")
Après une phase de test, Amazon Web Services a annoncé la disponibilité générale des instances pour le calcul haute performance et le machine learning. Baptisées P4d, ces instances ont la particularité d’être basées sur des GPU A100 Tensor Core de Nvidia. Elles sont conçues pour des applications cloud intégrant de l’IA comme le traitement du langage naturel, la détection et la classification d’objets, mais aussi pour effectuer de la modélisation utilisée pour l’analyse sismique ou la recherche génomique.
Les instances sont évolutives, souligne dans un blog Jeff Barr, vice-président et chef évangéliste d’AWS. « Les EC2 P4d comprennent des puces Intel Cascade Lake et les GPU A100 Tensor Core, l’interconnexion est assurée par NVLink et GPUDirect ». Les instances sont livrées avec 1,1 To de mémoire et 8 To de stockage sur SSD NVME. AWS indique que l’usage des GPU A100 de Nvidia pour le deep learning améliore les performances par 2,5 avec plus du double de quantité de mémoire et deux fois plus de traitements en virgule flottante à double précision par rapport aux instances P3, souligne le dirigeant.
Un cluster de 4 000 GPU A100 disponible
Amazon a indiqué que les instances P4d sont désormais disponibles dans les régions AWS US East (Virginie du Nord) et US West (Oregon). Par ailleurs, Jeff Bar a expliqué que des services d’apprentissage et d’orchestration comme SageMaker, Elastic Kubernetes Service, Elastic Container Service, ParallelCluster et Batch seront disponibles pour les instances P4d dans les prochaines semaines.
Pour les besoins les plus exigeants, AWS propose des UltraClusters. Ces nœuds comprennent plus de 4 000 GPU, avec une infrastructure réseau capable de supporter des Po de données, ainsi qu’un stockage haute performance et à faible latence. Les EC2 UltraClusters sont des supercalculateurs dans le cloud qu’AWS met à disposition des développeurs, des scientifiques et des chercheurs. « Grâce aux EC2 UltraClusters, les développeurs peuvent adapter leurs applications d'apprentissage du machine learning ou du HPC multi-nœuds à des milliers de GPU pour résoudre leurs problèmes les plus complexes, ou réduire à quelques instances seulement en ne payant que celles qu’ils utilisent », précise Jeff Barr
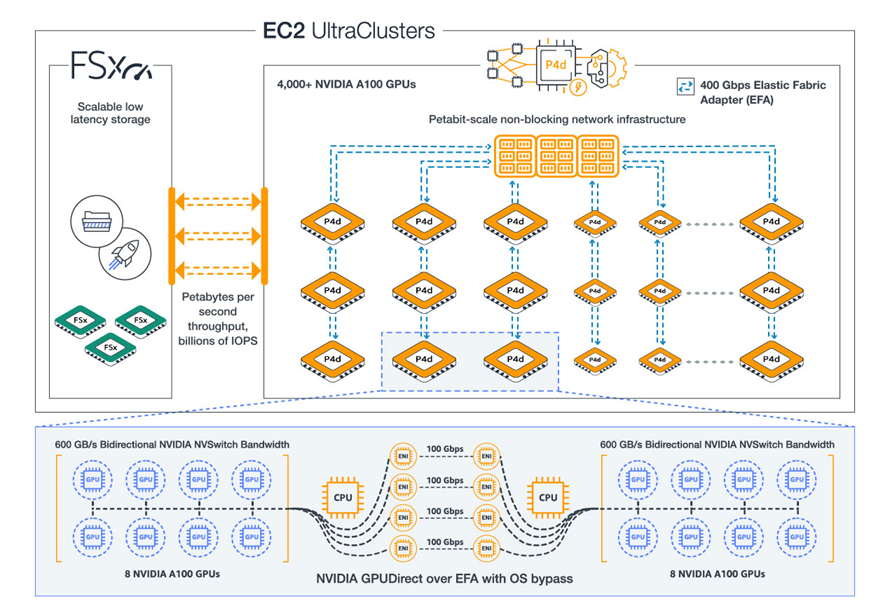
Schéma d'un UltraCluster EC2 avec des GPU A100 de Nvidia. (Crédit Photo : AWS)
Commentaire