")
La guerre entre Databricks et Snowflake ne cesse pas et c’est sur le domaine des catalogues de données que la bataille s'est déplacée. A l’occasion de son évènement annuel aux Etats-Unis (du 3 au 6 juin), le spécialiste du datawarehouse cloud a dévoilé son catalogue de données baptisé Polaris Catalog. Concurrent direct d’Unity Catalog de Databricks, il mise sur deux différences : il est open source et centralise les tables Apache Iceberg.
Une ouverture astucieuse vers les tables Iceberg
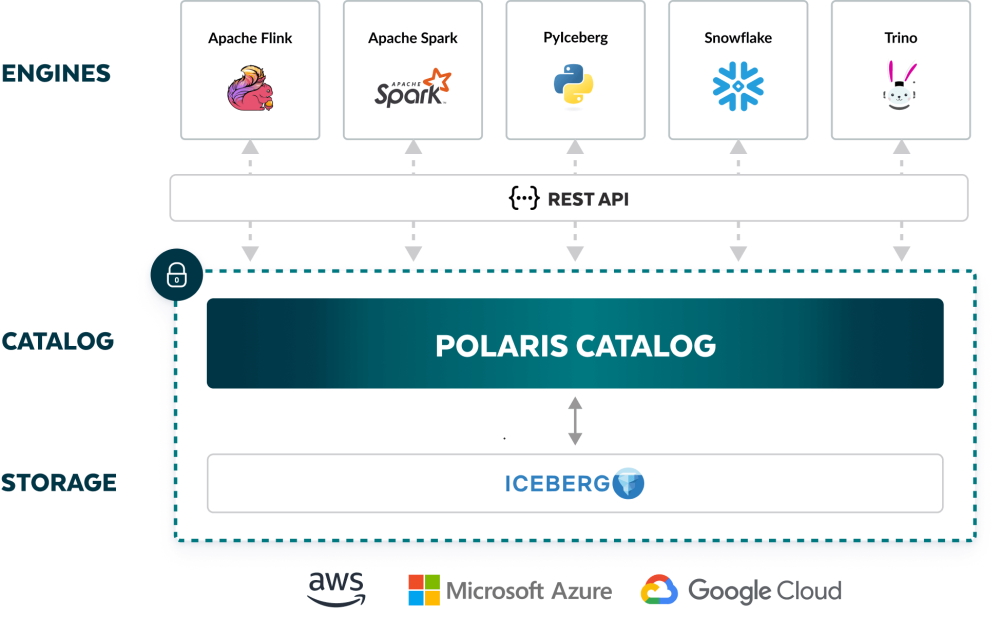
Pour mémoire, Unity Catalog date de juin 2022 et a été actualisé avec l’acquisition d’Okera en 2023. Il se définit comme une offre de gouvernance des données fournissant des capacités de contrôle d’accès, d’audit, de catalogage et de recherche des données à travers les workspace de Databricks. Polaris Catalog reprend les mêmes fonctionnalités avec l’ajout du support des tables Iceberg. « « Avec Polaris Catalog, les utilisateurs disposent désormais d'un lieu unique et centralisé où n'importe quel moteur peut trouver et accéder aux tables Iceberg d'une entreprise avec une sécurité cohérente et une interopérabilité complète et ouverte », a déclaré la société dans un communiqué. L’offre s'appuie sur l’API Rest d’Iceberg capable d’accéder et de récupérer des données depuis n’importe quel moteur y compris Apache Flink, Apache Spark, Dremio, Python et Trino, entre autres.
Snowflake détaille les partenariats et les compatibilités avec Polaris Catalog. (Crédit Photo: Snowflake)
A noter que la bascule en open source est prévue dans les 3 prochains mois assure la société. Polaris Catalog peut être hébergé dans le AI Data Cloud de Snowflake (en preview pour l’instant) ou sur site en utilisant des conteneurs comme Docker ou des environnements Kubernetes. « Étant donné que l'implémentation du backend de Polaris Catalog sera open source, les entreprises peuvent librement basculer dans une autre infrastructure d'hébergement en conservant tous les contrôles de sécurité et en évitant le verrouillage du fournisseur », a déclaré l’entreprise.
Des analystes critiques
Selon les analystes, Polaris Catalog est effectivement une réponse pour « attirer un éventail de clients plus large et favoriser une communauté dynamique autour de lui », constate Jayesh Chaurasia, analyste chez Forrester Research. Il ajoute, « la complexité et la diversité des systèmes de données, associées au désir universel des entreprises d'exploiter l'IA, nécessitent l’usage d'un catalogue de données interopérable, qui sera probablement de nature open source ». Ce caractère open source est essentiel, car « il facilite la gestion des données sur différentes plateformes et dans les environnements cloud ».
D’autres consultants sont plus critiques comme Steven Dickens, vice-président de la recherche de Futurum Group qui estime que ce lancement est une tentative « désespérée » pour s’attirer la « bienveillance » des clients et de la communauté open source. Il pense que cette conversion à l’open source résulte des lacunes et des limites de Snowflake, notamment la faible interopérabilité, le verrouillage des fournisseurs, les coûts exorbitants, le manque d’innovation et la dépendance à l’égard des partenaires. « Snowflake est notoirement cher, et sa structure de coûts a poussé de nombreux clients à chercher des alternatives. Polaris Catalog peut être considéré comme un ultime effort pour conserver les clients en offrant une alternative open source potentiellement moins chère », a expliqué le consultant.
D’autres rivaux open source
Jayesh Chaurasia et Steven Dickens font aussi remarquer que Polaris Catalog n'est pas le seul catalogue de données open source disponible sur le marché. Et de citer « Apache Atlas, Amundsen et le DataHub de LinkedIn. Chacun d'entre eux offre des capacités de découverte de données, de gouvernance et de gestion des métadonnées », a rappelé l’analyste de Forrester. Apache Atlas est conçu pour la gouvernance et la conformité dans les environnements Apache Hadoop, offrant des capacités évolutives de gestion des métadonnées, de lignage et de gouvernance pour Hadoop et les technologies big data associées. De son côté, Amundsen, issu de Lyft, vise à améliorer la productivité des analystes de données, des scientifiques et des ingénieurs en indexant les ressources de données (métadonnées) et en facilitant la découverte et l'exploration des ensembles de données sur la base de l'utilisation et de la pertinence.
Enfin, DataHub de LinkedIn, dont l’architecture de métadonnées en temps réel prend en charge divers systèmes et environnements de données grâce à une intégration enfichable, offre également une autre alternative. « Le DataHub se concentre sur l'ingestion des métadonnées, l'indexation, la découverte des données et la gouvernance », a déclaré Jayesh Chaurasia, ajoutant qu'Amundsen et DataHub sont devenus populaires parce qu'ils mettent l'accent sur l'expérience utilisateur, la prise en charge de multiples intégrations (à la fois en temps réel et par lots) et les capacités de découverte des données, sous l’effet d’une demande d'offres de gestion de données efficaces.
Commentaire