
")
Toujours en mode virtuel pour cause de pandémie, Nvidia a donné le coup d'envoi de sa conférence sur la technologie des GPU (GTC ou GPU Technology Conference 2021) avec une première annonce attendue : le fournisseur, qui finalise l’acquisition d’ARM, prépare pour 2023 une puce nommée Grace et destinée au marché HPC (calcul haute performance). Reposant sur l'architecture Neoverse d'ARM, Nvidia affirme que Grace offrira des performances jusqu'à 10 fois supérieures à celles des serveurs les plus rapides actuellement sur le marché pour les charges de travail complexes d'intelligence artificielle et de HPC. Il s’agit toutefois d'une comparaison curieuse entre le passé et le présent, car la puce Grace ne sera pas commercialisée avant 2023 et, durant les deux années à venir, AMD et Intel continueront à muscler leurs processeurs et accélérateurs respectifs.
Nvidia a toutefois précisé que Grace n'est pas destiné à concurrencer les processeurs Xeon d'Intel et Epyc d'AMD. Grace est plutôt un produit de niche, dans la mesure où il est conçu spécifiquement pour être étroitement couplé avec les accélérateurs GPU maison afin de supprimer les goulots d'étranglement pour les applications complexes d'IA et de HPC. Il s'agit d'une décision intelligente de la part de Nvidia, car les processeurs serveur d’ARM à usage général n'ont pas donné les résultats escomptés. Nvidia lui-même n’a guère convaincu avec ses puces ARM pour microserveurs et le projet Denver lancé il y a 10 ans n'est jamais sorti des laboratoires. Denver était un processeur à usage général, alors que Grace est hautement vertical et spécialisé. Ce n’est pas la première tentative de Nvidia dans ce domaine : en 2012, le fournisseur de San José avait déjà poussé une solution similaire avec sa puce mobile Tegra (toujours sur base ARM) associée à ses accélérateurs GPU Tesla. Mais avec le rachat d’ARM, le design de ces processeurs devraient s’affiner pour mieux correspondre aux projets de Nvidia.
Une offre DGX sans puce x86
« L'IA de pointe et la science des données poussent l'architecture informatique actuelle au-delà de ses limites - en traitant des quantités impensables de données », a déclaré Jen-Hsun Huang, le CEO de Nvidia durant sa keynote. « En utilisant la propriété intellectuelle sous licence d'ARM, Nvidia a spécifiquement conçu le processeur Grace pour l'IA et le HPC à grande échelle. Couplé au GPU et au DPU, Grace nous donne la troisième technologie fondamentale pour l'informatique, et la capacité de réarchitecturer les centres de données pour faire progresser l'IA. Nvidia est désormais une société à trois puces ».
Le fournisseur propose déjà des serveurs HPC avec la série DGX, qui utilisent des puces x86 AMD Epyc - après des Intel Xeon pour la première génération - pour démarrer et coordonner le travail des ses GPU Ampere. La puce Epyc d’AMD est une bonne base pour exécuter des workflows traditionnels, mais c'est un processeur de calcul de type général, qui n'a pas la bande passante I/O, ni les optimisations en machine learning dont Nvidia a besoin. Ce dernier n'a pas livré beaucoup de détails sur sa plateforme Grace. On sait juste qu’elle repose sur une future version du noyau Neoverse d'ARM utilisant un processus de gravure en 5 nanomètres, ce qui signifie qu'il sera fabriquait par TSMC. Grace utilisera également l'interconnexion haute vitesse NVLink, développée par Nvidia, entre le CPU et le GPU. La version, prévue pour 2023, offrira une bande passante de plus de 900 Go/s entre le CPU et le GPU. C'est beaucoup plus rapide que le protocole PCI Express 4.0 (32 Go/s) utilisé par AMD et Intel pour les communications entre le CPU et les autres composants GPU ou NVMe.
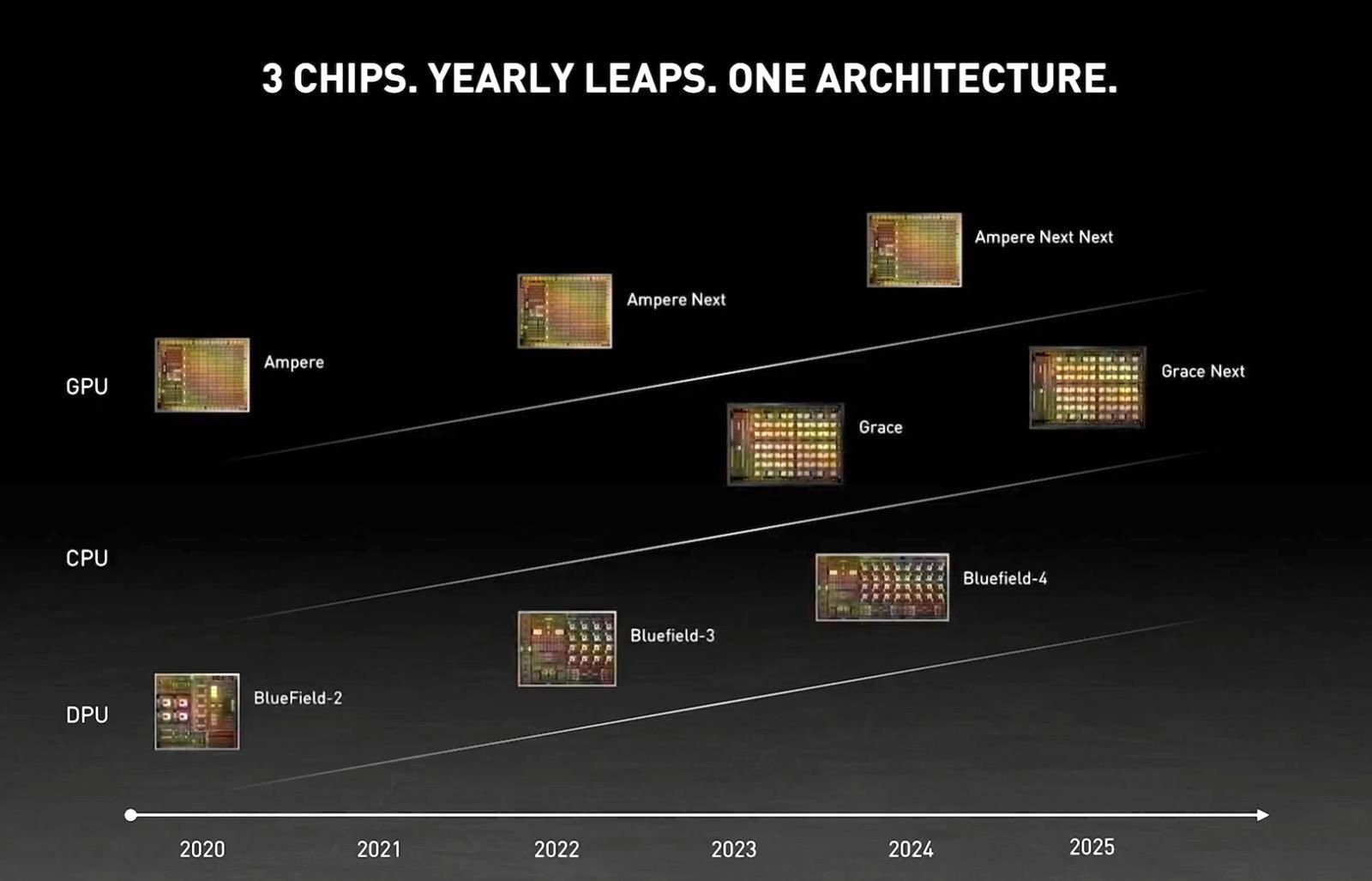
La feuille de route de Nvidia jusqu'en 2025 avec des GPU Ampere Next, l'arrivée de la puce HPC Grace et les carte DPU (data processing unit) BlueField, issues du rachat de Mellanox. (Crédit Nvidia)
Déjà 2 clients dans le domaine HPC
Même si Grace ne sera pas livré avant 2023, Nvidia a déjà deux clients HPC pour ce processeur. Le Centre national suisse de supercalcul (CSCS) et le Laboratoire national de Los Alamos ont annoncé aujourd'hui qu'ils allaient commander des superordinateurs basés sur Grace. Les deux systèmes seront construits par la filiale Cray de HPE et devraient être mis en service en 2023.
Le système du CSCS, appelé Alps, remplacera l’actuel Piz Daint, un cluster Xeon avec des accélérateurs Nvidia P100. Le CSCS affirme que Alps offrira 20 ExaFLOPS de performance en IA, bien mieux que le champion japonais Fugaku avec seulement un exaflop.
Commentaire