")
Dans toute discussion sur le big data, on finit forcément par parler de Hadoop ou d’Apache Spark. Si les deux outils sont parfois considérés comme des concurrents, il est souvent admis qu’ils fonctionnent encore mieux quand ils sont ensemble. Voici un aperçu de leurs caractéristiques et de leurs différences.
1- Hadoop et Apache Spark font des choses différentes.
Tous deux sont des frameworks big data, mais ils n’ont pas vraiment le même usage. Hadoop est essentiellement une infrastructure de données distribuées : ce framework Java libre distribue les grandes quantités de données collectées à travers plusieurs nœuds (un cluster de serveurs x86), et il n’est donc pas nécessaire d’acquérir et de maintenir un hardware spécifique et coûteux. Hadoop est également capable d’indexer et de suivre ces données big data, ce qui facilite grandement leur traitement et leur analyse par rapport à ce qui était possible auparavant. Comparativement, Spark sait travailler avec des données distribuées. Mais il ne sait pas faire du stockage distribué. Il a donc besoin de s’appuyer sur un système de stockage distribué.
2 - Il est possible d’utiliser Hadoop indépendamment de Spark et réciproquement.
Hadoop comprend un composant de stockage, connu sous le nom de HDFS (Hadoop Distributed File System), et un outil de traitement appelé MapReduce. De fait, il n’est pas nécessaire de faire appel à Spark pour traiter ses données Hadoop. Et inversement, il est possible d’utiliser Spark sans faire intervenir Hadoop. Spark n’a pas de système de gestion de fichiers propre, ce qui veut dire qu’il faut lui associer un système de fichiers - soit HDFS, soit celui d’une autre plate-forme de données dans le cloud. Néanmoins, Spark a été conçu pour Hadoop, et la plupart des gens s'accordent pour dire qu’ils fonctionnent mieux ensemble.
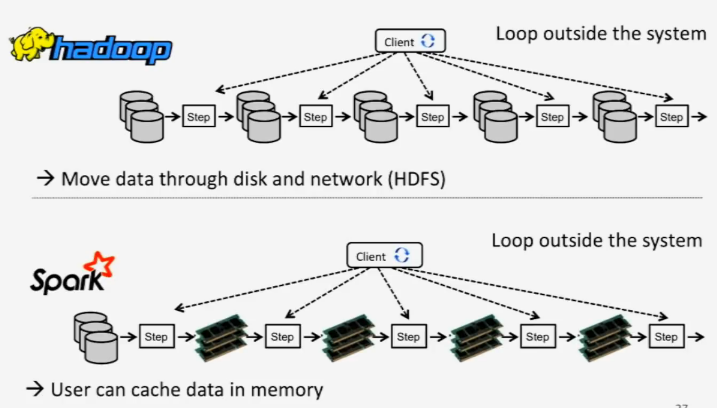
Hadoop ne travaille qu'en mode lots avec MapReduce alors que Spark fait du temps réel en in-memory.
3 - Spark est beaucoup plus rapide que Hadoop.
En effet, la méthode utilisée par Spark pour traiter les données fait qu’il est beaucoup plus rapide que MapReduce. Alors que MapReduce fonctionne en étapes, Spark peut travailler sur la totalité des données en une seule fois. « La séquence de travail de MapReduce ressemble à ceci : il lit les données au niveau du cluster, il exécute une opération, il écrit les résultats au niveau du cluster, il lit à nouveau les données mises à jour au niveau du cluster, il exécute l’opération suivante, il écrit les nouveaux résultats au niveau du cluster, etc. », explique Kirk Borne, spécialiste des données chez Booz Allen Hamilton, un conseiller en gestion basé en Virginie. Au contraire, Spark exécute la totalité des opérations d'analyse de données en mémoire et en temps quasi réel : « Spark lit les données au niveau du cluster, effectue toutes les opérations d’analyses nécessaires, écrit les résultats au niveau du cluster, et c’est tout », a ajouté Kirk Borne. « Spark est jusqu'à 10 fois plus rapide que MapReduce pour le traitement en lots et jusqu'à 100 fois plus rapide pour effectuer l'analyse en mémoire », a-t-il ajouté.
4 - Tout le monde n’a pas besoin de la rapidité de Spark.
Le mode de fonctionnement de MapReduce peut être suffisant si les besoins opérationnels et les besoins de reporting sont essentiellement statiques et s’il est possible d’attendre la fin du traitement des lots. Mais si l’on a besoin d’analyser des données en streaming, comme c’est le cas pour traiter des données remontées par capteurs dans une usine, ou si les applications nécessitent une succession d’opérations, il faudra probablement faire appel à Spark. C’est le cas de la plupart des algorithmes d'apprentissage machine qui ont besoin d’effectuer des opérations multiples. Spark est tout à fait adapté pour les campagnes de marketing en temps réel, les recommandations de produits en ligne, la cybersécurité et la surveillance des logs machine.
5 - Reprise après incident : différente, mais satisfaisante pour Hadoop et Spark.
Par nature, Hadoop est résilient aux pannes ou aux défaillances du système, car les données sont écrites sur le disque après chaque opération. Mais Spark offre la même résilience intégrée du fait que les objets de données sont stockés dans ce qu'on appelle des ensembles de données distribués résilients (RDD) répartis sur le cluster de données. « Ces objets de données peuvent être stockés dans la mémoire ou sur les disques, et les ensembles RDD permettent une récupération complète après panne ou défaillance », fait encore remarquer Kirk Borne.
Enfin j'ai compris : Merci !
Signaler un abusCela est été vraiment bénéfique a ma personne. Merci bien
Signaler un abusVisiteur8269; vous trouverez la réponse dans l'article lui-même. Il ne faut surtout pas oublier que Spark utilise les RDDs qui sont par nature des données résilientes et distribuées (des mots dont les initials composent le sigle RDD)
Signaler un abusComme sur HANA et d'autres, l'in-memory combine RAM et flash.
Signaler un abusJ'ai un doute sur le paragraphe concernant la reprise après incident "Mais Spark offre la même résilience intégrée du fait que les objets de données sont stockés..."
Signaler un abusVu que Spark stocke les données en mémoire, je pensais qu'après un incident, Spark devait tout recommencer toutes les opérations depuis le début contrairement à MapReduce qui écrit sur le disque.
Bonjour,
Signaler un abusEffectivement, l'utilisation conjointe des 2 technologies est ce qui amène le plus de puissance !
Pour en savoir plus sur Spark, je vous propose cet article "5 bonnes raisons de choisir Spark pour le traitement de vos Big Data" : http://blog.businessdecision.com/bigdata/2015/08/spark-traitements-big-data/
Bonne lecture !
"Passage en revue" merci
Signaler un abus