
L'un de mes premiers projets en tant que développeur de logiciels consistait à développer des algorithmes d'analyse génétique. Nous avons créé un logiciel pour scanner des échantillons d'électrophorèse dans une base de données, et mon travail consistait à convertir chaque image de motif ADN en données représentables. Pour ce faire, je transformais l'image en un vecteur, chaque point représentant les attributs de l'échantillon. Une fois vectorisée, nous pouvions stocker l'information de manière efficace et calculer la similarité entre les échantillons d'ADN. Aujourd'hui, la conversion d'informations non structurées en vecteurs est courante et utilisée dans les grands modèles de langage (LLM), la reconnaissance d'images, le traitement du langage naturel, les moteurs de recommandation et d'autres cas d'utilisation de l'apprentissage automatique.
Les bases de données vectorielles et la recherche vectorielle sont les deux principales plateformes que les développeurs utilisent pour convertir des informations non structurées en vecteurs, maintenant plus couramment appelés embeddings. L’embedding est une méthode de transformations de données provenant d'images, de textes, de sons, de données utilisateur, ou de tout autre type d’information, en vecteurs numériques. Une fois l'information codée en tant qu'embedding, il devient plus facile, rapide et nettement plus évolutif de stocker, rechercher et comparer ces informations pour de grands ensembles de données.
« Dans notre exploration pionnière du monde des bases de données vectorielles, nous avons observé que malgré le battage médiatique, leur véritable potentiel est souvent sous-estimé », explique Charles Xie, CEO de Zilliz. « Le véritable trésor des bases de données vectorielles réside dans leur capacité à plonger profondément dans l'immense réservoir de données non structurées et à en libérer la valeur. Il est important de réaliser que leur rôle ne se limite pas au stockage de mémoire pour les LLM, et elles possèdent des capacités transformatrices que beaucoup commencent à peine à découvrir. »
Comment fonctionnent les bases de données vectorielles
Imaginez que vous construisez une capacité de recherche pour des appareils photo numériques. Ces derniers ont des dizaines d'attributs, y compris la taille, la marque, le prix, le type d'objectif, le capteur, la résolution de l'image et d'autres caractéristiques. Un moteur de recherche pour appareils photo numériques dispose de 50 attributs pour rechercher parmi 2 500 appareils photo. Il existe de nombreuses façons de mettre en œuvre des recherches et des comparaisons, mais une approche consiste à convertir chaque attribut en un ou plusieurs points de données dans un embedding. Une fois les attributs vectorisés, les formules de distance vectorielle peuvent calculer les similarités de produits et les recherches.
Les appareils photo représentent un problème de faible dimensionnalité, mais imaginez quand votre problème nécessite la recherche de centaines de milliers d'articles scientifiques ou la fourniture de recommandations musicales sur plus de 100 millions de chansons. Les mécanismes de recherche conventionnels échouent à cette échelle, mais la recherche vectorielle réduit la complexité de l'information et permet des calculs plus rapides.
« Une base de données vectorielle encode l'information en une représentation mathématique qui est idéalement adaptée à la compréhension par les machines », souligne Josh Miramant, CEO de BlueOrange. « Ces représentations mathématiques, ou vecteurs, peuvent encoder les similitudes et les différences entre différentes données, comme deux couleurs seraient représentées par des vecteurs plus proches. Les distances, ou mesures de similarité sont ce que de nombreux modèles utilisent pour déterminer le meilleur ou le pire résultat d'une question. »
Cas d'utilisation des bases de données vectorielles
L'une des fonctions d'une base de données vectorielle est de simplifier l'information, mais sa véritable puissance réside dans la construction d'applications pour prendre en charge une large gamme de requêtes en langage naturel. Les recherches par mots-clés et les formulaires de recherche avancée simplifient la traduction des recherches en requêtes, mais le traitement des questions en langage naturel offre beaucoup plus de flexibilité. Avec les bases de données vectorielles, la question est convertie en un vecteur d'embedding utilisé pour effectuer la recherche.
Par exemple, je pourrais dire : « Trouve-moi un appareil photo reflex numérique à prix moyen, nouvellement sur le marché, avec une excellente capture vidéo et une bonne performance en basse lumière. » Un transformeur convertit cette question en un vecteur d'embedding. Les bases de données vectorielles utilisent couramment des transformeurs encodeurs. D'abord, le développeur tokenize la question en mots, puis utilise un transformeur pour encoder les positions des mots, ajouter des pondérations de pertinence, et créer des représentations abstraites à l'aide d'un réseau de neurones à propagation avant. Le développeur utilise ensuite le vecteur finalisé pour rechercher dans la base de données vectorielle.
Les bases de données vectorielles aident à résoudre le problème du soutien à une large gamme d'options de recherche dans une source d'information complexe avec de nombreux attributs et cas d'utilisation. Les modèles de langage de grande taille (LLM) ont mis en lumière la polyvalence des bases de données vectorielles, et maintenant les développeurs les appliquent dans les domaines du langage et d'autres domaines riches en informations.
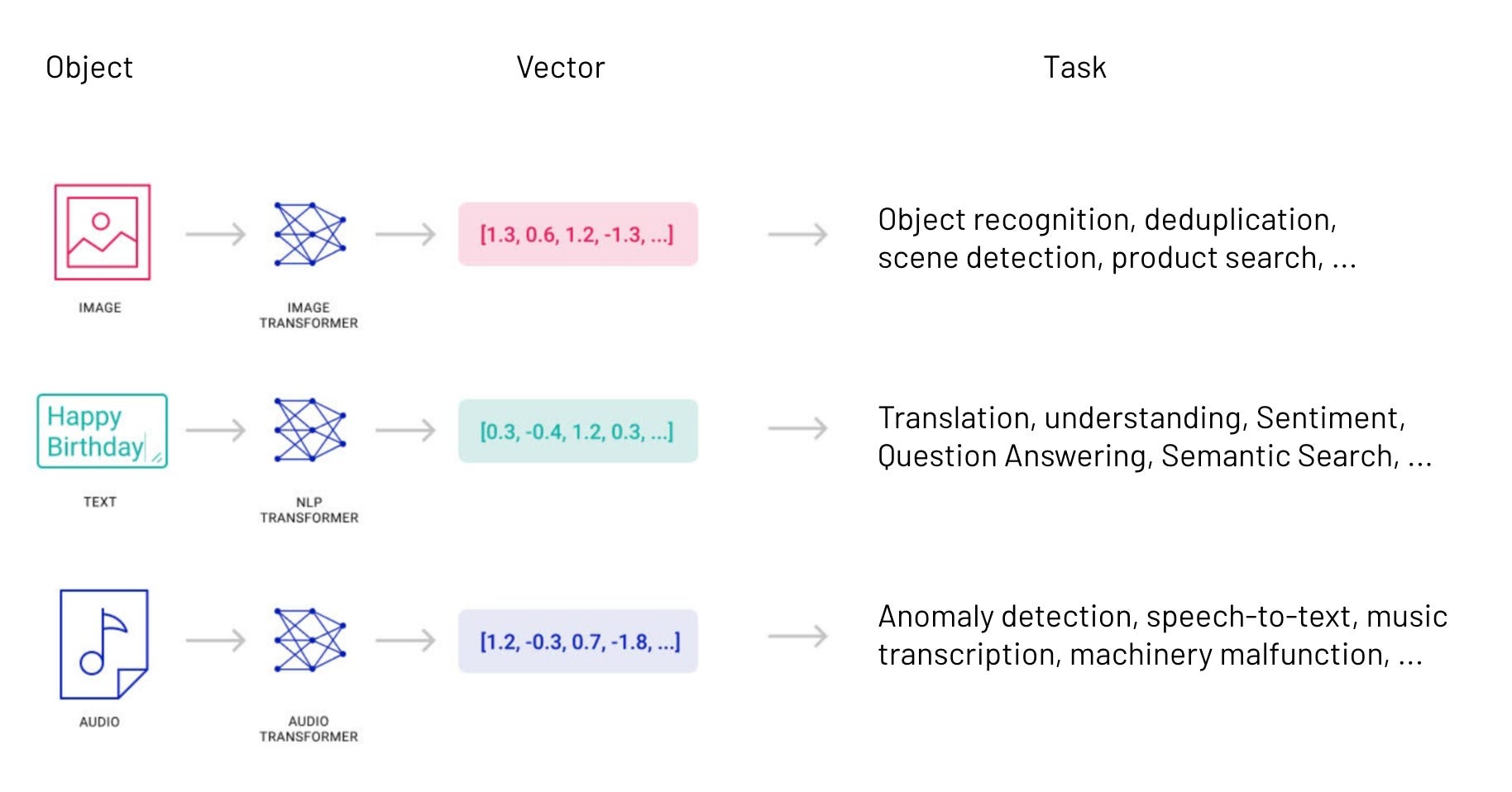
Les bases de données vectorielles et la recherche vectorielle sont les deux principales plateformes que les développeurs utilisent pour convertir des informations non structurées en vecteurs. (Crédit Pinecone)
« La recherche vectorielle a gagné rapidement en popularité à mesure que de plus en plus d'applications utilisent l'apprentissage automatique et l'intelligence artificielle pour alimenter les assistants vocaux, les chatbots, la détection d'anomalies, les moteurs de recommandation et de personnalisation, tous basés sur des embeddings vectoriels en leur cœur » précise Venkat Venkataramani, CEO de Rockset. « En étendant les capacités de recherche et d'analytique en temps réel à la recherche vectorielle, les développeurs peuvent indexer et mettre à jour les métadonnées et les embeddings vectoriels en temps réel, un élément vital pour alimenter les recherches de similarité, les moteurs de recommandation, les questions-réponses génératives et les chatbots. »
Utilisation des bases de données vectorielles dans les LLM
Les bases de données vectorielles permettent aux développeurs de construire des modèles de langage spécialisés, offrant un haut degré de contrôle sur la vectorisation de l'information. Par exemple, les développeurs peuvent créer des embeddings génériques pour aider les gens à rechercher tous types de livres sur un site de commerce électronique. Alternativement, ils peuvent créer des embeddings spécialisés pour des livres historiques, scientifiques ou autres catégories spéciales, permettant aux utilisateurs avancés et aux experts en la matière de poser des questions détaillées sur le contenu des livres d'intérêt.
« Les bases de données vectorielles fournissent simplement un moyen facile de charger beaucoup de données non structurées dans un modèle de langage, » indique Mike Finley, CTO d'AnswerRocket. « Les équipes de données et de développement d'applications devraient considérer une base de données vectorielle comme un dictionnaire ou un index de connaissances, avec une longue liste de clés (pensées ou concepts) et une charge utile (texte lié à la clé) pour chacune d'elles. Par exemple, vous pourriez avoir une clé “tendances de consommation en 2023” avec une charge utile contenant le texte d'une analyse d'enquête d'une société d'analystes ou d'une étude interne d'une entreprise de produits de consommation. »
Choisir une base de données vectorielle
Les développeurs ont plusieurs options technologiques lorsqu'ils convertissent des informations en embeddings et construisent des fonctions de recherche vectorielle, de comparaisons de similarité et de questions-réponses.
« Nous avons à la fois des bases de données vectorielles dédiées arrivant sur le marché ainsi que de nombreuses bases de données généralistes conventionnelles avec des extensions vectorielles, » explique Peter Zaitsev, fondateur de Percona. « Un choix auquel les développeurs sont confrontés est de savoir s'il faut adopter ces nouvelles bases de données, qui peuvent offrir plus de fonctionnalités et de performances, ou continuer à utiliser des bases de données généralistes avec des extensions. Si l'histoire peut servir de guide, il n'y a pas de réponse unique, et en fonction de l'application en cours de construction et de l'expérience de l'équipe, les deux approches ont leurs mérites. »
Rajesh Abhyankar, responsable du GenAI COE chez Persistent Systems, précise : « Les bases de données vectorielles couramment utilisées pour les moteurs de recherche, les chatbots et le traitement du langage naturel incluent Pinecone, FAISS (Facebook AI Similarity Search) et Mivus. » Il poursuit : « Pinecone est bien adapté aux systèmes de recommandation et à la détection de fraude, FAISS pour la recherche d'images et les recommandations de produits, et Milvus pour la recherche et les recommandations en temps réel haute performance. »
D'autres bases de données vectorielles sont utilisées : Chroma, LanceDB, Marqo, Qdrant, Vespa et Weaviate. Les bases de données et moteurs prenant en charge les capacités de recherche vectorielle incluent Cassandra, Coveo, Elasticsearch OpenSearch, PostgreSQL, Redis, Rockset et Zilliz. La recherche vectorielle est une capacité d’Azure Cognitive Search, et Azure a des connecteurs pour de nombreuses autres bases de données vectorielles. AWS prend en charge plusieurs options de bases de données vectorielles, tandis que Google Cloud propose Vector AI Vector Search et des connecteurs vers d'autres technologies de bases de données vectorielles.
Risques liés aux bases de données vectorielles et à l'IA générative
L'utilisation des bases de données vectorielles et de la recherche entraîne quelques risques courants liés à l'IA générative tels que la qualité des données, les problèmes de modélisation, etc. Des problèmes incluent les hallucinations et les fabulations. Certaines façons de traiter ces dernières incluent l'amélioration des données d'entraînement et l'accès à l'information en temps réel. « La distinction entre hallucinations et fabulations est importante lorsque l'on considère le rôle des bases de données vectorielles dans le workflow des LLM, » déclare Joe Regensburger, VP de la recherche chez Immuta. « Strictement du point de vue de la prise de décision en matière de sécurité, la fabulation présente un risque plus élevé que l'hallucination, car les LLM produisent des réponses plausibles. »
Regensburger partage deux recommandations pour réduire les inexactitudes des modèles. « Obtenir de bons résultats d'un LLM nécessite de disposer de bonnes données, bien organisées et gouvernées, quel que soit l'endroit où elles sont stockées. » Il note également que « l'embedding est l'élément le plus essentiel à résoudre. » Il y a une science à créer des embeddings qui contiennent les informations les plus importantes et soutiennent une recherche flexible, dit-il.
Rahul Pradhan, VP produit et stratégie chez Couchbase, partage comment les bases de données vectorielles aident à résoudre les problèmes d'hallucination. « Dans le contexte des LLM, les bases de données vectorielles fournissent un stockage à long terme pour atténuer les hallucinations de l'IA afin de garantir que les connaissances du modèle restent cohérentes et fondées, minimisant le risque de réponses inexactes, » dit-il.
Conclusion
Lorsque les bases de données SQL ont commencé à devenir omniprésentes, elles ont mené à des décennies d'innovation autour de l'information structurée organisée en lignes et colonnes. Les bases de données NoSQL, colonnes, clés-valeurs, documents et objets permettent aux développeurs de stocker, gérer et interroger différents ensembles de données semi-structurées et non structurées. La technologie vectorielle est de manière similaire fondamentale pour l'IA générative, avec des effets d'entraînement potentiels similaires à ceux que nous avons vus avec SQL. Comprendre la vectorisation et être familier avec les bases de données vectorielles est une compétence essentielle pour les développeurs.