")
Ponicode accompagne les développeurs avec des outils automatisant les tests unitaires et facilitant la documentation du code. Ses solutions, déjà utilisées par 8000 développeurs, sont basées sur l’apprentissage machine. La dernière en date s’adresse justement aux équipes de data science. Ponicode a adapté au langage Python sa solution d’origine afin d’apporter maintenant aux data scientists une interface visuelle low-code « pour créer des fichiers de tests unitaires exhaustifs en quelques clics », décrit-il.
« La plupart des data scientists ont généralement une formation en mathématiques et pas nécessairement en génie logiciel mais ils doivent de plus en plus souvent prendre en charge des tâches de machine learning », pointe l’éditeur. Un terrain à arpenter pour ses outils destinés à produire du code qui puisse être modifier aisément puisque les applications d’intelligence artificielle n’échappent pas aux problèmes de maintenabilité et de coûts de correction des bugs, voire les rencontrent de façon amplifiée, selon Ponicode.
Sensibiliser aux bonnes pratiques
La solution Ponicode for Data Science a d’abord été utilisée par la propre équipe de data science de l'éditeur avant de constituer un produit aujourd’hui disponible en bêta. Celui-ci vise à la fois à sensibiliser les data scientists à l’intérêt de recourir à de bonnes pratiques pour écrire un code de qualité et à leur permettre de réduire les temps passés sur les tests pour développer des pipelines d’apprentissage machine prêts pour la production.
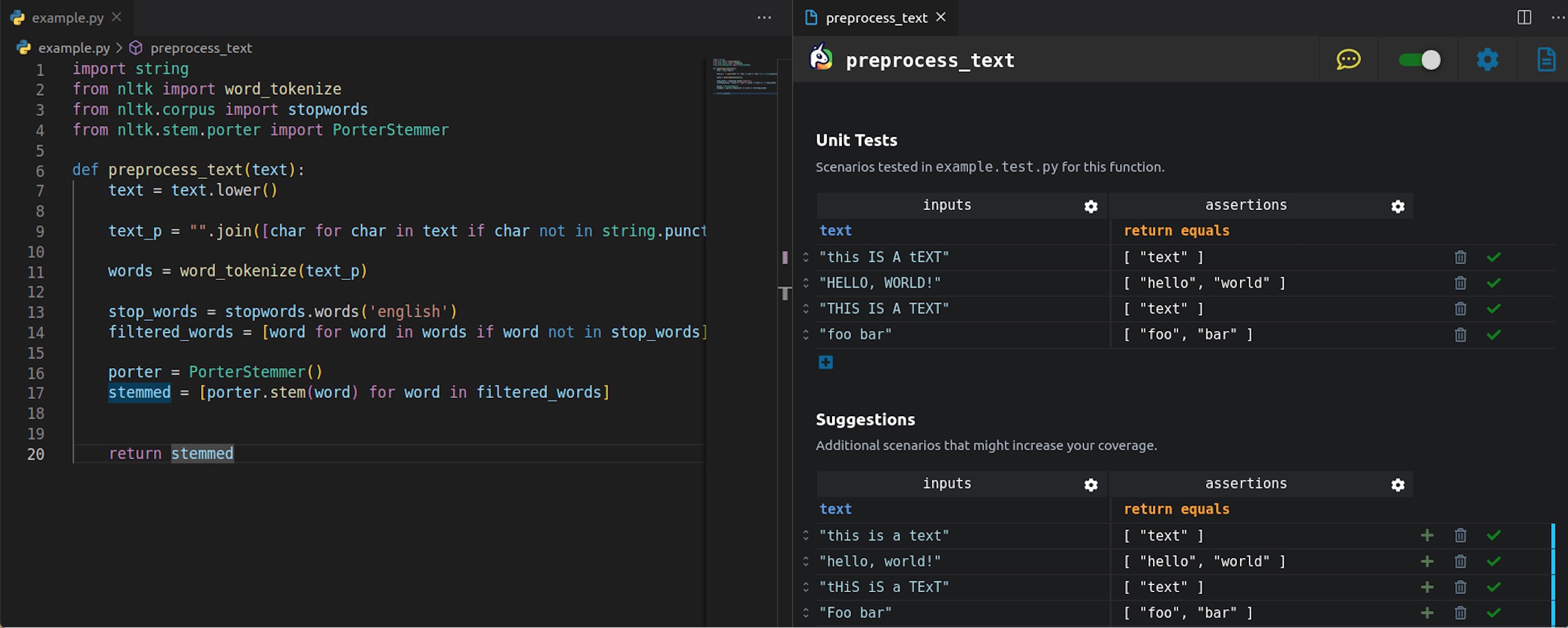
Ponicode for Data science présente une approche low-code appelée « Table driven test approach ». Ci-dessus, vue de l'extension Ponicode dans VS Code. A gauche, l'utilisateur a écrit une fonction dans la phase de pré-processing de la construction de son modèle de machine learning. A droite, il trouve des suggestions qu'il pourra ajouter à son test unitaire. (Crédit : Ponicode) Agrandir l'image
L’approche low-code proposée fournit dans un tableau la liste des tests suggérés. Elle permet de créer des fichiers de tests pour identifier les bugs et régressions et améliorer la capacité des data scientists à catégoriser les erreurs venant d’un manque de cohérence dans le pré-traitement. Les équipes peuvent réaliser les tests sans formation préalable et gagner ainsi en confiance sur la qualité du code délivré. L’outil est en version bêta et l’éditeur attend les retours des premiers utilisateurs pour le faire évoluer.
Commentaire