La plate-forme LinkedIn génère chaque jour plusieurs dizaines de téraoctets de données, incluant les informations relatives aux profils de ses membres, aussi bien que les actions utilisateurs ou encore les commentaires et les partages d'informations, persistantes dans ses bases de données et dans ses systèmes de gestion des événements.
Pour simplifier l'extraction des données depuis les différentes SGBD, plusieurs innovations ont déjà été mises en oeuvre par LinkedIn, allant du changement continu des flux de données (Databus), à l'instrumentalisation des chemins d'applications de code pour suivre tous les événements importants et les regrouper au travers d'un tuyau d'activité central (Kafka). Des datasets volumineux, nécessitant une ingestion de données, peut par ailleurs s'adapter sans effort et rendre la donnée disponible avec un temps de latence faible et programmé.
Mais LinkedIn a décidé en 2013 d'aller plus loin pour faciliter la tunnelisation des données dans ses datawarehouse Teradata/Hadoop, et l'ingestion de données aussi bien internes qu'externes en provenance de Salesforce, Google, Facebook et Twitter. Le réseau social professionnel à ainsi développé Gobblin, dont le fonctionnement vient d'être dévoilé.
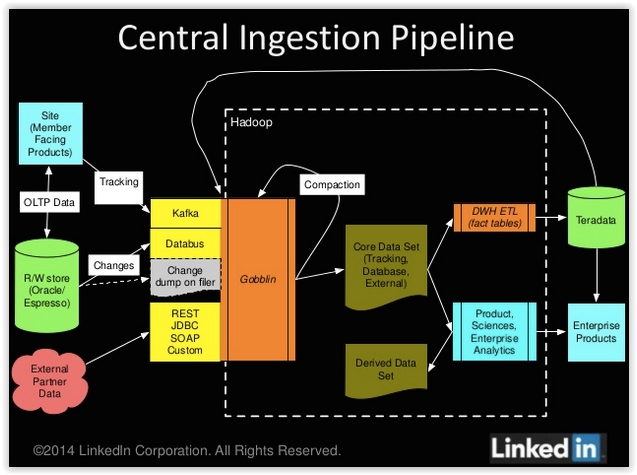
Schéma de fonctionnement du framework big data Gobblin développé par LinkedIn
Le framework big data Gobblin en Open Source dans les prochaines semaines
Gobblin fonctionne ainsi comme une passerelle Hadoop pour préparer tous les flux de données entrants et s'assurer que les données sont bien dirigées vers le bon répertoire de fichiers. Gobblin contient des connecteurs pour toutes les sources de données communes de LinkedIn, comme Salesforce, MySQL, Google, Kafka et Databus... En complément, un gestionnaire de ressources YARN taillé pour l'ingestion continue ou programmée de données a également été mis en place.
La solution permet de répondre à plusieurs besoins, à la fois en termes de protocoles d'échange (les adaptateurs existants peuvent facilement être réutilisées pour des sources s'appuyant sur des protocoles communs comme JDBC, REST, SFTP et SOAP), d'intégration de source (intégration complète avec les sources communément utilisées incluant MySQL, SQLServer, Oracle, Salesforce, HDFS, Dropbox...), l'ingestion sémantique (ingestion incrémentale et vidage des datasets), règles d'exécution des flux (les propriétaires de flux n'ont plus qu'à spécifier des règles prédéfinies et indiquer les données à publier).
Aujourd'hui, Gobbling aide LinkedIn pour traiter des dizaines de processus par jour. Dans les prochaines semaines, le réseau social professionnel compte ouvrir ce framework big data à la communauté Open Source.
Comment LinkedIn exploite son outil big data pour analyser ses données
1
Réaction
Le réseau social professionnel LinkedIn a fourni des détails sur le fonctionnement de Gobblin, son framework big data qui lui permet d'analyser de très grands et variés volumes de données pouvant être analysées dans ses entrepôts Hadoop.
")
Newsletter LMI
Recevez notre newsletter comme plus de 50000 abonnés
Il fait son boulot et encore bien petitement !
Signaler un abusPM