")
La percée de Deepseek a provoqué quelques remous dans le monde des LLM. Au point que plusieurs alternatives ont vu le jour comme le montre Alibaba avec Qwen 2.5 ou Mistral avec son SLM Small 3. Dans ce concert, il faut compter sur Tülu 3 élaboré par A2i (Allen Institute for AI). Cet institut de recherche à but non lucratif a été créé en 2014 par Paul Allen, co-fondateur de Microsoft avec Bill Gates. Le dernier modèle a été entraîné sur 405 milliards de paramètres et rivalise selon l’organisme avec Deepseek v3 et GPT-4o d’OpenAI. Présenté en novembre dernier, la première version de Tülu 3 entendait égaler les performances de Claude d’Anthropic et Gemini de Google.
Publié en open source, Tülu 3 405B se démarque de ses concurrents par une approche différente du post-entraînement. Ai2 se base sur le procédé « d'apprentissage par renforcement à partir de récompenses vérifiables (RVLR) ». Cette méthode se sert des résultats vérifiables - tels que la résolution correcte de problèmes mathématiques - pour affiner les performances du modèle. Elle a été associée à l'optimisation directe des préférences (DPO) pour ajuster directement les modèles en fonction des préférences humaines et à des données de formation soigneusement sélectionnées (du fine tuning supervisé).
Des bons résultats et une approche totalement open source
Sur le plan technique, cette approche apporte des améliorations comme un traitement parallèle plus efficace sur 256 GPU, la synchronisation optimisée des poids des LLM et la répartition équilibrée des calculs sur 32 nœuds. Le système basé sur RVLR a obtenu de meilleurs résultats à l'échelle de 405 milliards de paramètres que les modèles équivalents. Il a également atteint des résultats particulièrement bons dans les évaluations GSM8K (dataset sur plusieurs diplômes de sciences ou littéraires), surpassant DeepSeek V3, Llama 3.1 et Hermes 3 (créé par Tohfa Siddika Barbhuiya, chercheur en Australie). Il est à noter que l'efficacité de la technique RLVR augmente avec la taille du modèle, ce qui laisse entrevoir les avantages potentiels pour une modèle plus important. En comparaison, Deepseek devient plus performant en distillant des modèles plus petits, comme l’indiquait récemment Alexei Grinbaum, directeur de recherche au CEA.
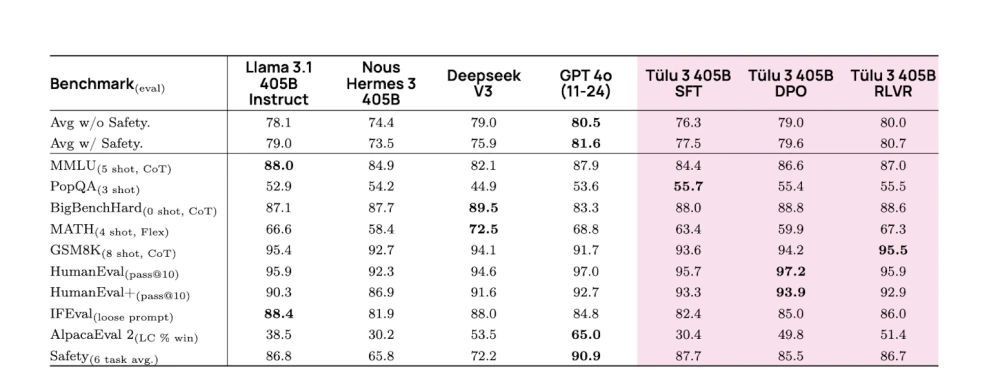
Les évaluations de Tülu 3 405B par rapport à la concurrence, réalisées par Ai2, avec les différents types d'optimisation du modèle. (Crédit Photo : Ai2)
Autre atout de Tülu 3, être réellement open source. En effet, DeepSeek ou Llama se définissent aussi comme ouvert, mais une partie du code n’est pas disponible, en particulier les données d’entraînement. « Nous n'exploitons pas d'ensembles de données fermés », a expliqué Hannaneh Hajishirzi, chercheur à l’université de Washington et membre d'A2i, dans un blog. Elle ajoute, « « comme pour notre première version de Tülu 3 en novembre 2024, nous publions tout le code de l'infrastructure ». Cette approche donne aux utilisateurs la capacité de personnaliser facilement leur pipeline, de la sélection des données à l'évaluation. Si le modèle 405B est disponible sur la page de Tülu 3 d'Ai2, il est également possible de tester la fonctionnalité dans l’espace Playground d'Ai2.
Commentaire