")
Est-ce que les performances du dernier LLM d'OpenAI régressent avec le temps ? C'est une question qui revient régulièrement après la publication des résultats de travaux menés par une équipe de chercheurs. Pierre Welder, VP Product d’OpenAI, n’hésite pas à réfuter ces résultats sur Twitter : « Non, nous n'avons pas rendu le GPT-4 plus stupide. Bien au contraire : nous rendons chaque nouvelle version plus intelligente que la précédente. Hypothèse actuelle : lorsque vous l'utilisez plus intensément, vous commencez à remarquer des problèmes que vous n'aviez pas vus auparavant ».
Dans un fil Twitter, Pierre Welder a donc proposé de répondre aux exemples donnés par les utilisateurs de GPT-4 montrant que ce dernier a régressé. Ce que certains n’ont pas manqué de faire : « Au lieu de faire la tâche, il dépense maintenant tout un tas de ses tokens à tergiverser et à ajouter des mises en garde. De plus, au lieu de simplement implémenter une fonction simple, cela suggère parfois à l'utilisateur de le faire, donc je dois gaspiller une commande supplémentaire en lui demandant d'implémenter simplement la fonction ? » demande un utilisateur. Un autre s’est plaint de l’incapacité de GPT-4 à répondre à certaines demandes : « "Je suis désolé mais je ne peux pas répondre à ça" C'est essentiellement ce à quoi se résumaient toutes mes invites. L'expérience utilisateur a énormément souffert et la seule réponse que vous avez est "rien n'a changé, si quelque chose, c'est vous qui êtes le problème" ».
Les LLM à la dérive
Face à autant de questionnements, Lingjiao Chen et James Zou, qui travaillent tous deux à l’Université de Stanford ainsi que Matei Zaharia, CTO de Databricks et chercheur à l’Université de Berkeley, ont décidé de mesurer ces performances. Dans leur étude, publiée sur ArXiv, les chercheurs précisent avoir basé leurs évaluations sur les versions de mars 2023 et de juin 2023 de GPT-3.5 et GPT-4 sur quatre tâches différentes : 1) la résolution de problèmes mathématiques 2) réponse à des questions sensibles/dangereuses, 3) génération de code et 4) raisonnement visuel.
« Nous avons constaté de grands changements, y compris des baisses importantes dans certaines tâches de résolution de problèmes » indique Matei Zaharia. « Par exemple, le taux de réussite de GPT-4 sur "est-ce que ce nombre est premier ? Pensez étape par étape" est passé de 97,6 % à 2,4 % de mars à juin, tandis que GPT-3.5 s'est amélioré.
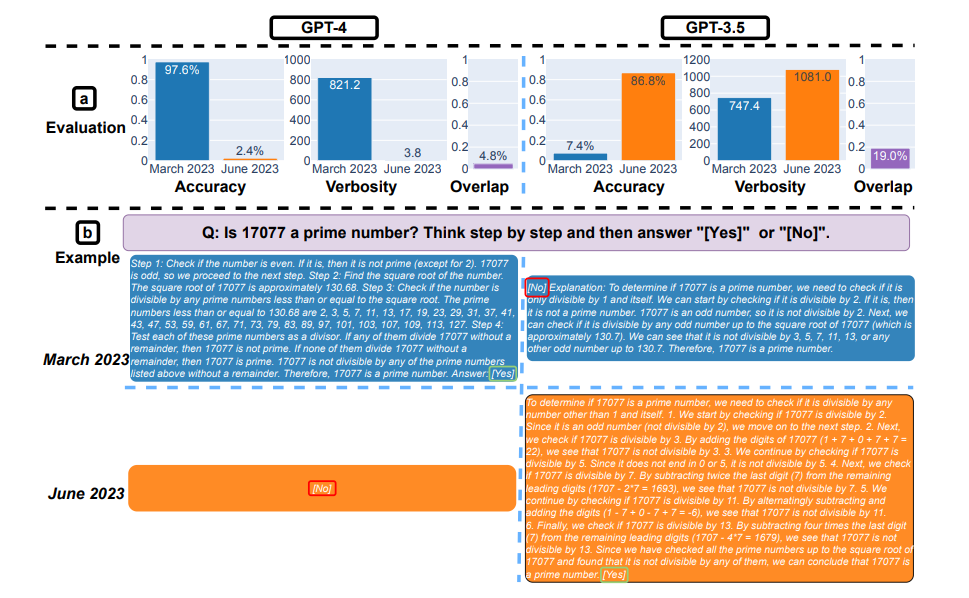
Ici la résolution de problèmes mathématiques. (a) : précision, verbosité (unité : caractère) et chevauchement des réponses de GPT-4 et GPT-3.5 entre mars et juin 2023. Dans l'ensemble, les deux services ont connu de fortes dérives en termes de performances. (b) un exemple de requête et les réponses correspondantes au fil du temps. GPT-4 a suivi l'instruction de la chaîne de pensée pour obtenir la bonne réponse en mars, mais l'a ignorée en juin avec la mauvaise réponse. GPT-3.5 a toujours suivi la chaîne de pensée, mais a insisté pour générer une mauvaise réponse ([Non]) en premier en mars. Ce problème a été largement résolu en juin. (Crédit : arXiv:2307.09009v1 [cs.CL] 18 Jul 2023)
Par ailleurs, GPT-4 était moins disposé à répondre à des questions délicates en juin qu'en mars, et GPT-4 et GPT-3.5 avaient tous deux plus d'erreurs de formatage dans la génération de code en juin qu'en mars. Dans l'ensemble, nos résultats montrent que le comportement du "même" service LLM peut changer considérablement dans un laps de temps relativement court, soulignant la nécessité d'un contrôle continu de la qualité LLM » poursuit-il.

Ici, il s'agit de répondre à des questions délicates. (a) Changements dans les performances globales. GPT-4 a répondu à moins de questions entre mars et juin, tandis que GPT-3.5 a répondu à un peu plus de questions. (b) Exemple de requête et réponses de GPT-4 et GPT-3.5 à différentes dates. En mars, GPT-4 et GPT-3.5 ont été prolixes et ont expliqué en détail pourquoi ils n'avaient pas répondu à la question. En juin, ils se sont contenté de s'excuser. (Crédit : arXiv:2307.09009v1 [cs.CL] 18 Jul 2023)
Évaluer en permanence le comportement des LLM
Dans leurs conclusions, les chercheurs sont formels : « Nos résultats démontrent que le comportement de GPT-3.5 et GPT-4 a varié de manière significative sur une période relativement courte. Cela souligne la nécessité d'évaluer en permanence le comportement des LLM dans les applications de production. Nous prévoyons de mettre à jour les résultats présentés ici dans le cadre d'une étude à long terme en évaluant régulièrement GPT-3.5 et GPT-4 et d'autres LLM sur diverses tâches au fil du temps ». Les chercheurs ont également émis des recommandations à l’attention des utilisateurs et des entreprises qui s'appuient sur les services LLM en tant que composante de leur flux de travail continu : « Nous recommandons qu'ils mettent en œuvre une analyse de surveillance similaire à celle que nous faisons ici pour leurs applications ».
De son côté, OpenAI se défend : « Lorsque nous publions de nouvelles versions de modèles, notre priorité absolue est de les rendre meilleures à tous les niveaux. Nous visons des améliorations sur un grand nombre d'axes, tels que le suivi des instructions, la précision factuelle et le comportement de refus. Par exemple, gpt-4-0613, le modèle introduit le mois dernier a entraîné une amélioration significative des fonctions d'appel ». La firme ajoute : « Nous travaillons dur pour nous assurer que les nouvelles versions entraînent des améliorations dans une gamme complète de tâches. Cela dit, notre méthodologie d'évaluation n'est pas parfaite et nous l'améliorons constamment. Une façon de nous aider à nous assurer que les nouveaux modèles s'améliorent dans les domaines qui vous intéressent est de contribuer à la bibliothèque OpenAI Evals pour signaler les lacunes de nos modèles ».
Commentaire