")
« La 3e vague du stockage commence avec la parallélisation arrivée avec le NVMe », nous a expliqué sans détour Gurpreet Singh, CEO de la start-up Pavillon Data Systems, fondée en 2014 et installée à San Francisco. « Quand le 10 GbE est arrivée, certains ont demandé à quoi ça pourrait servir et aujourd’hui ce n’est plus suffisant. Nous voulons être sûrs que ce que nous proposons va au-delà des attentes des clients ». Justement dans le domaine du stockage flash, Pavilion dépasse la configuration habituelle avec deux contrôleurs sur ses baies NVMe-over-Fabrics (iSCSI, ROCE, RDMA ou TCP). Nous avons construit une plateforme share performance memory avec jusqu’à 20 contrôleurs indépendants par baie 4U avec le support des modes fichier, bloc ou objet.
La partition au niveau du système permet aux contrôleurs animés par PavilionOS de travailler ensemble ou de manière indépendante pour résoudre un problème particulier comme reconstruire plus rapidement un volume Raid », a précisé le CEO. Chaque contrôleur est défini de manière dynamique comme un contrôleur d'accès aux blocs, aux fichiers ou aux objets, et un second contrôleur agit comme une sauvegarde de secours. Le contrôle plane s’effectue avec une approche API first. Précisons que le support du stockage objet passe par un serveur Minio, comme chez beaucoup d’autres fournisseurs (Qumulo par exemple).
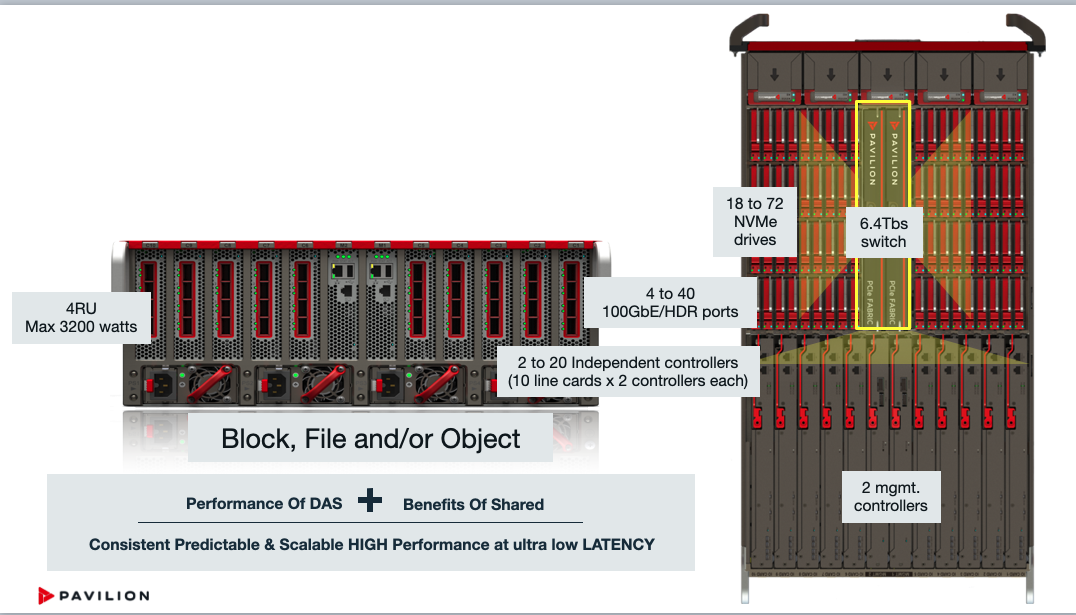
La baie Pavillon Data prend en charge l'accès aux données en mode bloc, objet et fichier (NFS).
Jusqu'à 20 millions d’IOPS en lecture aléatoire
Le Hyperparallel Flash Array (HFA) de la start-up offre, selon le dirigeant, des performances et une capacité inégalées grâce au NVMe-over-Fabrics. Reposant sur des SSD NVMe au format M.2 et une mémoire partagée pour les métadonnées, Pavillon revendique des performances maximales de 20 millions d’IOPS en lecture aléatoire avec cinq millions d'écritures. Le débit revendiqué plafonne à 120 Go / s en et 90 Go / s en écritures tandis que la latence tombe à 100 µs en lecture et 25 µs en écriture pour servir des cas d’usage comme ceux le HPC scientifique et commercial, ou des traitements analytiques avec Splunk, Hadoop et d’autres gros consommateurs de données, qui adoptent le stockage d'objets S3 comme standard pour les charges de travail de nouvelle génération.
La proposition est de proposer des performances importantes en mode bloc, fichier, mais également objet. C’est particulièrement intéressant pour les entreprises qui désirent que leur stockage objet soit proche de l'endroit où il est traité avec des process analytiques et IA/ML. « Le FC/SAN a changé l’industrie du stockage comme le NVMe-oF le fait aujourd’hui. L’association de la faible latence et des hautes performances sont très recherchées aujourd’hui », note Casta Hasapopoulos, CFO de Pavilon Data.
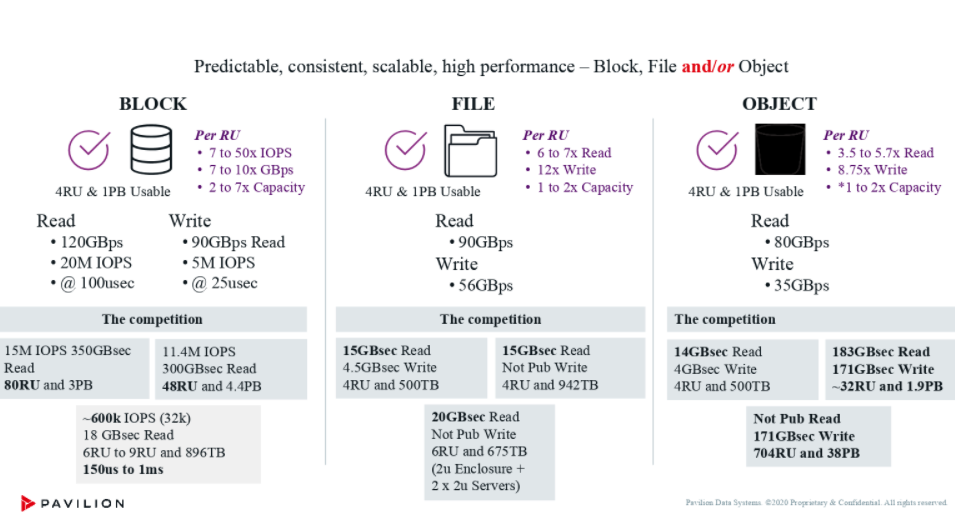
Pavilion Data ne cite pas nommément ses concurrents mais on retrouve, dans l'ordre de gauche à droite : Dell-EMC, NetApp et Pure Storage. Ces chiffres sont toujours à considérer avec la plus grande prudence quand les conditions de tests et de matériels ne sont pas connues.
Pavilion Data emploie près de 80 personnes dans le monde et propose ses solutions en Europe via des partenariats. En UK et Benelux seulement pour l’instant, il n’y a pas encore de revendeurs en France, mais des discussions sont en cours. Parmi les clients de la jeune pousse, on peut citer CBS aux États-Unis et une banque en Grande-Bretagne.
Commentaire