")
Avec Claude, Anthropic ne compte bien pas se laisser distancer dans la course à la performance en matière de grands modèles de langage aux côtés de Llama de Meta, GPT d'OpenAI, Gemini de Google ou Large de Mistral AI... Le fournisseur a ainsi annoncé les lancements des dernières itérations de son LLM Claude 3 dont la plus performante Opus est disponible en même temps que Sonnet et Haiku.
Selon Anthropic, la déclinaison Opus surpasse ses concurrents sur la plupart des critères d'évaluation comprenant aussi bien les connaissances d'expert de premier cycle (MMLU), le raisonnement d'expert de deuxième cycle (GPQA) que les mathématiques de base (GSM8K). « Il présente des niveaux de compréhension et de fluidité proches de ceux de l'homme pour des tâches complexes, ce qui le place à la pointe de l'intelligence générale », avance même la société.
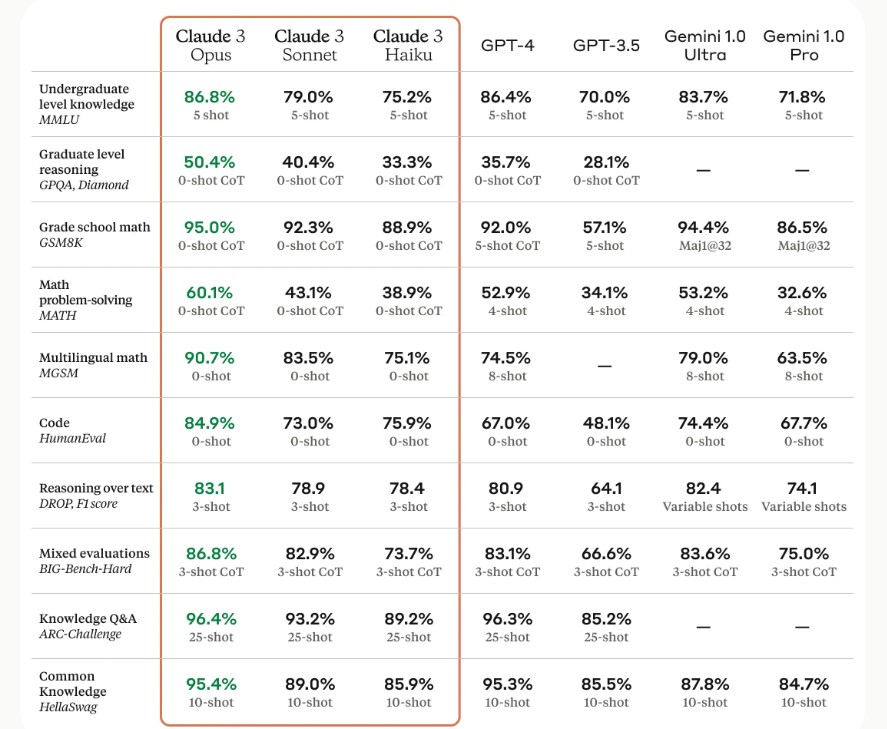
Comparaison de la performance de différents LLM. (crédit : Anthropic)
Claude se met au multimodal avec les images
Les LLM Claude 3 peuvent traiter une large gamme de formats visuels, y compris des photos, des tableaux, des graphiques et des diagrammes techniques. « Nous sommes particulièrement enthousiastes à l'idée de fournir cette nouvelle modalité à nos entreprises clientes, dont certaines ont jusqu'à 50 % de leurs bases de connaissances encodées dans divers formats tels que des PDF, des organigrammes ou des diapositives de présentation », indique Anthropic. Pour traiter efficacement les messages contextuels longs, l'éditeur indique par ailleurs avoir mis au point une évaluation baptisée « Aiguille dans une botte de foin » à savoir NIAH pour Needle In A Haystack afin de mesurer la capacité d'un modèle à rappeler avec précision des informations à partir d'un vaste corpus de données.
« Nous avons amélioré la robustesse de ce benchmark en utilisant l'une des 30 paires aléatoires aiguille/question par invite et en testant sur un corpus diversifié de documents provenant de la communauté. Claude 3 Opus a non seulement atteint un rappel presque parfait, dépassant 99% de précision, mais dans certains cas, il a même identifié les limites de l'évaluation elle-même en reconnaissant que la phrase semblait avoir été insérée artificiellement dans le texte original par un humain ». Parmi ses cas d'usage, Anthropic en cite 3 : automatisation des tâches (planification et exécution d'actions complexes à travers des API et des bases de données, codage interactif), R&D (examen de la recherche, brainstorming et génération d'hypothèses, découverte de médicaments), et stratégie (analyse avancée de tableaux et de graphiques, tendances financières et de marché, prévisions). Le coût pour la version Opus est de 15$ par million de token en entrée et 75 $ par million de token en sortie. La taille de la fenêtre de requête est de 200 000 tokens.
Commentaire