")
Après l’adoption l’an dernier du protocole S3 sur sa plateforme de stockage cloud privé Ring (objet et fichier), Scality accélère le tempo avec l’arrivée du contrôleur de données open source Zenko qui apporte la gestion multiclouds et le support de Microsoft Azure. « Avec le projet Zenko, nous aidons les entreprises à faire du multiclouds » , nous a indiqué Giorgio Regni, CTO de Scality. C’est en effet une demande des clients qui travaillent avec AWS S3 et qui cherchent un autre fournisseur cloud pour éviter de se faire piéger et reprendre la main dans le cadre de la relation commerciale. « Nous pensons que tout le monde devrait avoir le contrôle de ses données, » estime Giorgio Regni.
Si la majorité des applications cloud – privées et publics - sont aujourd’hui développées pour travailler avec l’API S3, ce n’est pas encore le cas pour Azure. Zenko vient donc ouvrir aux applications cloud natives les portes du stockage multi-plateforme, AWS S3 et Microsoft Azure pour commencer. « Beaucoup d’entreprises utilisent l’objet store pour faire du S3 en interne – même si elles ne sont pas encore sur S3. Elles utilisent encore le mode fichier en attendant l’arrivée de besoins en cloud interne, notamment pour une question de régularisation interne », nous a précisé le CTO de Scality. « Avec Zenko, Scality permet aux entreprises de déployer aisément, rapidement et de façon rentable des milliers d’applications dans l’environnement Microsoft Azure Cloud, et de profiter pleinement de ses nombreux services évolués, » a indiqué dans un communique de presse Jurgen Willis, chef de produits pour Azure Object Storage chez Microsoft. « Les données stockées avec Zenko sont au format natif Azure Blob Storage, et elles peuvent ainsi être traitées en toute simplicité dans le cloud Azure pour une évolutivité maximale. »
Une architecture modulaire pour étoffer le Ring
Ouverte, l’architecture de Zenko peut être complétée par des extensions également open source pour apporter de nouvelles fonctionnalités à la plateforme Ring. Avec Zenko, Scality permet aux entreprises de contrôler leurs données primaires stockées en local mais également les données temporelles hébergées temporairement dans le cloud public. Le contrôleur dispose ainsi du moteur Clueso – sur une base Apache Spark avec une interface query SQL pour les requêtes – pour appliquer des actions après l’affichage des résultats de recherche. Afficher par exemple les données non consultées depuis six mois pour ensuite les déplacer vers le cloud. Les actions concernent les données chaudes et froides mais pas seulement. On peut également décider de programmer la publication de vidéos sur un site web pour du replay. Les vidéos les plus populaires peuvent également être facilement repérées pour les compiler ensuite dans un bucket S3 avec un front end AWS pour bénéficier de services CDN si besoin.
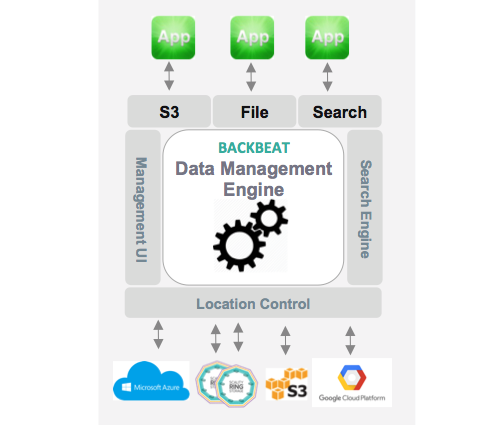
Plusieurs extensions pour Zenko seront disponibles en septembre et notamment le moteur de data management backbeat.
Scality met également en avant le gestionnaire de flux de Backbeat utilisé pour la réplication asynchrone et la migration de données ou les services cloud étendus tels que l’analytique et la distribution de contenu. C’est d’ailleurs Backbeat qui assure la cohérence entre les données stockées en local, sur S3 ou Azure en toute transparence pour les administrateurs.
Développé en Node.js par l’équipe à l’origine du projet S3 Server, le contrôleur Zenko est entré en phase de tests chez plusieurs clients aux Etas-Unis. Mais des clients français sont déjà intéressés par cette gestion multiclouds, avec des clouds internes mais pas seulement. Précisons que Zenko est actuellement disponible pour Microsoft Azure Blob Storage, Amazon S3, Scality Ring et Docker. Il devrait être également disponible prochainement pour d’autres plateformes cloud publics. On pense bien sûr immédiatement à Google, IBM ou OpenStack. Les extensions Blackbeat et Cluseo seront disponibles au mois de septembre.
Commentaire