")
Et de trois. Après Determined AI fin juin et Zerto début juillet, c'est au tour d'Ampool de rejoindre la grande famille HPE. Les domaines d'activité de ces trois sociétés sont très variés : après l'accélération de l'entraînement des modèles de machine learning (Determined AI) et le PRA as a service (Zerto), c'est cette fois dans l'analytique cloud en mode service que HPE se renforce. En mettant la main sur Ampool, ce dernier étend les capacités de sa plateforme Ezmeral et proposera des services d'accélération des traitements analytiques via son environnement de paiement à l'usage GreenLake. Il en profite aussi pour doper sa contribution à la communauté open source. Derrière Ampool, on trouve en effet des ingénieurs et des développeurs impliqués dans des projets majeurs comme Apache Geode, Presto/Trino, Apache Spark et Apache Ranger. Une équipe forte également d'avoir travaillé pour des sociétés comme Yahoo, LinkedIn, VMware/Pivotal ou encore Veritas.
Fondée en 2015 et installé à Santa Clara (en Californie) mais aussi à Pune (en Inde), Ampool a créé une technologie de mise en cache de type in memory (RAM et flash) qui améliore les performances des traitements de données (hybride, multi-cloud...). Par exemple jusqu'à 40 fois plus que le service de traitement big data Elastic MapReduce d'AWS et 100 fois plus que les requêtes issues de la plateforme de visualisation de données de Tableau Software. Ampool possède également une expertise approfondie, notamment dans la création de catalogue de métadonnées partagé. Et ce avec contrôle d'accès basé sur les rôles fournissant une vue cohérente des différentes sources de données principales.
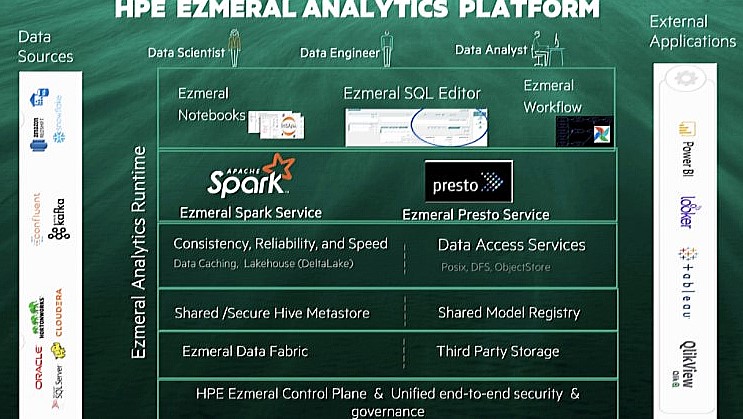
Les technologies Ampool viennent renforcer l'analytics runtime d'Ezmerald. (crédit : HPE)
Palier les lacunes de l'outillage SQL traditionnel
« En 2015, la plateforme big data dominante, Apache Hadoop, a excellé dans le stockage et l'analyse de pétaoctets de données. Cependant, la nature orientée batch des frameworks de calcul et l'abstraction du système de fichiers WORM (write-once read-many) dans l'écosystème Hadoop signifiait un accès aux données avec une haute latence, peu adapté à l'analyse en temps réel. Nous avons résolu ces limitations en créant Ampool Active Data Store (ADS), une couche de mise en cache analytique, basée sur Apache Geode (version OSS de Pivotal Gemfire) et en l'intégrant à des frameworks de calcul de premier plan dans l'écosystème Hadoop, tels qu'Apache Hive, Apache Spark et Presto », a expliqué Milind Bhandarkar, CTO et fondateur d'Ampool.
ADS prend en charge en particulier l'ingestion de flux, le traitement par lots, les transactions et les requêtes dynamiques à partir d'un seul data store... « Ampool a construit une couche de fédération de données unique et évolutive combinée à un moteur d'accélération à plusieurs niveaux pour augmenter les vitesses de traitement des requêtes analytiques à grande échelle », a indiqué de son côté Anant Chintamaneni, vice-président et responsable de l'activité Ezmeral chez HPE. Il permet de palier aux lacunes de l'outillage SQL sur site traditionnel, bien souvent trop rigide, lent et pas suffisamment adapté aux technologies de stockage sous-jacente telle que HDFS. « L'utilisation de plusieurs moteurs de calcul SQL éphémères basés sur des conteneurs, tels que Presto et Spark, introduit la nécessité de stocker et de gérer des métadonnées persistantes en externe », a précisé Anant Chintamaneni.
Commentaire