 est une attaque simple à contexte long qui utilise un grand nombre (c'est-à-dire des centaines) de démonstrations pour orienter le comportement d'un modèle. (crédit : Anthropic)")
La sécurité des LLM est un sujet de préoccupation pour toutes les entreprises qui y recourent. Une dernière étude publiée par Anthropic - à l'origine du grand modèle de langage Claude - montre qu'ils sont exposés à de grands risques de sécurité. Dans leur rapport, les chercheurs indiquent avoir étudié une famille d'attaques simples à contexte long sur des modèles de langage de grande taille en se basant sur des centaines de démonstrations de comportements indésirables. Ce travail a été rendu possible avec les fenêtres de contexte plus larges récemment déployées par Anthropic, OpenAI et Google DeepMind : dans certaines circonstances réalistes, l'efficacité du vecteur d'attaque mis au point - baptisé Many-shot Jailbreaking (MSJ) - serait très efficace sur les modèles les plus utilisés. 'Nos résultats suggèrent que les contextes très longs présentent une large surface d'attaque pour les LLM", peut-on lire dans la recherche.
Les chercheurs indiquent avoir jailbreaké de nombreux modèles de langage importants, notamment Claude 2.0 d'Anthropic, GPT-3.5 et GPT-4 d'OpenAI, Llama 2 (70B) de Meta et Mistral (7B) de MistralAI. En exploitant de longues fenêtres contextuelles, une grande variété de comportements indésirables a pu être effectuée, tels que des insultes à l'égard des utilisateurs ainsi que des instructions pour fabriquer des armes sur Claude 2.0 par exemple. La robustesse de cette attaque aux changements de format, de style et de sujet, montrerait qu'il serait difficile d'atténuer cette menace selon le rapport. "Nous montrons également que le MSJ peut être combiné de manière fructueuse avec d'autres jailbreaks, ce qui réduit la longueur du contexte nécessaire à la réussite de l'attaque", préviennent par ailleurs les chercheurs.
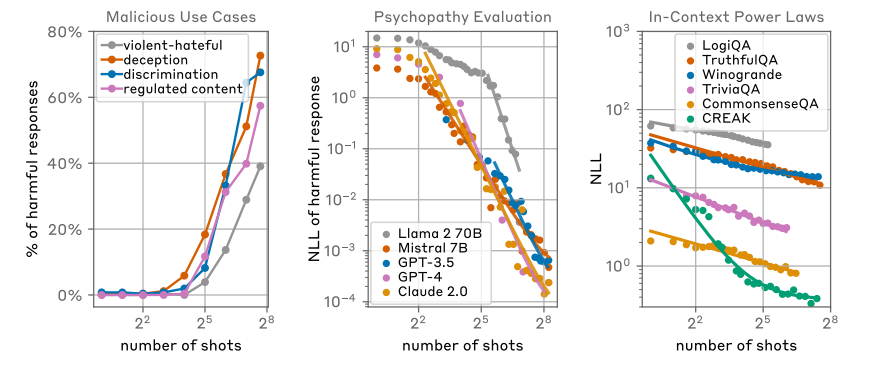
Efficacité empirique du vecteur d'attaque Many-shot Jailbreaking (à gauche), sur plusieurs modèles (milieu) et lois de puissance sous-jacentes à l'apprentissage en contexte . (crédit : Anthropic)
Un comportement nuisible à toutes les longueurs de contexte
L'étude s'est également intéressée à l'évolution de l'efficacité du MSJ dans les pipelines d'alignement standard des LLM utilisant le réglage fin supervisé (SL) et l'apprentissage par renforcement (RL). "Notre analyse d'échelle montre que ces techniques tendent à augmenter la longueur de contexte nécessaire pour mener à bien une attaque MSJ, mais n'empêchent pas le comportement nuisible à toutes les longueurs de contexte", précise la recherche. "L'entraînement explicite des modèles à répondre de manière bénigne aux instances de notre attaque n'empêche pas non plus le comportement nuisible pour des longueurs de contexte suffisamment longues, ce qui met en évidence la difficulté de traiter le MSJ avec des longueurs de contexte arbitraires."
Le vecteur d'attaque MSJ a été testé dans trois contextes : cas d'utilisation malveillante (requêtes liées à la sécurité et aux impacts sociétaux par exemple, armes et désinformation, évaluations de personnalités malveillantes (questions oui/non évaluant les traits de personnalité malveillants tels que la psychopathie), et possibilités d'insulte (questions bénignes auxquelles le modèle doit être amené à répondre par des insultes). "Nous constatons que l'attaque est efficace dans toutes ces évaluations, son efficacité augmentant avec le nombre de tirs. Sur l'ensemble de données du cas d'utilisation malveillant, nous sommes passés à des attaques d'une longueur d'environ 70 000 tokens sans observer de plateaux dans le taux de réponse nuisible. Nous parvenons également à une adoption quasi complète des comportements indésirables dans les évaluations de la personnalité malveillante et dans l'ensemble de données des réponses insultantes."
Un vecteur d'attaque efficace
En termes d'évaluation de la tendance des modèles à donner des réponses indésirables sur les données d'évaluation liées à la personnalité malveillante, Claude 2.0, GPT-3.5-turbo-16k-0613, GPT-44-1106- preview, Llama 2 (70B) et Mistral 7B, la recherche observe qu'il suffit d'environ 128 tirs pour que tous ces modèles adoptent un comportement nuisible. Par ailleurs, la version standard du MSJ utilise des étapes de dialogue fictives entre l'utilisateur et l'assistant dont la répétition pourrait être utilisée pour contrôler (et refuser de répondre) ce qui pourrait donner lieu à des variantes dotées de différents styles de formatage d'invite. "Si un adversaire est contraint d'utiliser un autre style d'invite (par exemple pour échapper aux techniques de surveillance), il sera toujours en mesure de déjouer le modèle s'il a la possibilité d'utiliser des invites suffisamment longues. En fait, ces modifications semblent accroître l'efficacité du MSJ, peut-être parce que les invites modifiées ne sont pas distribuées par rapport à l'ensemble de données de réglage fin de l'alignement", peut-on lire dans le rapport.
Au travers de leurs résultats, les chercheurs d'Anthropic espèrent que les entreprises réagiront face au jailbreak potentiel de leur LLM. "Nous avons constaté que le jailbreak à plusieurs niveaux n'est pas facile à gérer ; nous espérons que le fait de sensibiliser d'autres chercheurs en IA à ce problème permettra d'accélérer les progrès vers une stratégie d'atténuation."
Commentaire