")
Les coûts du cloud et en particulier du stockage sont régulièrement mis en avant par les DSI comme frein au développement du cloud. De temps en temps, des problèmes de configuration font même exploser les factures. C’est la mésaventure qui est arrivée à Maciej Pocwierz, développeur chez un éditeur polonais et qu’il a raconté dans un article sur Medium. Il explique avoir réalisé un PoC d’indexation de documents pour un client en créant un bucket S3 (stockage en mode objet) unique dans la région eu-west-1 et y télécharger quelques fichiers à des fins de test.
Deux jours après le début de son prototype, il constate sur la page de facturation de son compte affiche une note de « 1 300 dollars HT pour un usage de 100 000 000 de requêtes S3 PUT exécutées en l'espace d'une seule journée ! ». Un dérapage incompréhensible pour le développeur qui avait choisi un plan tarifaire gratuit pour ces tests. Il a donc creusé pour savoir les raisons de ce débordement.
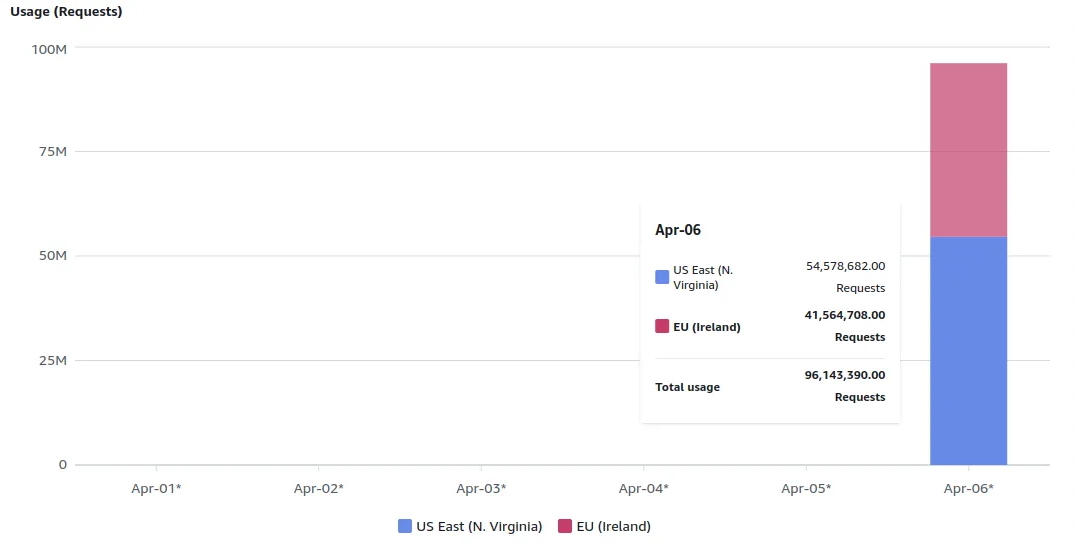
La facture du développeur a complètement dérapé. (Crédit Photo : DR)
Un homographe fâcheux
En passant par les outils du fournisseur CloudTrail et S3 Server Access Logging, il a observé des milliers de requêtes provenant de plusieurs comptes ou entièrement en dehors d'AWS. Au début, il penchait pour une attaque en déni de service, mais après approfondissement de son enquête il a trouvé l’origine du problème. « Il s'avère que l'un des outils open source les plus populaires avait une configuration par défaut pour stocker ses sauvegardes dans S3. Et, en guise de nom de bucket, ils utilisaient... le même nom que celui que j'avais utilisé pour mon bucket ».
Le développeur n’a pas voulu vendre la mèche sur le nom de l’outil open source estimant que cela pouvait entraîner des risques de sécurité comme des fuites de données. Il a averti l’éditeur en question de sa découverte. Par contre, il a fait remonter l’information auprès d’AWS qui a effacé son ardoise et il évoque quelques pistes d’amélioration comme l’ajout de caractères aléatoires au nom des buckets S3.
Le Bucket était public ?
Signaler un abusL'outil Open Source peut faire des requêtes PUT sur un Bucket sans autorisation ?
Bah, c'est surtout que c'est une idiotie complète de se baser sur des noms fournis par l'utilisateur pour de la gestion d'entrées dans une CMDB, je n'ose imaginer les débordements...
Signaler un abusAmazon va bientôt découvrir le principe des "id" ;) pour bien ranger ses données.