")
Au cours des derniers mois, l’équipe Machine Learning Foundations de Microsoft Research a publié une suite de petits modèles de langage (small language models ou SLM) appelés Phi. Ces derniers atteignent des performances notables sur une variété de points de référence. Le premier modèle, le Phi-1 de 1,3 milliard de paramètres, a atteint des performances de pointe sur le codage Python parmi les SLM existants (en particulier sur les benchmarks HumanEval et MBPP). Par la suite, l’équipe de chercheur a ensuite étendu le champ d'action au raisonnement de bon sens et à la compréhension du langage et créé un autre modèle de 1,3 milliard de paramètres appelé Phi-1.5, dont les performances sont comparables à celles de modèles 5 fois plus grands, se targuent-ils.
Aujourd’hui, l’équipe a dévoilé Phi-2, un modèle de langage de 2,7 milliards de paramètres possédant des capacités que les chercheurs jugent « exceptionnelles de raisonnement et de compréhension du langage », le tout avec des performances de pointe parmi les modèles de langage de base de moins de 13 milliards de paramètres. « Sur des benchmarks complexes, Phi-2 égale ou surpasse des modèles jusqu'à 25 fois plus grands, grâce à de nouvelles innovations dans la mise à l'échelle du modèle et la curation des données d'entraînement » ajoutent-ils. Phi-2 s’adresse notamment aux chercheurs, en particulier pour l'exploration de l'interprétabilité mécaniste, l'amélioration de la sécurité ou le réglage fin de l'expérimentation sur une variété de tâches. Phi-2 est disponible dans le catalogue de modèles d'Azure AI Studio, est-il précisé.
Phi-2 se frotte à Mistral (7B) et Llama-2
Phi-2 est un modèle basé sur Transformer avec un objectif de prédiction du mot suivant, entraîné sur 1,4 T de tokens à partir de plusieurs passages sur un mélange d'ensembles de données synthétiques et Web pour le NLP et le codage. L'entraînement de Phi-2 a duré 14 jours sur 96 GPU A100. Les chercheurs précisent que ce modèle de base n'a pas fait l'objet « d'un alignement par apprentissage par renforcement à partir du feedback humain (RLHF), ni d'un réglage fin de l'instruction ». Une baisse des biais a toutefois été remarquée par rapport au modèle Phi-1.5.
Plusieurs benchmarks ont ensuite été réalisés afin de mesurer les performances de Phi-2 par rapport à des modèles de langage populaires. Les benchmarks couvrent plusieurs catégories, à savoir, Big Bench Hard (BBH), raisonnement de bon sens, compréhension du langage, mathématiques, et codage (HumanEval, MBPP). Sur le codage, Phi-2 surpasse largement les modèles Mistral et Llama-2 à 7 milliards de paramètres (53,7 contre 39.4 et 21,0). Le modèle obtient également de meilleures performances que le modèle Llama-2-70B, 25 fois plus grand, pour les tâches de codage et talonne le modèle Llama-2-70B pour les mathématiques. Les deux modèles sont au coude à coude sur le raisonnement de bon sens tandis que la compréhension du langage offre un avantage à Llama-2-70B. En outre, Phi-2 égale ou surpasse le Google Gemini Nano 2 (3,2 B paramètres) récemment annoncé.
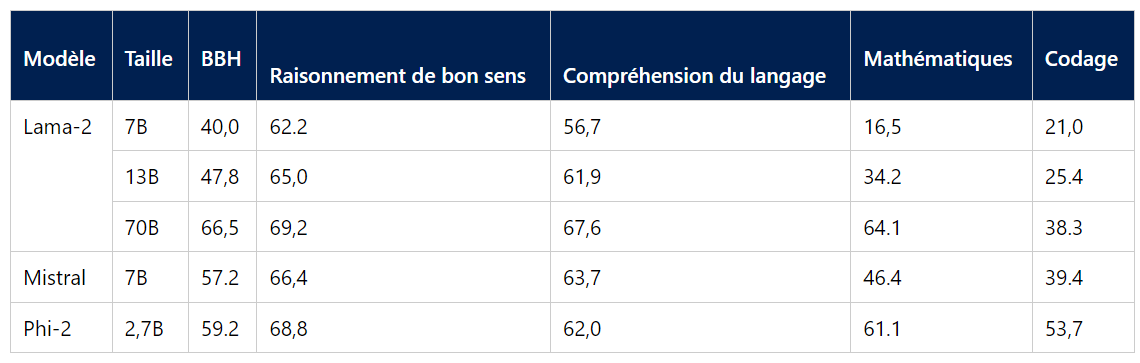
Performances moyennes sur des benchmarks groupés par rapport aux petits modèles de langage open source populaires. (Crédit : Microsoft)
La qualité des données essentielle au développement d'un tel modèle
À travers cet ensemble de modèles Phi, les chercheurs veulent former des SLM qui atteignent des performances comparables à celles de modèles d'échelle beaucoup plus élevée (mais encore loin des frontier models). Souhaitant « briser les lois conventionnelles de mise à l'échelle des modèles de langage », l’équipe de chercheurs est arrivée aux conclusions suivantes. Premièrement, la qualité des données d'entraînement joue un rôle essentiel dans la performance des modèles. « Notre mélange de données d'entraînement contient des ensembles de données synthétiques spécifiquement créés pour enseigner au modèle le raisonnement de bon sens et les connaissances générales, y compris la science, les activités quotidiennes et la théorie de l'esprit, entre autres. Nous complétons notre corpus de formation par des données web soigneusement sélectionnées et filtrées en fonction de leur valeur éducative et de la qualité de leur contenu » décrivent-ils. « Deuxièmement, nous utilisons des techniques innovantes pour passer à l'échelle supérieure, en partant de notre modèle à 1,3 milliard de paramètres, Phi-1.5, et en intégrant ses connaissances dans le modèle à 2,7 milliards de paramètres Phi-2 ». Un transfert de connaissances à grande échelle qui permet non seulement d'accélérer la convergence de la formation, mais aussi d'améliorer nettement les résultats du test Phi-2.
Commentaire