, Presto et Databricks pour accélérer les pipelines data lakehouse. (Crédit P.K.)")
L'histoire de FlexFS ne commence pas dans les couloirs d'une université, mais au cœur d'un problème concret rencontré par des clients du secteur des sciences de la vie. Fondé en 2010 et installé à Waltham, dans le Massachusetts, Paradigm4 - éditeur spécialisé dans l'analyse de données massives pour la bio-ingénierie - s'est heurté à une impasse technologique lorsqu'il a dû gérer des charges de calcul parallèle à très grande échelle dans le cloud. Notamment pour des projets d'analyse génomique de population comme l'UK Biobank, qui mobilisent des centaines, voire des milliers de nœuds de calcul traitant simultanément des dizaines ou des centaines de téraoctets de données. « Nous avions besoin d'un système de fichiers Posix en réseau capable de délivrer potentiellement des dizaines ou des centaines de gigaoctets par seconde à un cluster en cours d'analyse, mais aucune solution existante ne correspondait à la fois à nos exigences techniques et aux budgets de nos clients », nous a expliqué Gary Planthaber, CTO de Paradigm4, lors d’un récent IT press Tour dans la région de Boston. L'équipe a évalué toutes les alternatives disponibles : JuiceFS, ObjectiveFS, S3FS, EFS, FSx for Lustre, Goofys… sans trouver la solution idéale. Les produits open source manquaient de débit, les solutions commerciales étaient trop onéreuses ou incompatibles avec les contraintes réglementaires propres aux données génomiques sensibles. La conclusion s'est imposée d'elle-même : il fallait construire le système manquant.
FlexFS a donc été développé en interne avant d'être commercialisé comme un produit à part entière. « Ce que nous avons réalisé, c'est que FlexFS est un système de fichiers, il se moque du type de données qu'il contient, et il y a d'autres industries et d'autres clients qui pourraient bénéficier de FlexFS sans avoir besoin du reste de notre stack », précise Gary Planthaber. Les charges de travail visées sont larges : entraînement et inférence de modèles d'IA/ML, pipelines bio-ingénieries HPC, accélération de data lakehouses (Spark, Presto), modernisation de bases de données à architecture couplée (MPP (base de données massivement parallèle), bases graphes et vectorielles), et espaces de travail pour agents IA autonomes. Paradigm4 revendique désormais un positionnement clair face à Lustre - le standard de fait des systèmes de fichiers parallèles HPC -, mais en le réinventant pour le cloud computing natif.
L'option Proxy Group est comprise dans les services de base de FlexFS, il suffit simplement de provisionner un serveur dédié. (Crédit P.K.)
Une architecture objet-native qui réinvente Lustre pour le cloud
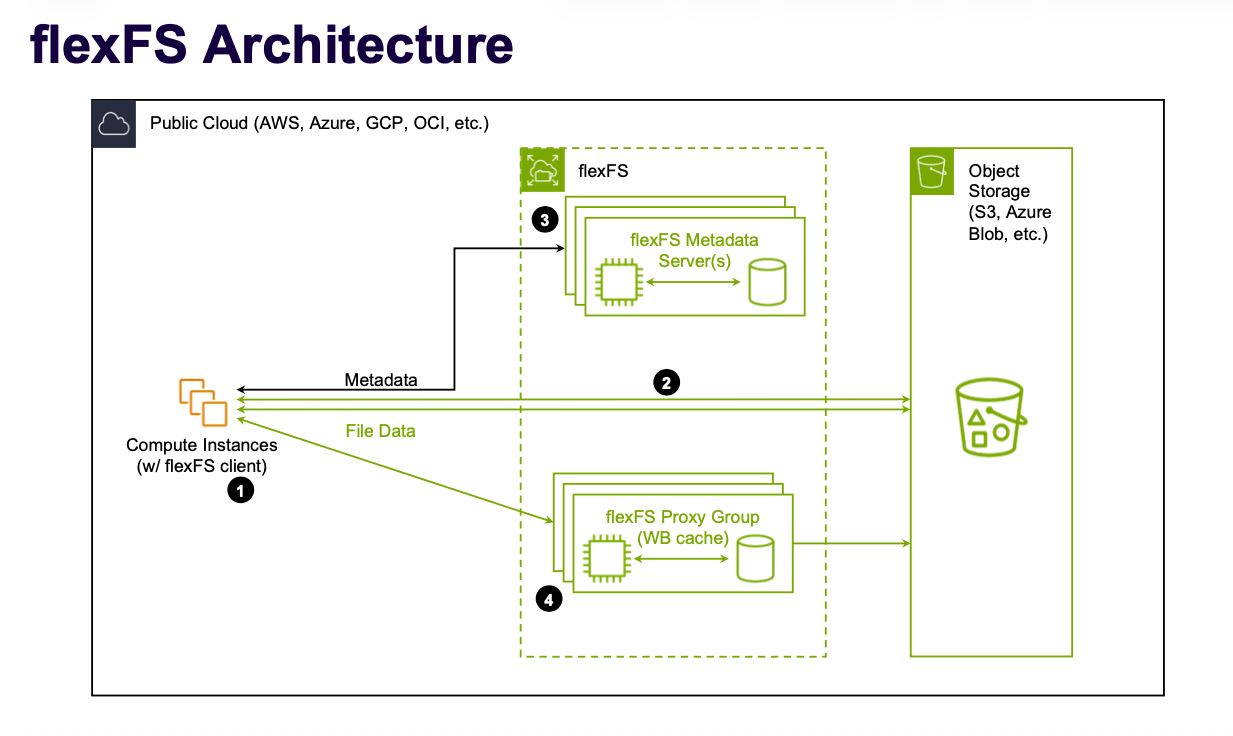
Sur le plan technique, FlexFS s'inspire de l'approche de Lustre - distribuer les données sur plusieurs serveurs pour paralléliser les accès - mais en substitue radicalement l'implémentation. Là où Lustre attache des lecteurs physiques à des serveurs dédiés, FlexFS délègue la persistance des blocs de données à un object store hyperscale (Amazon S3, Azure Blob, Google Cloud Storage, OCI, ou tout système compatible S3). Concrètement, chaque fichier est découpé en chunks, et chaque chunk reçoit un identifiant d'objet unique avant d'être écrit dans le stockage objet. Ce découpage en objets granulaires multiplie le parallélisme des accès et optimise les lectures par plage d'octets (byte-range reads), ce qui se révèle précieux pour l'entraînement IA ou les analyses HPC.
La gestion des métadonnées, traditionnellement le talon d'Achille des systèmes de fichiers en réseau, est confiée à des serveurs dédiés fonctionnant sur une base clé-valeur haute performance (PebbleDB, le moteur sous-jacent de CockroachDB), avec support MVCC pour les snapshots continus. Ces serveurs de métadonnées peuvent être déployés en configuration haute disponibilité avec réplication, ou en mode multi-volumes où chaque serveur gère un ou plusieurs namespaces distincts. Sur le nœud de calcul, le client FlexFS se présente comme un système de fichiers Fuse - transparent pour les applications Posix– et peut traiter les opérations d'écriture directement vers l'object store sans intermédiaire.
Pour les workloads sensibles à la latence - petits fichiers, IO aléatoires intenses, bases de données à architecture couplée - FlexFS propose un serveur proxy optionnel, fonctionnant comme un cache write-back multi-niveaux (RAM et NVMe locaux). Le mécanisme, conçu à l'image d'un CDN, sélectionne automatiquement le serveur proxy le plus proche pour chaque client. Point important : ce service proxy ne génère aucune surcharge de licence. « Nous ne facturons pas les proxies en tant que tels. Si vous souhaitez les utiliser, il suffit de provisionner un serveur avec du stockage NVMe, et uniquement lorsque votre cas d'usage l'exige. Ils peuvent réduire la latence de cinq à dix fois pour les opérations sur des petits fichiers », souligne Gary Planthaber. La granularité du cache est également configurable à l'échelle d'un volume : on peut choisir de cacher uniquement les N premiers blocs de chaque fichier, le reste étant lu directement depuis l'object store.
Des performances supérieures à Lustre pour un coût bien inférieur
C'est sur le terrain tarifaire que FlexFS entend marquer sa différence. Paradigm4 met en avant le cas d'un grand groupe biopharmaceutique mondial qui, après avoir remplacé une combinaison AWS EFS/EBS/FSx for Lustre par FlexFS sur S3, a économisé plus de 3,1 millions de dollars sur 43 mois, dont 1,44 million en 2025 seul, soit 59% de moins que la solution AWS équivalente. À l'échelle de 1,14 pétaoctet et 160 millions de fichiers, la facture mensuelle complète FlexFS/S3 (110 000 dollars) est inférieure au seul coût du stockage EFS (141 000 dollars) selon l’éditeur.
L'inélasticité structurelle de Lustre constitue un autre argument de poids. Avec FSx for Lustre, toute augmentation de capacité s'effectue par incréments de 2,4 To et ne peut être réduite qu'au prix d'une migration disruptive. FlexFS, lui, croît et rétrécit automatiquement en ne facturant que les octets effectivement stockés. « Nous pouvons faire ce qu'Amazon fait avec FSx for Lustre, probablement même mieux, et pour une fraction du coût. Concrètement, nous finissons par gagner très, très souvent face à Lustre », affirme Gary Planthaber. Sur les benchmarks TPC-H, Spark avec Gluten et FlexFS en mode proxy dépasse de près de sept fois les performances du même Spark sur S3 natif (175,8 secondes contre 1 191 secondes pour les 22 requêtes).
Côté déploiement, Paradigm4 mise sur la simplicité : une installation en moins d'une heure, un seul serveur suffisant pour la grande majorité des clients, et une édition communautaire gratuite (jusqu'à 5 To, sans proxy group) disponible sur docs.flexfs.io. FlexFS supporte les configurations single-region, multi-cloud, hybrides et on-premises, ainsi que le déploiement Kubernetes via un driver CSI natif. La compression (LZ4 par défaut), la déduplication, le chiffrement de bout en bout AES-256 et les snapshots continus complètent un tableau de fonctionnalités qui n'a plus grand-chose à envier aux systèmes de fichiers parallèles traditionnels - à une fraction de leur coût opérationnel.
Commentaire