")
Le géant de la recherche Google a déclaré aujourd'hui qu'il avait ouvert l'accès à Bard, un chatbot d'IA générative destiné à concurrencer les services similaires proposés par Microsoft et OpenAI, entre autres. Bard, comme d'autres chatbots avancés similaires, est alimenté par un grand modèle de langage. Les LLM sont essentiellement des algorithmes avancés d'apprentissage en profondeur, dotés d'une gamme de capacités comprenant la traduction, le résumé et plus encore, alimentés par d'énormes quantités de texte. Le LLM utilisé par Bard est une variante légère de LaMDA, le principal modèle de traitement du langage naturel de Google. « Vous pouvez considérer un LLM comme un moteur de prédiction », explique Google dans un billet de blog. « Lorsqu'il reçoit une invite, il génère une réponse en sélectionnant, un mot à la fois, les mots qui sont susceptibles de venir ensuite ».
L'entreprise précise que Bard est un peu plus flexible que cela, car sélectionner à chaque fois le mot « le plus probable » pour une réponse donnée conduirait à des réponses statiques et peu créatives. Mais Google a également précisé que le modèle devrait apprendre et devenir plus précis au fil de son utilisation. À l'avenir, la firme va travailler sur des dimensions supplémentaires de la mesure des réponses, telles que l'intérêt et l'amélioration en continu de l'exactitude factuelle des réponses. Ce dernier point est un problème sérieux pour la dernière génération d'assistants d'IA générative, étant donné que l'ensemble des données sous-jacentes qui lui permettent de prendre des décisions sur ce qu'il faut dire est si vaste qu'il contient beaucoup d'informations incorrectes ou biaisées.
Les modèles d'apprentissage automatique sont biaisés
« Nous connaissons très bien les problèmes liés aux modèles d'apprentissage automatique, tels que les biais injustes, car nous étudions et développons ces technologies depuis de nombreuses années », peut-on lire dans le billet de blog. « C'est la raison pour laquelle nous créons et mettons à la disposition des chercheurs des ressources libres qu'ils peuvent utiliser pour analyser les modèles et les données sur lesquelles ils sont formés ; c'est aussi la raison pour laquelle nous avons examiné minutieusement LaMDA à chaque étape de son développement et c'est aussi la raison pour laquelle nous continuerons à le faire alors que nous nous efforçons d'incorporer des capacités conversationnelles dans un plus grand nombre de nos produits ».
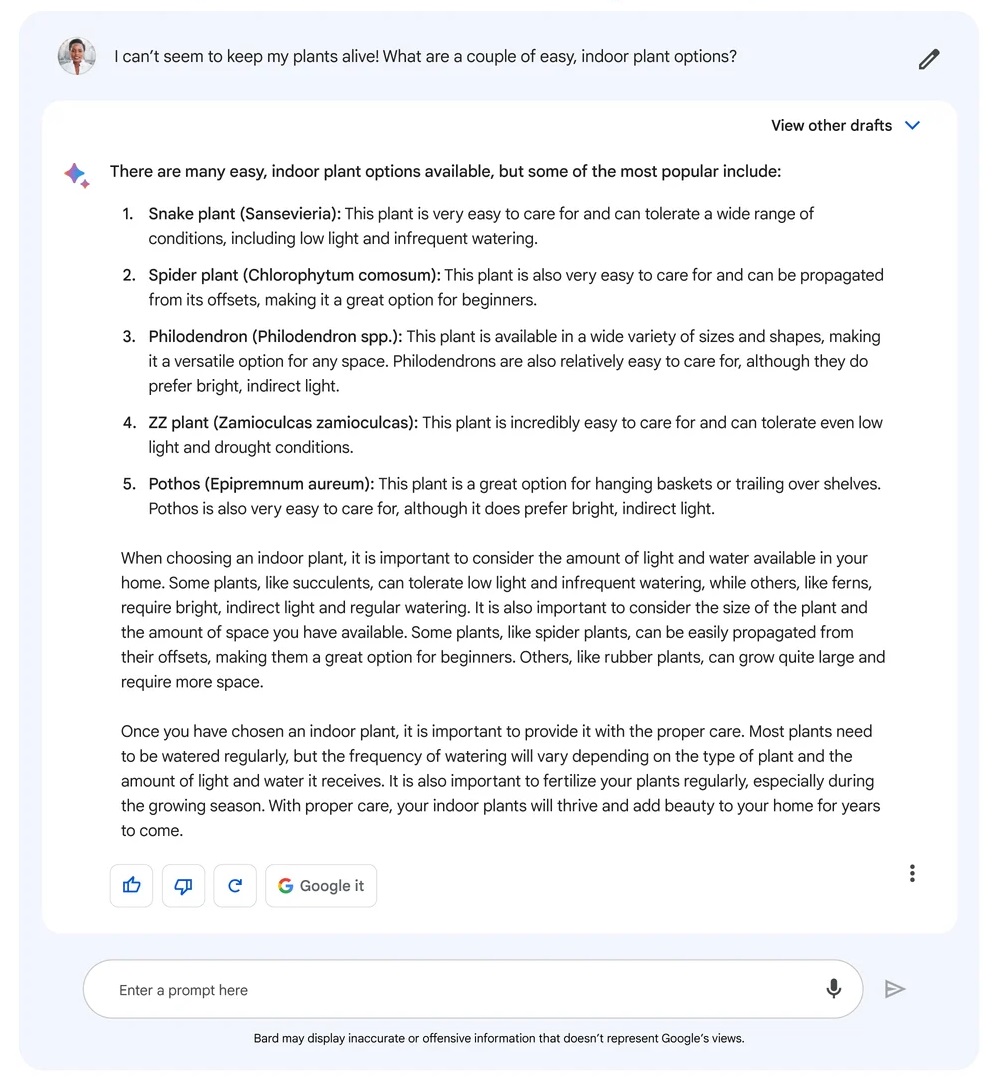
Dans cette réponse, Bard s'est trompé sur certains points, comme le nom scientifique de la plante ZZ - en fait Zamioculcas zamiifolia, et non Zamioculcas zamioculcas. (Crédit : Google)
Les difficultés de Bard en matière de précision ne sont pas uniques, mais elles ont été largement médiatisées - une des premières publicités pour le chatbot le montrait donnant une réponse manifestement incorrecte à une question sur l'observation d'exoplanètes. Il n'a pas encore connu les problèmes les plus étranges auxquels d'autres chatbots ont été confrontés. En février, un modèle de Microsoft a ainsi exprimé son amour pour un chroniqueur du New York Times et lui a dit qu'il devrait quitter sa femme.
Les inscriptions pour l'accès à Bard sont ouvertes aux États-Unis et au Royaume-Uni, mais il y a actuellement une liste d'attente.
Commentaire