks
Sur les aspects de sécurité qui constituent toujours une problématique avec les clusters Hadoop, cette version 7.1 apporte aussi une meilleure intégration avec la distribution Hadoop d'Hortonworks. « Nous supportons Kerberos et Rangers », souligne la responsable des comptes Entreprise en rappelant que la plateforme supportait déjà les fonctions de sécurité avancées de la distribution Cloudera. Kerberos protège les clusters contre les intrusions sur les déploiements Hortonworks et Apache Ranger permet de gérer la gouvernance et de contrôler les accès basés sur des rôles pour l'utilisation de certains jeux de données.
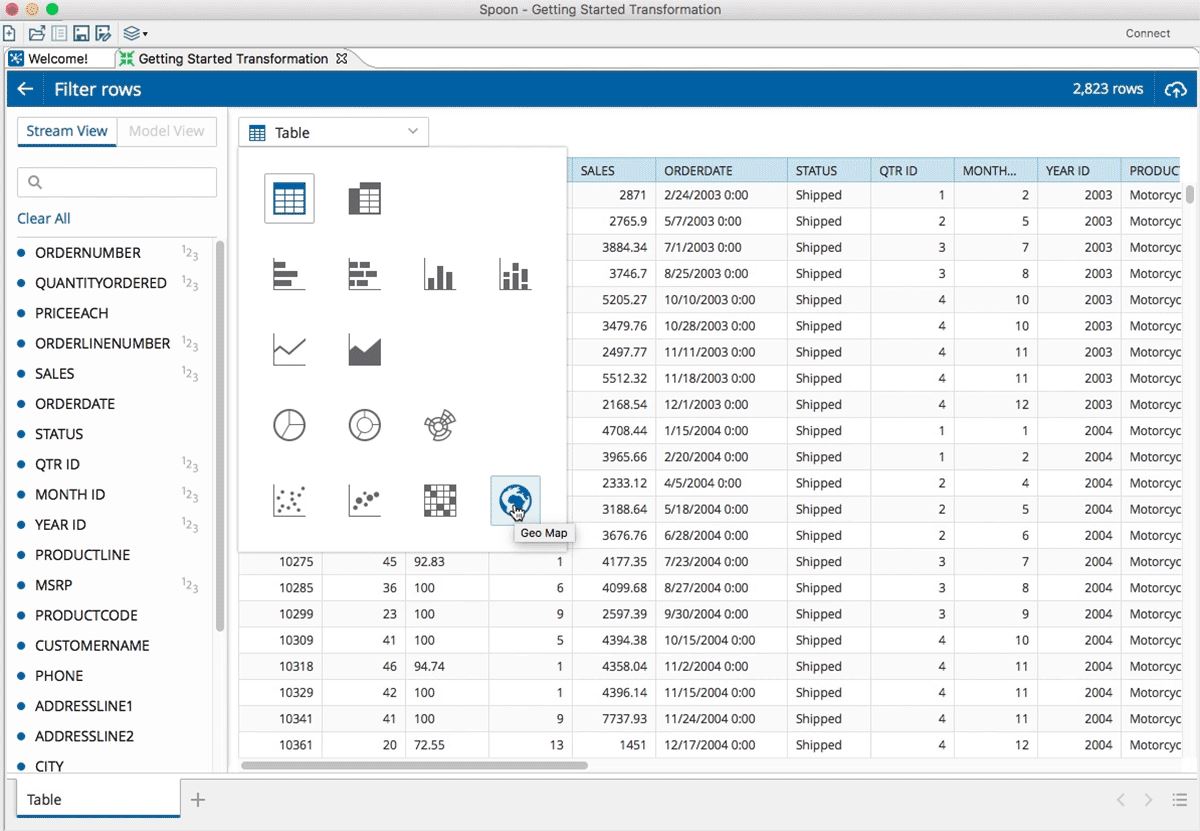
La version 7.1 a étendu la visualisation de données à l'ensemble du pipeline de données... (agrandir l'image)
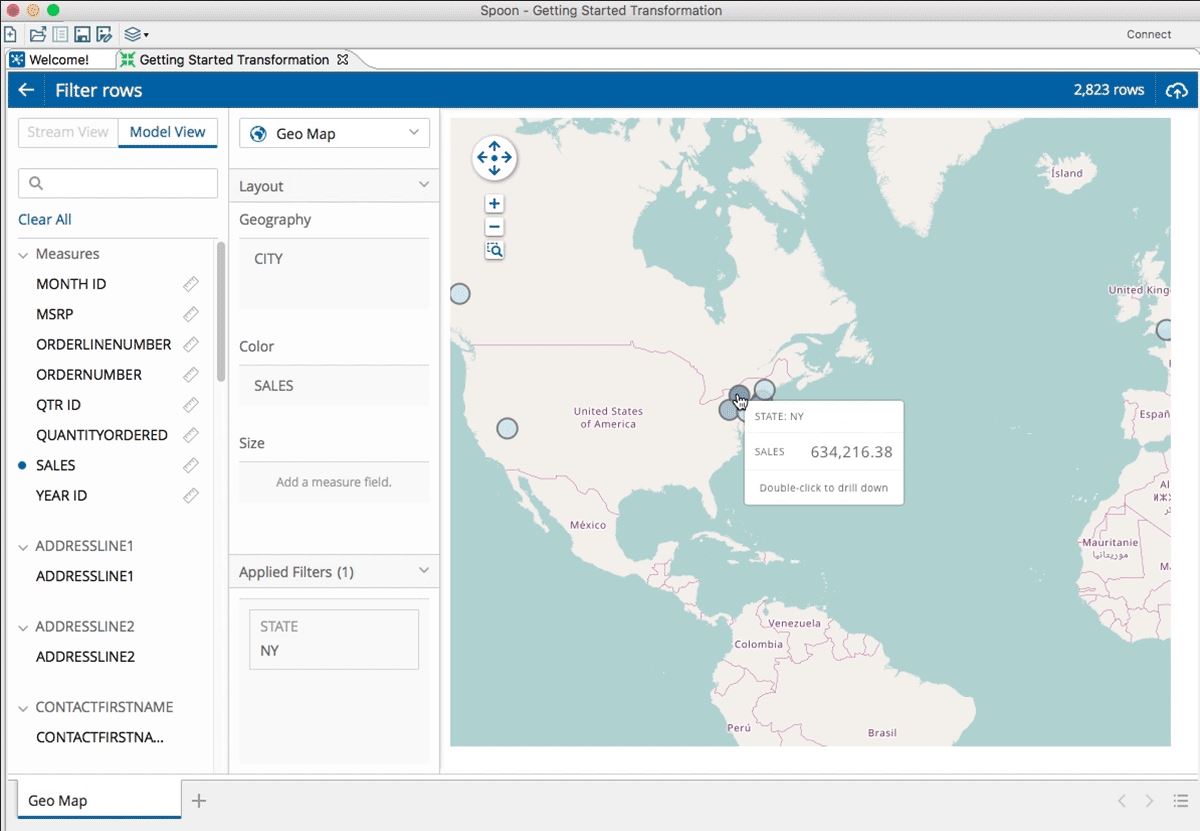
... avec une intégration plus facile avec certaines bibliothèques graphiques. (agrandir l'image)
Enfin, Pentaho a étendu la visualisation sur le pipeline des données dès l’origine et à chaque étape « avec la capacité de faire du drill down sur les différentes valeurs ». Urszula Radczynska rappelle que les data analysts et data scientists ont besoin de visualiser les données très tôt pour repérer les problèmes de qualité. La v.7.1 propose aussi une intégration plus facile avec des bibliothèques graphiques telles que D3 ou FusionCharts.
Synergie avec les forces commerciales d'Hitachi
Racheté il y a deux ans par HDS (Hitachi Data System), Pentaho évolue comme une société indépendante tout en collaborant aux projets Internet des objets et prédictifs menés par Hitachi. « En France, nous continuons à renforcer nos équipes de vente et poursuivons l’intégration avec le groupe Hitachi. Nous travaillons en synergie avec les forces commerciales d’Hitachi pour qu’elles puissent positionner notre offre », nous a indiqué Urszula Radczynska. Les équipes de l’Hexagone vont se renforcer avec des compétences techniques et commerciales dédiées au marché français.
Commentaire