
Databricks est la première entreprise à rendre Apache Spark 2.0 généralement disponible sur sa plate-forme de données. Initiée dans l’AMPLab de l’Université de Californie à Berkeley par l'équipe qui a créé Spark Apache, l’entreprise explique que cette dernière version est le résultat des expériences vécues par la communauté au cours des deux dernières années. C’est aussi la première version majeure depuis la sortie de la version open source Spark 1.6 en 2015. « Depuis la sortie de Spark 1.0, nous avons passé d'innombrables heures à écouter les membres de la communauté Spark et les utilisateurs de Databricks pour faire le point sur ce qui était bien et sur ce qu’il fallait améliorer », a déclaré mardi dans un communiqué Reynold Xin, architecte en chef et co-fondateur de Databricks. « Spark 2.0 est la résultante de tout ce que la communauté a appris, de ce que les utilisateurs aiment et de ce qu’ils voulaient voir évoluer », a-t-il ajouté.
Une vraie alternative à MapReduce
Spark, un projet Apache de niveau supérieur, est devenu de plus en plus populaire. Ce moteur de calcul alternatif à MapReduce est utilisé pour alimenter les applications big data. Sa façon d’exploiter les primitives en mémoire lui permet de dépasser les performances de MapReduce sur certaines applications. Il est bien adapté aux algorithmes d’apprentissage machine et aux analyses interactives. L’entreprise qui avait lancé une version préliminaire de Apache Spark 2.0 sur Databricks il y a deux mois, a précisé que 10 % des clusters de sa plate-forme utilisaient déjà la dernière version de Spark.
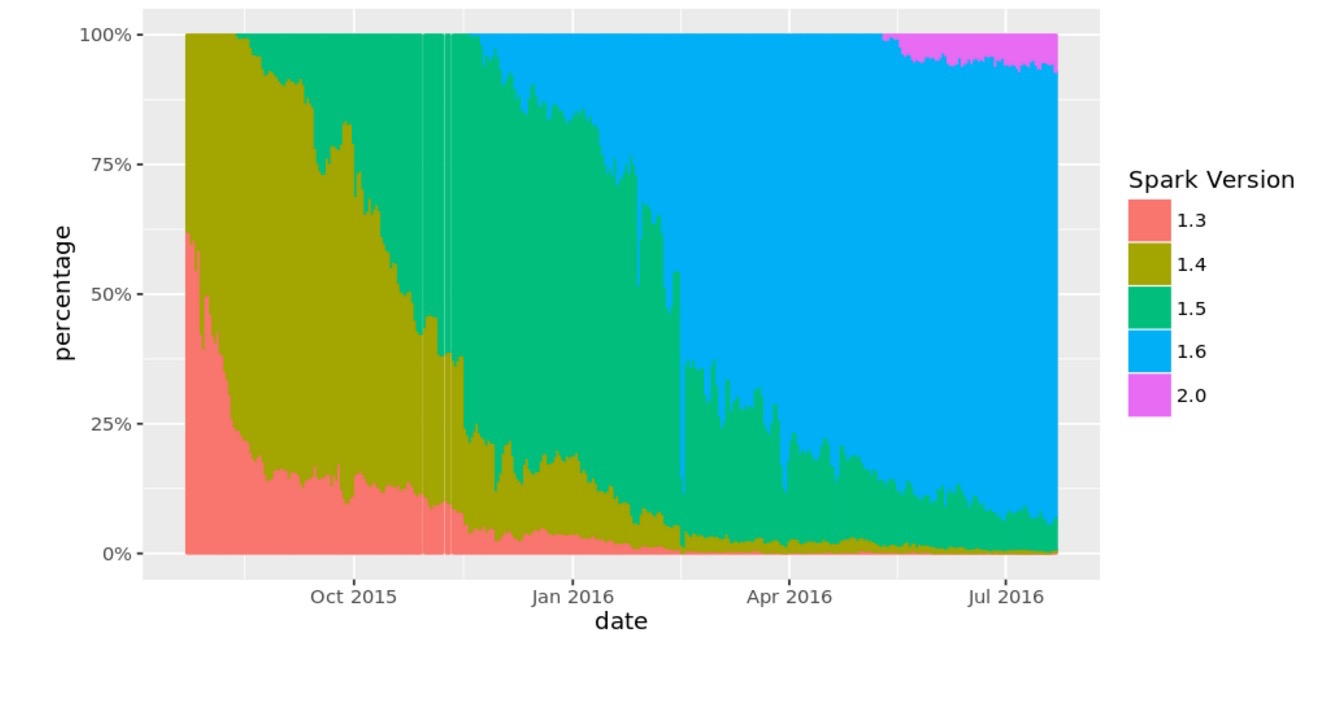
|
Alors que Spark 2.0 vient d'arriver, c'est toujours la version 1.6 du framework alternatif pour Hadoop qui est la plus utilisée pour le data mining. |
Voici les principales nouveautés mises en avant par Databricks :
La vitesse. Selon Databricks, Spark 2.0 est cinq à dix fois plus rapide que Spark 1.6 pour certaines opérations grâce aux capacités de génération de code Whole-Stage-Code du Projet Tungsten Phase 2 et à l’optimisation de code Catalysts.
Simplicité. La nouvelle version unifie les API de développement à travers les bibliothèques Spark, y compris DataFrames et Datasets.
Le streaming structuré. Spark 2.0 jette les bases du support aux applications en continu (Continous Applications) grâce à des API de streaming déclaratif de haut niveau basées sur DataFrames et Datasets placées au-dessus de Spark SQL, lequel travaille avec des données en temps réel.
Un mode d'apprentissage machine persistant. La nouvelle version prend désormais en charge la sauvegarde et le chargement des pipelines et des modèles dans tous les langages de programmation pris en charge par Spark.
Des API d'apprentissage machine basées sur DataFrame. Selon Databricks, avec Spark 2.0, le pack spark.ml, et ses API « pipeline », vont s’imposer comme API d'apprentissage machine par excellence. La nouvelle version conserve le pack d’origine spark.mllib, mais Databricks dit qu’elle concentrera ses futurs efforts de développement sur l'API basée sur DataFrame.
Support du SQL standard. Spark 2.0 étend les capacités SQL de Spark aux fonctions de SQL2003. Il se dote d’un nouvel analyseur syntaxique SQL ANSI, prend en charge les sous-requêtes de type scalaire et prédicat.
Les modèles restent compatibles
« En tant que développeur de Spark Apache, il est très excitant de voir la rapidité avec laquelle les utilisateurs commencent à utiliser les nouvelles fonctionnalités et les nouvelles API, et avec laquelle, en retour, ils nous offrent un feeback presque instantané, de sorte que nous pouvons les améliorer », a déclaré mardi dans un communiqué Matei Zaharia, CTO et co-fondateur de Databricks et par ailleurs créateur de Spark Apache.
Spark 2.0 est immédiatement disponible pour les utilisateurs de Databricks. L’entreprise affirme qu’ils peuvent créer des clusters Spark 2.0 en sélectionnant la nouvelle version dans le menu Databricks. De plus, Databricks indique que Spark 2.0 est compatible avec Spark 1.6, ce qui signifie que la migration de code sera très facile.
Commentaire