")
En direct de San Francisco – Si les cartes graphiques étaient hier réservées aux joueurs et aux stations de travail, leur arrivée sur le segment des supercalculateurs a dopé la recherche scientifique et un très grand nombre d’applications grâce à leurs capacités éprouvées pour le traitement parallèle. Aujourd’hui, les bases de données et l’analytique sont le nouveau terrain de jeu des GPU grâce à des start-ups comme MapD (désormais rebaptisée OmniSci) fondée en 2013 par Todd Mostak.
A la fois base de données SQL in-memory (RAM pour les données chaudes et flash pour les froides) et outil de visualisation, alimentée par une batterie de GPU, la plateforme de la start-up MapD (Massively Parallel Data) a été conçue pour l'exploration rapide et immersive de données en réduisant le recours à des data analystes. En apportant la puissance des GPU – comme sur les supercalculateurs - à l'analyse de données, MapD propose d’interroger et de visualiser des milliards d'enregistrements en quelques millisecondes. La base de données MapD Core tire parti du parallélisme des GPU avec un moteur de compilation de requêtes pointu capable d’accélérer les requêtes analytiques SQL, afin de réduire la latence pour l'exploration des grands ensembles de données.

Dédiée à la dataviz, MapD Core repose sur un moteur open source disponible sous licence Apache.
Plus besoin d'index
La puissance de traitement parallèle des cartes GPU permet au moteur open source MapD Core SQL d'interroger des milliards de lignes en quelques millisecondes à l'aide de commandes SQL standard, nous a expliqué Grant Halloran, CMO de MapD. Le système d'analyse visuelle MapD Immerse exploite le moteur de rendu de MapD Core SQL pour afficher en quelques millisecondes des ensembles de données avec des milliards d'enregistrements, tout en fournissant une analyse interactive rapide jusqu'au niveau des points de données individuels, a souligné Tood Mostak, CEO de la société. Les plus gros gains ne sont pas dans la réponse à chaque requête (qui sont évidemment beaucoup plus rapides) mais dans le travail de préparation, car il n'y a pas besoin de prétraitement. De nombreuses bases de données gagnent du temps en conservant un index, qui est effectivement un résultat pré-calculé de toutes les recherches possibles. Si cet indice est corrompu ou détruit, sa reconstruction peut prendre des heures, voire des jours. Cependant, si les données peuvent entrer dans la mémoire de GPU, il est possible de se passer d’index. Et si les données changent rapidement et que la majeure partie de l'index n'est jamais utilisée, il peut être très efficace d'ignorer ce prétraitement.
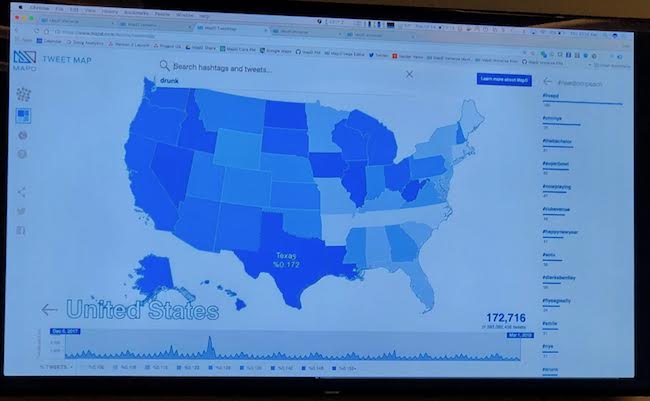
L'outil de data visualisation de MapD permet de traiter et d'afficher presque en temps réel la progression géographique des recherches Twitter sur une carte.
MapD se distingue particulièrement pour des applications à grande échelle telles que l’affichage géospatial de points, l'analyse IoT avec des millions de capteurs, la modélisation météo, la traque à la fraude bancaire et l'analyse de logs pour la sécurité. La solution effectue ces opérations en quelques millisecondes. MapD Immerse permet également d'éviter les coûts supplémentaires liés au transfert de jeux de résultats volumineux du serveur vers l’utilisateur, en envoyant uniquement des images PNG compressées. MapD travaille avec les plateformes AWS, Google Cloud Engine et IBM Cloud, et propose d’exécuter un certain nombre de démonstrations pour test en ligne. Plusieurs versions du produit sont disponibles : open source pour tests et édition commerciale avec support. Si MapD est agnostique au niveau du choix des GPU - le modèle est l'open source - Nvidia fait partie des investisseurs de la start-up qui a levé 37 millions de dollars à ce jour.
Commentaire