Flux RSS
SGBD
377 documents trouvés, affichage des résultats 11 à 20.
| < Les 10 documents précédents | Les 10 documents suivants > |
(20/02/2012 14:38:21)
Microsoft réduit jusqu'à 75% le coût de SQL Azure
Les tarifs d'utilisation du service de base de données SQL Azure viennent d'être revus à la baisse par Microsoft. L'éditeur a également lancé une option pour ouvrir ce service aux clients souhaitant accéder à moins de 100 Mo. Steven Martin, directeur général, responsable de la planification pour Windows Azure, a communiqué la semaine dernière les prix révisés. Dans un billet, il indique que les utilisateurs vont bénéficier d'une économie de 48% à 75% pour les bases de données de plus de 1 Go (48% pour les bases de 5 Go tarifées 25,99 $ par mois contre 49,95 $ précédemment, 75% pour celles 25 Go, par exemple, désormais à 75,99 $ contre 299,97 $, ce qui, dans ce cas, met le Go à 3,04 $). Quant à l'option 100 Mo, elle permettra de commencer à utiliser SQL Azure pour la moitié du précédent coût, en fournissant malgré tout la totalité des fonctionnalités. Cela inclut la haute disponibilité, la tolérance aux pannes, le provisionning, l'évolutivité de la base, la connexion aux bases installées sur site et le SLA complet.
Ces deux modifications dans l'offre SQL Azure de Microsoft résultent des remarques communiquées par les utilisateurs et de l'évolution des modèles d'usages, explique Steven Martin. Au cours des dix-huit mois écoulés, deux usages se sont dégagés. En premier lieu, de nombreux projets démarrent modestement mais ils ont besoin de grossir rapidement. D'où la possibilité offerte d'accéder à des déploiements plus larges à moindre coût. « A mesure que votre base de données grossira, le prix par Go baissera de façon significative », assure le responsable de Microsoft. Deuxièmement, de nombre clients du cloud ayant des traitements plus légers veulent disposer d'une option peu coûteuse pour des usages modestes. « De la même façon que nous proposons une option de 150 Go pour les clients ayant des pré-requis élevés, nous étendons la palette de choix à l'autre bout du spectre avec une option de départ à 100 Mo », ajoute Steven Martin.
A partir de 3,54 euros par mois pour 100 Mo
La facturation de SQL Azure est calculée sur la base d'un tarif progressif, en fonction de la taille de la base de données. Cette dernière existe en deux éditions. L'édition Web prend en charge une base de données relationnelle T-SQL (Transact-SQL) de 5 Go maximum. L'édition Business va jusqu'à 150 Go. Le site Windowsazure.com/fr donne le détail de la tarification pour un paiement à l'utilisation. Une calculatrice en ligne permet de se faire immédiatement une idée du coût en fonction du nombre de Go consommé. Il existe aussi un tarif d'abonnement de six mois(*). 
En déplaçant le curseur de la calculatrice, on connaît le prix du service au Go consommé, ci-dessus 120,45 euros pour 94 Go par mois.
A l'utilisation, le prix de SQL Azure, par base de données et par mois, démarre à 3,5425 euros par mois jusqu'à 100 Mo. Il s'élève à 7,085 euros entre 100 Mo et 1 Go. Entre 1 Go et 10 Go, l'utilisation de SQL Azure est facturée 7,085 euros pour le premier Go et 2,834 euros pour chaque Go supplémentaire(**). Ainsi, pour une base de données de 4,4 Go utilisée une journée, il en coûtera 0,5944 euros au client.
(*) L'abonnement de six mois à SQL Azure coûte 56,729 euros pour une unité de base, ce qui correspond en fait à une valeur de 70,92 euros sur la base de données Business Edition lorsque celle-ci est facturée à l'utilisation. Ce service s'adresse à des utilisateurs qui démarrent ou qui ont des besoins réduits en taille de base. Pour les entreprises plus consommatrices, Microsoft propose un autre abonnement, annuel cette fois, à partir de 10 000 euros, explique Julien Lesaicherre, de Microsoft France. Cela correspond à une utilisation pré-payée que l'entreprise consommera comme elle l'entend, au rythme choisi.
(**) Entre 10 Go et 50 Go, il en coûte 32,5906 euros pour les 10 premiers Go, puis 1,417 euros pour chaque Go. Enfin, au-delà, les 50 premiers Go reviennent à 89, 2699 euros, puis à 0,7085 euros pour chaque Go supplémentaire. (...)
SAP adapte HANA, la base de données en mémoire, aux PME
Les PME vont disposer de la solution analytique haute performance de SAP. L'offre comprend une nouvelle édition Edge du logiciel ainsi que des outils analytiques sous HANA pour sa suite ERP (Enterprise Resource Planning) Business One. « Ces produits seront vendus par nos partenaires sur un marché où SAP compte plus de 96 000 clients, ce qui représente 79% de sa base client totale, » a déclaré Eric Duffaut, patron de la distribution mondiale de SAP, au cours d'une conférence téléphonique avec la presse et les analystes.
La technologie HANA consiste à traiter les données depuis la RAM au lieu de les écrire et de les lire sur des disques durs traditionnels, ce qui permet de meilleures performances. La base de données, qui sait gérer aussi bien les charges de travail décisionnelles que transactionnelles, est vendue sous forme d'appliance par un certain nombre de fournisseurs. « L'édition Edge de HANA est disponible. Elle est identique à la version Entreprise, » a déclaré Bobby Vetter, vice-président senior, SAP, Ecosystem & Channels Readiness. « L'édition Edge aura aussi le même calendrier de sortie que l'édition Entreprise, » a t-il ajouté. Cependant, la quantité de RAM des appliances HANA Edge sera plafonnée et moins élevée. Celles-ci pourront également être vendues en bundle avec la suite logicielle BusinessObjects Edge BI (business intelligence) de SAP.
Comme le précise SAP dans un communiqué, l'offre d'analytiques pour Business One, son application de gestion intégrée, est susceptible de répondre à tous les besoins « à petite échelle. » Celle-ci s'appuie sur une application SAP basée sur HANA facile à utiliser et intégrant des processus essentiels, notamment pour le reporting « avec Crystal Reports, lequel génère en temps réel des rapports complets à partir de données actualisées. »
Pas de prix dévoilé et une montée en charge progressive
Le produit doit entrer dans sa phase de montée en charge ou « ramp-up» (un terme utilisé par SAP pour désigner le lancement de programmes destinés aux « early adopters) d'ici la fin du mois de février. La diffusion générale est prévue plus tard cette année. Bobby Vetter et Eric Duffaut n'ont pas voulu donner de détails sur le prix des produits, mais tous deux ont souligné que leur coût sera adapté. « Nous savons que ce marché est sensible à la question du prix, » a déclaré Eric Duffaut en ajoutant que « le prix sera juste. »
HANA est disponible pour tous depuis juin dernier. Depuis cette date, SAP est resté très discret sur sa technologie et sur sa feuille de route technique. Le mois dernier, Vishal Sikka, CTO et membre exécutif du Conseil d'administration de SAP, a révélé que l'entreprise avait l'intention d'utiliser le support HANA pour faire tourner certains modules de sa Business Suite phare d'ici à la fin de cette année. Dans le futur, HANA devrait aussi servir de base à une prochaine génération d'architecture logicielle pour les produits de l'éditeur allemand.
L'an dernier, les ventes de HANA ont atteint plus de 160 millions d'euros. « Dans l'histoire de SAP, c'est le produit qui affiche la plus forte croissance, » a déclaré l'entreprise.
SAP prêt à ouvrir sa technologie HANA à Oracle
SAP serait prête à ouvrir sa technologie HANA à son grand rival Oracle. «Ce serait tout à fait possible. La question est de savoir si Oracle pourrait imaginer cela», a indiqué Bill McDermott, co-CEO de SAP, en réponse à une question de la Frankfurter Allgemeine Zeitung dans un entretien publié le 30 janvier. «Plus sérieusement : une plateforme technologique n'a de sens que si elle est ouverte à des partenaires, et même à des concurrents. Des partenaires comme Cisco, Dell, Fujitsu ou encore HP utilisent déjà notre technologie HANA, et nous sommes ouverts à tout», poursuit-il.
Pour rappel, la technologie HANA, qui permet une analyse très rapide de grosses quantités de données, a été lancée en grande pompe l'an dernier, et a connu un franc succès auprès des clients de SAP, contribuant aux bons résultats financiers présentés la semaine dernière.
ICTjournal.ch
SQL Server 2012 , lancement prévu le 7 mars 2012
Comme l'a annoncé Microsoft, le lancement de sa base de données de prochaine génération SQL Server 2012 aura lieu le 7 mars lors d'un événement retransmis en ligne. Sont attendues les allocutions des vice-présidents Ted Kummert Ted et Quentin Clark qui livreront aux participants la vision de Microsoft en matière de montée en charge des bases de données, ainsi qu'un aperçu général sur les fonctionnalités de SQL Server 2012.
Le communiqué ne permet pas de savoir si le 7 mars correspond aussi à la date de disponibilité réelle et générale du produit. Mais la tenue de cet événement laisse penser que sa livraison pourrait être imminente. « Regardons la réalité : si vous n'êtes pas en train de travailler sur la version bêta d'un logiciel ou sur le point de faire des tests d'une version build privée en situation réelle ou d'une Release Candidate, vous ne ferez pas partie de ceux qui installeront et déploieront SQL Server 2012 le 7 mars, je vous l'affirme, » a écrit dans un blog Aaron Bertrand, expert de SQL Server. « Ces événements font partie des techniques marketing pour créer de l'attente et de l'excitation autour d'un produit. Est-ce que vous pourrez télécharger les éditions Express sur le site Web de Microsoft, et autres SKU sur le portail Microsoft Developer Network (MSDN) ou depuis votre portail de licences, peu de temps après ? Bien sûr. Et le jour d'après ? À peu près sûr que non. »
3 éditions pour SQL Server 2012
SQL Server 2012 se décline en trois éditions principales, dont une nouvelle version Business Intelligence plutôt destinée aux décideurs, qui donnera accès à toutes les fonctionnalités d'analyse décisionnelle. Celle-ci qui ajoute à l'édition standard l'outil Power View, qui permet une analyse visuelle et interactive des données, et l'outil Data Quality Services & Master Data Management qui garantit la qualité des données. Cette version offre aussi les mêmes fonctions de reporting et d'analyses que celles de la version Standard, et supporte le traitement de très gros volumes de données. Microsoft prévoit également de proposer une version Entreprise, plutôt destinée aux grands comptes qui ont des besoins de haute disponibilité et de Data Warehouse. Cette mouture offre une fonction haute disponibilité (AlwayOn), une fonction Haute performance pour le Data Warehouse (ColumnStore), et enfin la virtualisation (avec la Software Assurance). A noter que la version Entreprise inclut toutes les fonctionnalités de la version Business Intelligence.
Microsoft va aussi adopter un nouveau mode de licences pour la version 2012. Le modèle de licence par puissance de calcul change puisqu'il sera fonction du nombre de coeurs et non plus du nombre de processeurs. Les éditions Enterprise et Standard seront ainsi disponibles avec le modèle de licence basé sur les coeurs. Les licences seront vendues par pack de deux coeurs. L'édition Standard sera également disponible sous le modèle de licence Serveur + Client Access Licence (CAL). Quant à l'édition BI, elle est uniquement disponible sous licence Serveur + CAL. Selon l'analyste Curt Monash de Monash Research, SQL Server « est un produit adapté si l'on n'a pas peur d'être enfermé dans la pile Microsoft. » Par exemple, « la fonction ColumnStore est très partielle, étant donné qu'elle ne peut pas être mise à jour. Mais, a contrario, Oracle n'offre pas de stockage en colonnes du tout. »
Un mode de licensing basé sur le nombre de coeurs CPU
« Il y a plus de lock-in avec SQL Server qu'avec d'autres plateformes, du fait que celui-ci doit fonctionner sous Windows, » ajoute l'analyste. « Les départements informatiques qui utilisent des produits concurrents, comme ceux proposés par Oracle notamment, pourraient envisager de faire cohabiter SQL Server 2012 avec leur plateforme plutôt que d'ajouter plus de licences Oracle, mais cela n'aurait de sens que s'ils ont déjà beaucoup investi dans la pile Microsoft, » explique Curt Monash. « IBM DB2 fonctionne aussi bien avec Oracle que pourrait le faire SQL Server, et cela sans avoir besoin de s'engager avec un système d'exploitation, » a-t-il déclaré.
« De toutes les façons, aucune base de données ne peut servir toutes les charges de travail de manière égale. La meilleure approche est de disposer d'un produit à usage général et de le compléter par des plates-formes de bases de données pour les fonctions analytiques et autres, » a ajouté l'analyste.
(...)(19/01/2012 17:20:04)DynamoDB, une base de données NoSQL sur Amazon Web Services
Amazon Web Services a lancé hier, sous le nom de DynamoDB, un service de base de données NoSQL qui procure à ses utilisateurs une performance prévisible sur des capacités évoluant de façon transparente. Ce service, en version bêta, conviendra aux acteurs du web qui récupèrent, stockent et traitent un volume croissant de données. L'hébergeur explique qu'avant la mise à disposition d'une base évolutive de ce type, les utilisateurs d'AWS pouvaient passer beaucoup de temps à préparer leurs bases pour qu'elles tiennent le choc dans les périodes d'intense utilisation. En effet, les SGBD traditionnels ne sont pas conçus pour se dimensionner aussi rapidement.
« L'ajustement et la gestion des bases de données a toujours été le talon d'Achille des applications web », rappelle Werner Vogels, directeur technique d'AWS. Pour monter en puissance, les entreprises avaient le choix entre acquérir un matériel plus important ou répartir les bases de données entre les serveurs, explique-t-il. « Ces deux approches étaient de plus en plus compliquées et coûteuses », poursuit-il. « De surcroît, il y a une pénurie de profils techniques ayant les compétences spécialisées pour le faire ».
Le service Amazon DynamoDB stocke les données sur des disques SSD et les réplique sur différentes zones de disponibilité du service. Amazon Web Services l'a conçu en s'appuyant sur son expérience de la construction de grandes bases de données non relationnelles pour Amazon.com. Le site de vente en ligne l'utilise en interne sur sa plateforme publicitaire, ainsi que sur Amazon Cloud Drive (son service de stockage de musique en ligne), IMDb (Internet Movie Database, sabase de données sur le cinéma) et pour son offre Kindle. D'autres sociétés, comme Elsevier, SmugMug et Formspring, y ont également recours.
Une architecture redondante et massivement élastique, souligne Ysance
Les tarifs de DynamoDB sont pour l'instant donnés pour l'Amérique du Nord. Le service démarre avec un niveau d'accès gratuit offrant jusqu'à 100 Mo de stockage et une capacité en lecture/écriture de 5 écritures et 10 lectures par seconde. Les tarifs d'exploitation sont calculés en fonction d'un forfait horaire basé sur le débit réservé, sur la capacité de données stockées et sur le volume de données transféré. Quand un utilisateur crée sa table DynamoDB, il spécifie quelle capacité il veut réserver en lecture/écriture. Si le débit dépasse la capacité réservée, il peut être limité. Néanmoins, la console de gestion fournie par AWS permet facilement de procéder à des modifications, en fonction des changements de trafic anticipés, explique AWS sur son site.
Partenaire d'AWS en France, l'intégrateur Ysance pointe une avancée sur le plan technique. « Amazon DynamoDB offre à la fois une base de données de type Clé/Valeurs très performante, une architecture redondante, massivement élastique et une intégration native avec l'analytique » dans le cadre d'une offre simple et packagée, commente dans un communiqué Olivier Léal, co-directeur de la division Intégration de la société. Il considère aussi qu'AWS crée un nouveau modèle en proposant désormais un niveau de performance fonctionnelle et non plus une capacité de traitement. Avec ce service, c'est AWS qui « dimensionne l'infrastructure en fonction des besoins du client et non l'inverse », souligne Olivier Léal. (...)
Faille critique dans Oracle Database : un patch à appliquer d'urgence
Ces deux derniers mois, nos confrères d'InfoWorld (du groupe IDG, un actionnaire du Monde Informatique), ont mené des recherches sur une vulnérabilité dans le logiciel phare d'Oracle, Database, qui pourraient avoir de graves répercussions pour les clients de l'éditeur, et potentiellement compromettre la sécurité et la stabilité des systèmes reposant sur la célèbre base de données.
Généralement, quand un bug se produit suite à une défaillance dans une base de données, les systèmes affectés peuvent être restaurés à partir des sauvegardes. Mais comme InfoWorld nous l'explique dans son enquête, un ensemble de problèmes techniques pourrait entrainer des défaillances à répétition dans la base de données d'Oracle et demander du temps et des efforts considérables pour corriger les erreurs. Selon une source qui a préféré rester anonyme, « C'est un problème très sérieux pour nous. Nous passons beaucoup de temps et dépensons beaucoup d'argent pour surveiller, planifier, et régler le problème dès qu'il se produit. »
Une enquête longue et minutieuse
Avant de rapporter ce problème, nos confrères ont effectué leurs propres tests, recoupé leurs informations avec des sources jugées fiables, et discuté à de nombreuses reprises avec Oracle, qui a reconnu qu'InfoWorld avait attiré son attention sur les aspects sécuritaires de ce problème. « Après avoir informé Oracle de nos découvertes et suite à plusieurs discussions techniques, l'éditeur nous a demandé de retenir cette information le temps de développer et de tester les correctifs relatifs à ces vulnérabilités. Dans l'intérêt des utilisateurs d'Oracle, nous avons accepté. Ces patches sont disponibles dans les mises à jour qu'Oracle a publiées au mois de janvier 2012 », expliquent nos confrères d'Infoworld qui ont réalisé un travail remarquable.
Pour être clair, l'aspect sécuritaire de la faille fait que n'importe quel client utilisant la version non patchée de la base de données d'Oracle pourrait être victime d'attaques malveillantes. Pire encore, un autre aspect, plus fondamental, pourrait poser un risque particulier pour les plus grands clients d'Oracle utilisant des bases de données interconnectées. Les deux problèmes proviennent d'un mécanisme ancré en profondeur dans le moteur de la base de données d'Oracle, avec lequel la plupart des DBA ont rarement à faire dans leur quotidien. Le coeur du problème réside dans le SCN (System Change Number), un système d'identification interne qui attribue un numéro à chaque validation de transaction : insertions, mises à jour et suppressions. Ces numéros sont attribués de manière séquentielle - sur une base temps - donc sans retour en arrière - lors de chaque modification de la base de données : insertions, mises à jour et suppressions. Le SCN est également incrémenté lors des échanges entre plusieurs SGBD liés.
Une vulnérabilité dans l'horloge interne de Database
Le SCN est crucial pour le fonctionnement de la base de données Oracle. « L'horodatage » SCN est la fonction clef pour maintenir la cohérence des données en permettant au SGBD de répondre aux requêtes de chaque utilisateur avec la version appropriée des données. Le SCN joue également un rôle important dans la consistance de la base de données car toutes les opérations de restaurations se font à partir de cet index.
Lorsque des bases de données Oracle sont reliées les unes aux autres, le maintien de la cohérence des données impose une synchronisation dans un SCN commun. Les architectes qui ont développé l'application phare d'Oracle étaient bien conscients que les SCN allaient générer un très grand nombre de numéros et ont donc intégré un générateur sur 48 bits. Soit 281 474 976 710 656 numéros attribuables. Il faudrait donc une éternité pour qu'une base de données Oracle épuise cette matrice pensez-vous ! Ajoutons qu'Oracle avait imposé une limite souple pour garantir qu'à un instant donné la valeur d'une clef SCN ne soit pas déraisonnablement élevée, ce qui indiquerait un dysfonctionnement de la base de données. Si la limite est dépassée, cette dernière peut devenir instable et / ou indisponible. Et parce que la numérotation du SCN ne peut pas être descendue ou remise à zéro, la base de données ne peut pas être restaurée à partir d'une sauvegarde. Une analogie peut être faite avec le bug de l'an 2000 sur un système non patché.
[[page]]
La limite imposée par Oracle découle d'un calcul très simple avec un seuil ancré dans le temps il y a 24 ans. Prenez le nombre de secondes depuis le 01/01/1988 à 00:00:00 et multipliez ce chiffre par 16 384. Si la valeur actuelle du SNC est inférieure à cela, alors tout va bien et le traitement continue normalement. Pour mettre cela en termes simples, le calcul suppose qu'avec une base de données fonctionnant en permanence depuis le 01/01/1988, il est impossible dans la réalité d'arriver à 16 384 transactions par seconde.
Mais il est toujours possible de modifier les conditions de cette réalité pour repousser la limite du SNC.
Le bug de sauvegarde
Un exemple récent vient sous la forme d'un bug de la base de données Oracle avec la fonction qui assure les sauvegardes live. Elle permet à un administrateur d'exécuter une commande afin de faciliter la sauvegarde d'une base de données en direct. C'est une fonction très pratique qui peut être exécutée facilement : «ALTER DATABASE BEGIN BACKUP » est la commande dont vous avez besoin. Vous pouvez ensuite sauvegarder la base jusqu'à ce que vous saisissiez la commande « ALTER DATABASE END BACKUP» qui switche sur le mode de fonctionnement normal. Un moyen très simple pour un administrateur de faire des sauvegardes de ses bases de données en production.
Le problème est que, en raison d'un codage défaillant, la commande «BEGIN BACKUP » entraine un bond spectaculaire du SCN qui continuera d'augmenter à un rythme effréné même après la saisie de la commande « END BACKUP » . Ainsi, effectuer une sauvegarde à chaud peut augmenter de plusieurs millions ou mêmes milliards la valeur du SCN. Dans la plupart des cas, les limites du SCN sont si éloignées que ce saut occasionnel n'est pas une cause de préoccupation majeure. Il est même certain que bien peu d'administrateurs ont remarqué le problème.
L'interconnection des bases multiplie l'effet du bug SCN
Mais quand vous mélangez le bug de sauvegarde live avec un grand nombre de bases de données interconnectées dans une mise en oeuvre massive de la plate-forme d'Oracle, la combinaison peut entraîner une élévation énorme du SCN. Certains grands clients d'Oracle ont des centaines de serveurs exécutant des centaines d'instances Database interconnectées dans toute l'infrastructure. Chacun peut être chargé avec un service de base et quelques fonctions moins importantes - mais presque tous sont reliés entre eux, à travers un, deux, quatre ou plus de serveurs intermédiaires.
Avec tous ces serveurs interconnectés, les SCN se synchronisent à un moment ou un autre. Collectivement, ils pourraient dépasser les 16 384 transactions par seconde, mais certainement pas depuis le 01/01/1988, donc la limite SCN n'est pas dépassée. Mais que faire si une DBA sur une partie de ce réseau Oracle gère la sauvegarde live et déclenche le précédent bug ? Soudain, le SCN fait un bond de, disons 700 millions, et ce nombre devient bientôt la référence pour tous les SCN interconnectés sur le réseau. Quelque temps plus tard, une autre commande de sauvegarde live est enclenchée par un DBA de l'autre côté de l'entreprise. Le SCN pousse jusqu'à quelques centaines de millions cette fois-ci, également synchronisé sur toutes les instances reliées au fil du temps.
Avec l'émission de quelques commandes de sauvegarde, le SCN d'un groupe de bases de données Oracle peut augmenter de plusieurs centaines de millions, voire de centaines de milliards dans une courte période. Même les SGBD qui se relient occasionnellement, par semaine ou par mois, pourraient voir leur nombre SCN bondir de plusieurs milliards.
Dans un tel scénario, ce n'est qu'une question de temps pour que les commandes de sauvegarde dépassent la limite du SCN et entrainent des problèmes très sérieux, blocage des requêtes provenant d'autres serveurs, ou plantages tout simplement.
[[page]]
Oracle a publié un correctif pour le bug du SCN lors des sauvegardes avant que l'équipe d'InfoWorld commence à enquêter sur cette histoire. Le bug de sauvegarde est répertorié comme le 12371955 : « croissance élevée du SCN ALTER DATABASE BEGIN BACKUP dans 11g. » Si vous n'avez pas déjà installé ce patch, Oracle recommande une installation immédiate.
Jusqu'à récemment, en dehors de la correction du bug de sauvegarde, la seule réponse d'Oracle à la question de la limite du SCN - pour autant que nous avons été en mesure de déterminer - a été de publier un patch qui étend le calcul de SCN à 32 768 fois le nombre de secondes depuis le 01/01/1988, doublant ainsi la taille de la limite. Oracle a même rendu modifiable cette limite, les administrateurs peuvent encore augmenter le multiplicateur. Si ce patch est appliqué à une instance d'Oracle, il va alléger le problème du SCN. Toutefois, il introduit aussi de nouvelles variables.
Impossible de patcher tous les serveurs en même temps
Une partie du problème est que vous ne pouvez pas mettre à jour tous les systèmes en même temps. De plus, si vous avez un système patché avec une limite d'élévation - basé sur un multiplicateur de, disons, 65 536 - le SCN sur ce système pourrait être plus élevé que le SCN sur un système non patché utilisant le multiplicateur de 16 384 d'origine. Le système non patché pourrait donc refuser la connexion. Il y a aussi la question des serveurs exécutant d'anciennes versions d'Oracle qui ne bénéficieront pas de correctif.
Par ailleurs, si ce patch est inclus par défaut dans la prochaine version d'Oracle Database, les administrateurs vont peut-être soudainement découvrir que leurs anciens serveurs sont incapables de communiquer avec les serveurs dotés de la version bénéficiant d'une méthode de calcul plus élevée pour le SCN. Pire, ils pourraient s'aligner sur les nombres du nouveau système de calcul, mais en gardant leur limite d'origine. Comme mentionné précédemment, le risque d'un tel scénario est très faible, sauf dans les environnements hautement interconnectés où un SCN élevé peut plomber un serveur à la manière d'un virus. Et une fois le serveur infecté, il n'y a aucun retour en arrière possible. Aussi, si le SCN est incrémenté arbitrairement - ou manuellement, avec une intention malveillante - alors la limite des 48 bits ne sera pas aussi astronomique qu'on le pensait au début de ce papier.
Un point préoccupant pour les utilisateurs
La rédaction d'InfoWorld a contacté des utilisateurs américains de la base de données d'Oracle pour parler de ce problème. Plusieurs de ces interlocuteurs n'étaient pas familiers avec le sujet; d'autres ont indiqué que les accords de licences Oracle les empêchent de faire des commentaires sur tout aspect de leur utilisation des produits de l'éditeur. Le chef de l'Independent Oracle User Group (IOUG), Andy Flower, a simplement indiqué au sujet de ce dossier: « Ce bug avec les numéros du SCN est évidemment un point qui préoccupe nos membres. Je suis sûr que ce sera un sujet que certains de nos membres les plus importants aborderont. Ils vont se réunir et en discuter. »
Parmi les experts Oracle, nos confrères d'Inforworld ont rencontré Shirish Ojha, senior DBA Oracle pour Logicworks, un fournisseur de services en ligne de type cloud. Il était bien sûr informé des problèmes du SCN, et notamment du bug de la numérotation. Il reconnaît que quelques environnements Oracle sont susceptibles de rencontrer le problème, et que les conséquences peuvent être graves. « S'il y a un bond spectaculaire dans les SCN en raison d'un bug Oracle, il y a une probabilité minimale de rupture si ce nombre devient anormalement élevé », a déclaré M. Ojha, qui a obtenu le très convoité titre d'Oracle Certified Master. « Si cela se produit pendant des transactions intensives sur une grande architecture interconnectée, cela va rendre toutes les bases de données interconnectées Oracle inutiles dans un laps de temps très court. »
M. Ojha poursuit : « Si cela se produit, même si la probabilité reste faible, le potentiel de perte [financière] ... est très élevé. » Par définition, dit-il, le problème peut potentiellement uniquement affecter tous les grands clients d'Oracle. Mais « une fois la limite SCN atteinte, il n'existe pas d'autre moyen de sortir du problème, que de fermer toutes les bases de données et de les reconstruire à partir de zéro. »
[[page]]
Anton Nielsen, le président C2 Consulting et expert Oracle, a évalué le risque potentiel d'attaque malveillante utilisant un SCN élevé: « En théorie, l'attaque SCN élevée est similaire à une attaque DoS de deux manières significatives : Il peut mettre un système à genoux, le rendant inutilisable pour une période de temps significative, et il peut être accompli par un utilisateur avec des autorisations limitées. Alors qu'une attaque DoS peut être perpétrée par n'importe qui avec un accès réseau à un serveur web, la modification du SCN nécessite un accès à la base de données via un nom d'utilisateur et un mot de passe. »
La réaction d'Oracle
Lorsque nos confrères d'Infoworld ont contacté Oracle au sujet du SCN, Mark Townsend, vice-président en charge des bases de données, a demandé un peu de temps pour évaluer le problème. « La façon dont vous mettez ces [questions] ensembles ne ressemble à rien de ce que nous avons vu ... nous avons besoin de comprendre ce que vous avez fait pour élever de plusieurs milliards le SCN. »
Après de nombreuse discussions et l'échange de données techniques, Oracle a reconnu qu'il y avait plusieurs façons d'augmenter le SCN à volonté. Se référant à une de ces méthodes, M. Townsend a déclaré : « C'est une situation irrégulière, un paramètre caché, il n'a jamais été prévu que les clients le découvrent et l'utilisent. » Toutefois, nos confrères ont souligné qu'il y avait plusieurs autres méthodes qui pourraient être utilisées. Elles ont bien sûr été détaillées à Oracle.
Des correctifs disponibles depuis janvier 2012
Pour corriger ces vulnérabilités, Oracle a publié une série de patchs présents dans sa mise à jour de janvier (Oracle Critical Patch). Ces correctifs bloquent les différentes méthodes qui permettent d'augmenter artificiellement la numérotation du SCN et mettent en oeuvre une nouvelle méthode de protection, ou «l'inoculation», comme le dit M. Townsend, pour les bases de données Oracle.
Nos collègues n'ont pas eu le temps de tester exhaustivement ces correctifs, ils ne savent donc pas encore ce que cache le terme «inoculation». En fait, sans de nombreux tests, il est pour l'instant impossible de fournir plus de détails sur les moyens de bloquer la hausse de la numérotation du SCN lorsque plusieurs bases de données sont interconnectées.
Ces correctifs sont seulement disponibles pour les récentes versions du SGBD de l'éditeur : Oracle 11g 11.1.0.7, 11.2.0.2, et 11.2.0.3, ainsi qu'Oracle 10g 10.1.0.5, 10.2.0.3, 10.2.0.4 et 10.2.0.5. Les versions plus anciennes continueront d'être affectées. Étant donné le grand nombre d'installations de licences Oracle 11.2.0.2.0 et 10.1.0.5, une importante base installée restera vulnérable.
Les prochaines étapes
La prochaine étape pour les administrateurs de SGBD Oracle est d'inspecter les valeurs SCN de leurs bases de données. Par la suite, l'application du patch de sauvegarde live est cruciale, comme le sont les patchs de suivi qui traitent de la capacité d'augmenter arbitrairement la valeur du SCN via les commandes d'administration. Cependant, puisque des correctifs existent pour les nouvelles versions de la base de données, il doit certainement y avoir un moyen de moderniser les anciennes bases de données pour régler le problème.
Il est également essentiel que les administrateurs DBA évitent soigneusement de connecter des serveurs Oracle non patchés à d'autres bases de données Oracle au sein de leur infrastructure. Ce sera un vrai défi pour toutes les entreprises qui utilisent des versions différentes d'Oracle DBA, mais c'est indispensable pour éviter une corruption du SCN.
Tous les commentaires et les témoignages des spécialistes de la base de données d'Oracle sont les bienvenus.
Témoignage : Oracle Exadata, une machine de consolidation pour Redcats
Venu évaluer les applications de gestion Fusion d'Oracle, à l'automne 2010 sur la conférence OpenWorld, à San Francisco, Frédéric Ndiaye, Responsable Solutions Informatiques du Groupe Redcats (La Redoute Catalogues), découvre sur place l'intérêt suscité par Exadata. Cette appliance, annoncée pour la première fois en 2008, combine des serveurs de bases de données et des systèmes de stockage avec des logiciels optimisés pour exploiter les bases, à la fois pour les applications de datawarehouse et en mode transactionnel (OLTP). En 2010, la solution est présentée dans une 3e version plus puissante, la X2-8, basée sur deux serveurs Sun 8-socket totalisant 128 coeurs Intel et rassemblant jusqu'à 336 téraoctets de stockage brut. « Sur OpenWorld, tout le monde parlait de l'Exadata, en commençant par Larry Ellison le PDG d'Oracle, et il y avait une telle énergie derrière cette machine que j'ai voulu en apprendre davantage », se souvient Frédéric Ndiaye. Ce qui l'intéresse surtout, c'est l'aspect tuning de la solution qui vient booster les performances de l'infrastructure.
Redcats est la holding de la filiale VAD (vente à distance) du groupe PPR. C'est un groupe international de 14 000 collaborateurs qui gère 17 marques parmi lesquelles La Redoute, Vert Baudet, Cyrillus, Somewhere et Daxon. Plus de 54% de ses 3,5 milliards d'euros de chiffre d'affaires sont réalisés sur Internet et la moitié est générée hors de France. Si ses différents services informatiques fonctionnent de façon assez décentralisée, avec des DSI dans chacune des marques, certaines applications partagées sont portées au niveau du groupe pour l'ensemble des marques, explique Frédéric Ndiaye. « Il s'agit principalement du système financier, qui repose sur la E-Business Suite d'Oracle, de la plateforme de conception et de gestion des produits, qui s'appuie sur un outil de PLM, et de la partie connaissance des clients et CRM ». C'est pour cette troisième activité qu'Exadata intéresse le responsable Solutions Informatiques de Redcats. « Nous exploitons des bases de données Oracle avec des outils de datamining IBM Modeler, l'ancien SPSS Clementine, et des logiciels multicanaux Neolane », précise-t-il en indiquant qu'il délivre, dans ce domaine, une prestation à laquelle les marques du groupe peuvent s'abonner. Ce service est géré de A à Z par son équipe (achat des serveurs, des systèmes de stockage et des logiciels, pilotage des équipes projets et de la mise en oeuvre).
Un Proof of Concept non influencé par Oracle
Pour déterminer l'adéquation d'Exadata avec les besoins de Redcats, Oracle France propose un test de faisabilité, un Proof of Concept (PoC) réalisé avec des partenaires. « Nous avons travaillé avec l'intégrateur Overlap dans les locaux d'Altimate qui disposait d'une machine de test ». Sur cette étape, Frédéric Ndiaye entend garder une marge de manoeuvre importante. « Je ne voulais pas être téléguidé. Dans certains PoC, on vous demande d'envoyer toutes vos requêtes à l'avance et lorsque l'on arrive, tout fonctionne bien, mais on ignore finalement s'il n'y a pas eu certains ajustements. » Oracle joue le jeu et accepte un scénario comportant une dose d'improvisation, avec des requêtes non connues.
Les tests s'effectuent sur des données sensibles qu'il faut au préalable rendre anonymes. « C'est un énorme travail que nous avons fait avec Overlap, souligne le responsable informatique. Il nous fallait des données complètement anonymes, mais qui conservent néanmoins une signification pour que le PoC ait un sens. »
Frédéric Ndiaye, Responsable Solutions Informatiques du Groupe Redcats.
[[page]]
Oracle avait proposé deux options pour le test. Celui-ci pouvait s'effectuer en Ecosse, dans un centre Oracle, sur le modèle d'appliance Exadata que Redcats voulait acquérir, le X2-2. Ou bien en France, sur une version antérieure, la V2. Mais dans le premier cas, il aurait fallu envoyer toutes les requêtes à l'avance ce qui, pour Frédéric Ndiaye, était exclu. « Je voulais vraiment bénéficier de l'effet de surprise. Nous avons donc choisi de réaliser le PoC sur l'ancien Exadata, afin de garder notre liberté de manoeuvre, plutôt que de gagner 10 à 15% de performances sur les tests car cela ne se jouait plus à cela ».
Des temps de réponse divisés par 6
Overlap a assisté l'équipe informatique de Redcats sur le chargement des données dans l'Exadata en déroulant un scénario mis au point sur le serveur de production en cours d'utilisation dans le groupe de VAD. « Nous avons ainsi pu mesurer les différences », relate Frédéric Ndiaye. « Nous avons tout comparé. Je n'avais pas trop de doutes sur la partie datawarehouse et sur les grosses requêtes car, sur ce plan, nous disposions de nombreux retours de performances de la part des clients d'Oracle déjà équipés d'Exadata. J'étais à peu près sûr d'obtenir un gain important. Nous avons néanmoins fait des requêtes de ce type pour être fixés. »
Mais c'est sur les requêtes OLTP que Redcats concentre surtout ses tests, ainsi que sur les requêtes mixtes, car il n'y avait pas beaucoup de retours clients dans ces domaines. « Nous avons, en fait, un système consolidé avec un mix de requêtes OLTP qui s'effectuent en même temps que l'exploitation du datawarehouse. C'est ce qu'il nous fallait valider. »
Sur l'ensemble du test, les temps de réponse ont été divisés par six en moyenne, révèle Frédéric Ndiaye. Ce qui sous-entend des mesures supérieures sur le datawarehouse, « forcément à l'avantage de l'Exadata », et des résultats un peu inférieurs sur le transactionnel. « J'ai été très attentif aux mesures de ce mix. Je voulais savoir si la base tenait le choc lorsque l'on faisait tout fonctionner en même temps. Or, plus on faisait tourner de scripts, plus la différence se creusait avec le système que nous utilisions. C'était positif. » Les montées en charge s'avéraient en outre beaucoup plus linéaires sur l'appliance d'Oracle que sur les machines de Redcats. « Pour moi, l'Exadata est une vraie machine de consolidation, estime aujourd'hui le responsable informatique. Cela signifie que vous pouvez y installer énormément d'applications et qu'elle délivre toujours à peu près la même performance ».  Les différentes configurations et possibilités d'évolution sur le modèle X2-2 de l'Exadata Database Machine (cliquer ici pour agrandir l'image). Crédit : Oracleace
Les différentes configurations et possibilités d'évolution sur le modèle X2-2 de l'Exadata Database Machine (cliquer ici pour agrandir l'image). Crédit : Oracleace
[[page]]
Datamining, ciblage et création de campagnes
Fin juin 2011, un quart de rack Exadata X2-2 est en place chez Redcats. Actuellement, une cinquantaine de personnes y accèdent pour exploiter intensivement les données. Il s'agit d'utilisateurs intervenant dans les directions marketing, répartis en deux catégories. D'une part, des dataminers qui procèdent à des requêtes intensives avec le logiciel IBM Modeler. « Ils effectuent des analyses de données sur de gros volumes et font beaucoup de ciblage avec cet outil complet qui constitue vraiment le coeur de la solution », explique Frédéric Ndiaye. D'autre part, il y a les utilisateurs des outils Neolane, comprenant différents profils, à l'origine des campagnes d'e-mailing. On trouve parmi eux des cibleurs qui font également de grosses requêtes sur les clients pour trouver les cibles. Et puis, ceux qui vont créer les campagnes, visuellement, et vont interagir avec les sites web. « Aujourd'hui, toute la communication avec les clients part de l'Exadata, résume le responsable informatique. Toutes les études, tous les ciblages, toutes les sélections, l'e-mail, le papier. »
Dataminers et cibleurs représentent la moitié des utilisateurs de l'Exadata, les équipes web constituant l'autre moitié. Tous exploitent continuellement l'appliance, sans restriction. « Nous fournissons un système et il doit tenir le choc », assène Frédéric Ndiaye.
Une capacité totale loin d'être atteinte
L'Exadata est venu remplacer des systèmes de stockage IBM, et des serveurs Power 6 et 7. Redcats a choisi le modèle quart de rack de l'appliance d'Oracle, une configuration haute performance qui lui permet de stocker au total de 6 à 7 téraoctets en mode compressé. Une capacité loin d'être atteinte. « Il y a de la place pour installer d'autres projets sur cette plateforme. Je la considère vraiment comme une machine de consolidation sur laquelle je mettrai les prochaines applications, même si elles n'ont pas besoin de cette puissance ».
La mise en place de l'appliance était avant tout destinée à apporter aux équipes marketing un environnement beaucoup plus favorable en termes de puissance de calcul. « Elles réalisent des campagnes de plus en plus ciblées et analysent donc de plus en plus de données. Il fallait changer les serveurs gérant la partie Neolane, car nous avions du mal à tenir nos engagements. Partant de là, nous nous sommes placés dans une démarche globale plutôt que ponctuelle qui aurait consisté à remplacer une machine ici ou une autre là ». Mais demain, si un projet applicatif Oracle arrive, « il ira sur l'Exadata. Ce n'est pas négociable. Dans le cas contraire, il faudrait racheter des serveurs, d'autres licences... »
Neuf millions de clients actifs pour La Redoute (ayant commandé il y a moins de deux ans). En considérant ce nombre, on imagine que même très ciblés, les e-mails envoyés représentent un volume énorme, sur lequel Redcats ne communique pas. « Nous travaillons beaucoup sur la personnalisation, nous essayons de ne pas augmenter le volume d'envoi. L'idée, c'est d'apporter de la valeur aux clients ».
[[page]]
Des économies sur l'infogérance
L'acquisition d'un système Exadata représente un investissement financier très important. Pour le modèle quart de rack de l'Exadata Database Machine X2-2, le prix communiqué par Oracle sur son site indique 330 000 dollars au 6 décembre 2011 et 39 600 dollars pour le support Premier du système. Il s'agit d'un prix catalogue, en dehors de toute négociation commerciale, mais il donne une indication sur le budget à envisager pour ce type d'acquisition (les taux de remise sur le matériel sont généralement moins élevés que sur le logiciel). Interrogé sur le coût de l'opération, le responsable informatique ne fournit pas de chiffres, tout en reconnaissant qu'il s'agit d'un projet très important. « Mais, paradoxalement, il faut tout mettre dans l'équation », tient-il à préciser. Il explique ainsi être passé par plusieurs étapes. Après avoir trouvé la solution particulièrement intéressante en la découvrant sur la conférence OpenWorld, il a rapidement jugé qu'elle était trop chère pour son budget, avant de travailler le sujet avec Oracle. « Il faut tenir compte des économies, explique-t-il. En la positionnant comme une machine de consolidation, avec les gains de fonctionnement que nous pouvions capter, nous arrivons à une équation économique qui était très bonne. Nous faisons par exemple des économies sur l'infogérance. »
Les données étant compressées, la volumétrie est moindre, ce qui réduit les sauvegardes. « Lorsque vous avez un prix au Go sauvegardé, votre facture baisse. Or, ma facture de sauvegarde était assez conséquente, la réduction porte donc sur de grosses sommes. Ensuite, ainsi que je l'ai dit, la plateforme dispose encore d'une place importante pour consolider d'autres systèmes. Economiquement, c'est une solution que je trouve rentable ».
Un projet moins ardu en partant d'un cluster
Sur le coût d'achat, les niveaux de remise accordés par Oracle sont moindres par rapport à ceux d'autres constructeurs. Quant au coût de l'intégration, il est lié à la durée du projet. Or, celui-ci, en dépit de sa complexité, fut très ramassé. « Nous avons reçu la machine et moins de deux mois plus tard, notre plus grosse base y avait été migrée par notre intégrateur, Overlap. Cela représentait pourtant un gros changement car nous n'utilisions pas de serveurs en cluster jusque-là, mais des serveurs stand alone », décrit Frédéric Ndiaye. « Or, en termes de technologies, il est beaucoup plus facile de passer à l'Exadata lorsque vous venez d'une installation en RAC [Real Application Cluster] que lorsque utilisiez des serveurs stand alone. »
La première base de données a été de loin la plus complexe à migrer car de nombreuses options y avaient été actionnées pour doper la performance. Pour les autres bases, ce fut beaucoup plus facile. En revanche, le responsable informatique insiste sur les efforts requis pour insérer l'Exadata dans l'infrastructure IT de Redcats, pour le faire communiquer avec les applications, avec les firewalls, avec le réseau, etc. Il faut passer par des liens qui n'existaient pas forcément, bien analyser l'architecture, savoir identifier ce qui manque, ce qui risque de bloquer... « Il est nécessaire de travailler avec des équipes qui comprennent l'appliance dans son ensemble. L'installation d'un Exadata ne s'improvise pas », conclut-il.
22 outils gratuits pour visualiser et analyser les données (2ème partie)
Pour faire parler des données, rien ne vaut une panoplie d'outils de visualisation graphique. Pour ceux dont le budget est limité, il existe de nombreux outils gratuitement accessibles pour visualiser les données et faire apparaître des modèles ou des tendances. Au printemps dernier, Sharon Machlis, de Computerworld, en a listé plus de vingt, qu'elle a répartis en neuf catégories : nettoyage de données, analyse statistique, outils et services de visualisation (1ère partie publiée le 3 janvier), outils de développement, SIG, analyse de données temporelles, nuages de mots, visualisation de données relationnelles (2e partie). Les bibliothèques JavaScript et les interfaces de programmation (API) s'adressent aux développeurs.
Pour relire la 1ère partie, «22 outils gratuits pour visualiser et analyser les données»
- Assistants, bibliothèques et API
Il faut quelquefois écrire du code pour produire certaines visualisations, en particulier quand le type d'affichage que l'on veut obtenir ne peut être réalisé qu'en recourant à une application desktop ou web existante. Cela ne signifie pas que l'on doive partir de rien, plusieurs bibliothèques et API fournissant déjà divers éléments.
10 - Choosel : pour enrichir les applications Google Web Toolkit
Ce framework Open Source disponible en mode web est destiné à la réalisation de graphiques sectoriels, de nuages, d'histogrammes, de diagrammes chronologiques et de cartographies. Il s'adresse davantage aux développeurs qu'aux utilisateurs. On peut néanmoins consulter une démo interactive qui explique comment importer des données en utilisant des fichiers CSV. Disponible sous licence Apache 2.0, il a trois champs d'applications principaux : l'exploration visuelle de données, les infographies interactives, la visualisation de données dans les applications GWT (le framework de développement Java Google Web Toolkit), peut-on lire sur code.google.com.
Comme avec Tableau Public, plusieurs visualisations peuvent s'afficher sur une page en étant reliées, de telle sorte que l'on peut, par exemple, mettre en valeur certaines données sur une carte en passant la souris sur un graphique associé.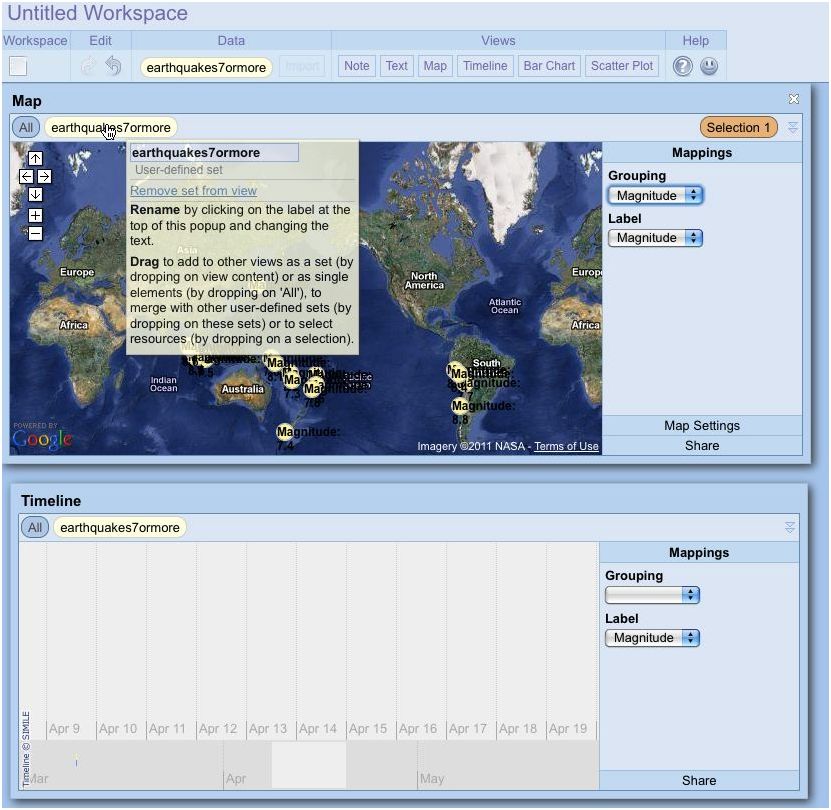
Choosel (cliquer ici pour agrandir l'image)
Niveau de compétences requis : Expert.
Fonctionne à partir de Chrome, Safari et Firefox.
En savoir plus : http://code.google.com/p/choosel/
11 - Exhibit : une bibliothèque JavaScript
Issu du projet Simile conduit par le MIT, le logiciel Open Source Exhibit, sous licence BSD, permet de « créer facilement des pages web comportant des fonctionnalités de recherche et de filtrage, des cartographies interactives, des échelles chronologiques et autres visualisations », décrit le site Simile-widgets.org/exhibit. Présenté comme un framework de publication, cette bibliothèque JavaScript permet d'ajouter facilement des filtres et des recherches. Sharon Machlis, de Computerworld, fait néanmoins remarquer que ce qui est jugé « facile » par les professionnels du MIT ayant créé Exhibit peut ne pas l'être autant pour un utilisateur qui connaît surtout Excel. Comme la plupart des bibliothèques JavaScript, Exhibit requiert d'écrire davantage de lignes de code que des services tels que Many Eyes et Google Fusion Tables. Cela dit, il propose une documentation claire pour les débutants, même pour ceux qui n'ont pas d'expérience JavaScript.
Si l'écriture de code ne vous pose pas de problèmes, vous avez des chances de vous approcher au plus près des présentations que vous voulez réaliser. Et vos données restent stockées localement, sauf si vous souhaitez les publier. Pour les novices, il faudra un peu de temps pour se familiariser avec l'écriture de code et la syntaxe de la bibliothèque.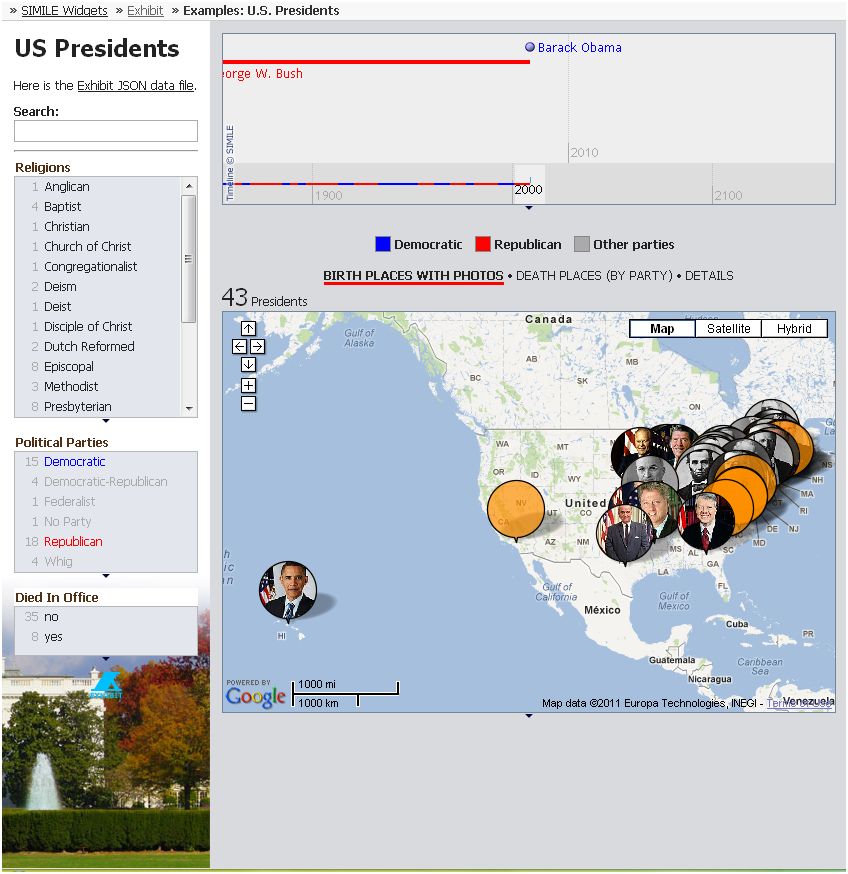
Exhibit (cliquer ici pour agrandir l'image)
Niveau de compétences requis : Expert.
En savoir plus : http://www.simile-widgets.org/exhibit/
12 - Google Chart Tools : des graphiques statiques et interactifs
Contrairement à Google Fusion Tables qui est comme une application à part entière pour stocker des données en ligner et générer graphiques et cartes, Chart Tools est conçu pour visualiser des données résidant ailleurs, par exemple sur un site web ou au sein de Google Docs. Il offre à la fois les API Chart utilisant une simple requête URL vers un serveur de graphiques Google pour créer une image statique, et l'API Visualization qui accède à une bibliothèque JavaScript pour bâtir des graphiques interactifs. Avec celle-ci, on n'échappe pas à l'écriture de code. Google donne des informations (taille des données, compétences requises...) pour déterminer quelle option retenir.
Pour les graphiques statiques les plus simples, un assistant fournit quelques exemples. Il va jusqu'à aider à saisir les données ligne par ligne, quoi qu'à partir d'une certaine taille, il est plus logique de formater celles-ci dans un fichier texte.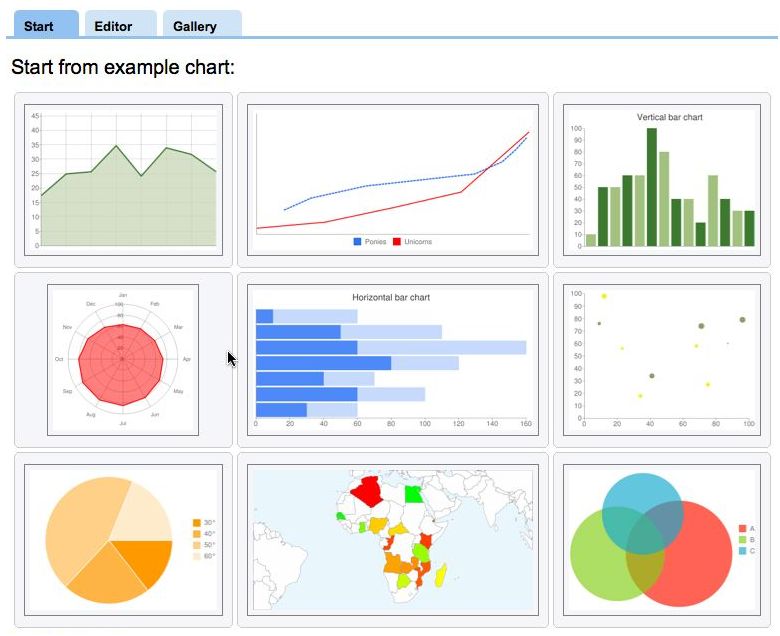
Google Chart Tools (cliquer ici pour agrandir l'image)
Niveau de compétences : débutant avancé et expert.
Fonctionne sur tout navigateur.
En savoir plus : http://code.google.com/apis/chart/image/docs/making_charts.html
[[page]]
13 - JavaScript InfoVis Toolkit : de superbes graphiques
InfoVis ne compte sans doute pas parmi les bibliothèques de visualisation JavaScript les mieux connues, mais elle vaut vraiment la peine d'y jeter un oeil si vous voulez permettre la consultation de données interactive sur le web. Elle a été utilisée par la Maison Blanche pour créer le graphique présentant le budget de l'administration Obama.
Ce qui différencie cet outil des autres est l'apparence très léchée des graphiques qu'il réalise avec des exemples simples de code. Visiblement, le créateur d'InfoVis, Nicolas Garcia Belmonte, développeur senior chez Sencha Inc, s'intéresse autant à l'esthétique du dessin qu'à celle du code et ça se voit.
Les échantillons présentés sont superbes. On peut télécharger uniquement le code pour les types de visualisations que l'on veut utiliser pour réduire la taille des pages web. Attention, comme il ne s'agit pas d'une application mais d'une bibliothèque de code, il faut savoir développer pour l'utiliser. Par conséquent, cela peut ne pas convenir à des utilisateurs en entreprise qui analysent les données mais ne savent pas programmer. Par ailleurs, le choix du type de visualisation est limité. Enfin, les données doivent être au format JSON.
InfoVis Toolkit (cliquer ici pour agrandir l'image)
Niveau de compétences : expert.
Fonctionne sur les navigateurs compatibles JavaScript.
En savoir plus : démos avec code source (http://thejit.org/demos/)
14 - Protovis : une bibliothèque bien documentée
Présenté comme un toolkit graphique pour la visualisation, ce projet de l'Université de Stanford est l'une des bibliothèques JavaScript les plus populaires pour transformer les données en visuels. Une des choses les plus intéressantes à propos de cet outil est sa documentation. Celle-ci comporte de nombreux exemples des types de visualisation disponibles, incluant des cartes et quelques analyses statistiques. C'est un bon outil, permettant de construire des représentations telles qu'une carte associée à une échelle chronologique.
De la même façon qu'avec les autres bibliothèques JavaScript, il faut connaître ce langage (ou tout au moins être familier d'un autre langage). Même s'il est possible de copier, coller et modifier du code sans vraiment comprendre ce que l'on fait, il est difficile de recommander cette approche à des non-techniciens.
Protovis (cliquer ici pour l'image)
Niveau de compétences : expert.
Fonctionne sur les navigateurs compatibles JavaScript.
En savoir plus : comment démarrer avec Protovis
- Les systèmes d'information géographique sur poste de travail
Il existe de nombreuses applications pour les SIG (systèmes d'information géographique), allant de l'affichage des sites d'extraction pétrolier au choix de nouvelles implantations pour des magasins. Comme le Miami Herald l'a fait (le magazine a obtenu le prix Pulitzer pour sa couverture de l'ouragan Andrew), il est possible de comparer les vitesses maximum des bourrasques avec les dégâts constatés (pour s'apercevoir, par exemple, que les dommages les plus importants n'ont pas été subis dans les zones où le vent a été le plus fort, mais dans des endroits nouvellement construits où les constructions n'étaient pas de bonne qualité).
15 - Quantum GIS (QGIS) : une alternative à ArcView
C'est un SIG à part entière, conçu pour créer des cartes et qui permet des analyses de données détaillées et avancées par zones géographiques. L'application SIG desktop la plus connue est sans doute ArcView, d'Esri, qui coûte un certain prix, mais s'accompagne d'un solide support professionnel. L'alternative Open Source est QGIS, comme OpenOffice peut l'être pour Microsoft Office. A noter qu'Esri a récemment lancé une offre découverte de son SIG pour un usage privé. Les passionnés d'ArcView considèrent qu'Esri offre deux ans d'avance sur ses alternatives Open Source, que son interface est meilleure et qu'il est mieux adapté pour les impressions. De leur côté, les utilisateurs de QGIS soulignent l'excellence du produit Open Source et pointent ses performances lorsqu'il est question de générer des cartes pour le web, grâce à un plug-in spécialisé dans la génération d'images de cartes en HTML.
Quoi qu'il en soit, avec tout SIG avancé, apprendre le maniement du logiciel demande un sérieux engagement. Cela prend du temps. Certaines choses sont plus faciles à faire avec la version commerciale ArcView, a noté pour sa part Sharon Machlis, de Computerworld, qui a pris en main ArcView et QCIS. Elle explique qu'ArcView dispose d'une fonction normalisée pour calculer, par exemple, le pourcentage de personnes de 65 ans et plus au sein d'une population dans une table comportant les deux colonnes. Dans QGIS, il lui fallait appeler un champ calcul et créer une nouvelle colonne avec la formule pour l'obtenir.
Quantum GIS (cliquer ici pour agrandir l'image)
Niveau de compétences : Intermédiaire et expert.
Fonctionne sur Linux, Unix, Mac OS X et Windows. L'installation sur OS X nécessite la mise en place de plusieurs compléments.
En savoir plus : http://www.plantsciences.ucdavis.edu/plant/qgislabs.htm
On trouve d'autres solutions SIG en Open Source sur Spatialanalysisonline.com. A regarder aussi, un outil comme Post-GIS qui permet d'ajouter des objets géographiques à la base de données relationnelle PostgreSQL.
[[page]]
- Les solutions de cartographie en ligne
Certains outils de cartographie en ligne sont devenus très populaires. Celui de Google, bien sûr, qui dispose en outre de plusieurs compléments tels que Map A List, un add-on qui ajoute à une carte Google Map des données provenant d'un tableur. Il y a aussi Yahoo Maps Web Services, et Bing Maps, de Microsoft qui comportent également des API. Il en existe beaucoup d'autres venant de petites sociétés ou de contributeurs Open Source individuels : des outils, entièrement développés en partant de zéro, pour afficher des données sur des cartes géographiques.
16 - OpenHeatMap : des cartes en couleurs très faciles à créer
Ce site web convivial génère des cartes dont les couleurs se modifient en fonction des informations sous-jacentes : l'évolution d'une population ou d'un revenu moyen, par exemple. On peut aussi placer sur une carte des marqueurs dont la taille varie en fonction des données qui figurent dans la table associée.
En plus de fournir ce service sur le web, son auteur Pete Warden (qui fut un temps développeur chez Apple, notamment sur Final Cut Studio) a également packagé OpenHeatMap sous la forme d'un plug-in JQuery pour ceux qui ne veulent pas dépendre de l'hébergement de OpenHeatMap.com. Toutefois, tous les formats de données ne fonctionnent pas correctement lorsqu'ils sont stockés localement. Pete Warden conseille d'intégrer les cartes depuis le site.
Selon Sharon Machlis, de ComputerWorld (qui a dressé cette liste il y a quelques mois), il est très facile de créer rapidement une carte en couleurs à partir de nombreuses sources de données de localisation, même des adresses IP. « Cela m'a pris environ 60 secondes pour créer une carte présentant les séismes de magnitude 7 et plus dans le monde depuis janvier 2000 », indique-t-elle dans son article (cf image ci-dessous). Les tailles, les couleurs et la transparence des marqueurs se personnalisent aisément.
Inconvénient signalés : les données ne peuvent pas être supprimées une fois mises en ligne.
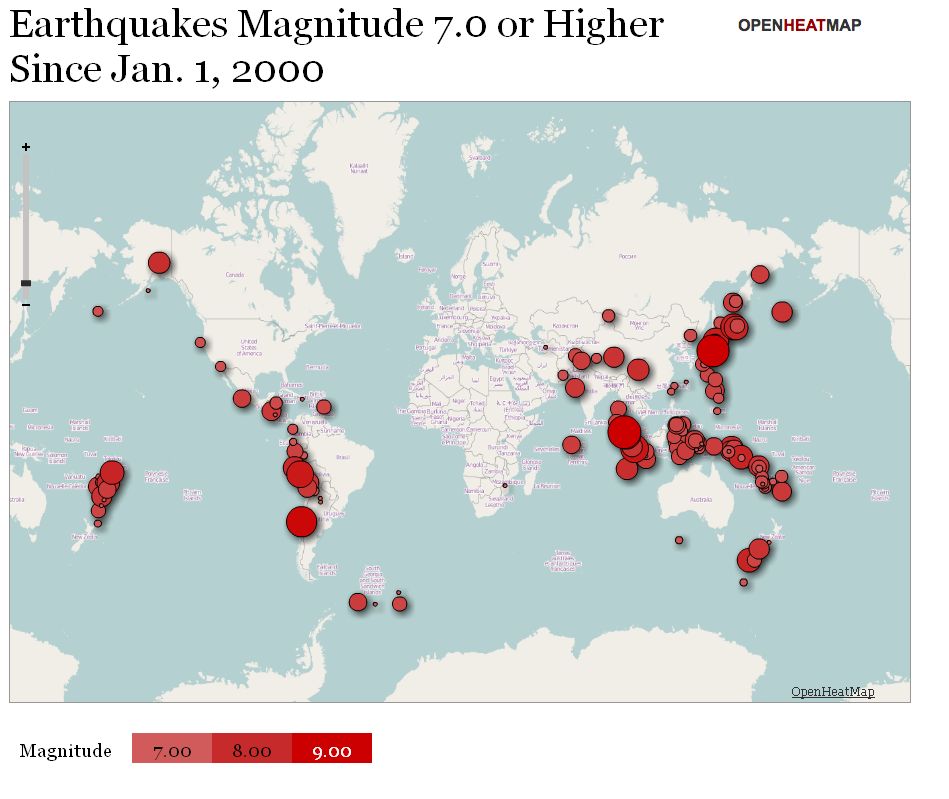
OpenHeatMap (cliquer ici pour agrandir l'image)
Niveau de compétences : débutant.
Fonctionne sur les navigateurs web compatibles Flash ou HTML 5 Canvas.
En savoir plus : http://www.openheatmap.com/gallery.html
17 - OpenLayers : insérer des cartes dans des pages web
Cette bibliothèque JavaScript pour intégrer des cartes d'informations dynamiques dans des pages web. Elle fonctionne avec OpenStreetMap et d'autres services comme Google Street View. Il est destiné à apporter des fonctionnalités similaires à celles de ces bibliothèques, mais en Open Source. D'autres projets s'en servent pour ajouter des fonctionnalités ou une facilité d'utilisation. C'est le cas de GeoExt qui l'utilise pour apporter des fonctions SIG. OpenLayers peut intéresser les utilisateurs qui connaissent JavaScript et préfèrent se tourner vers une option non commerciale (plutôt que recourir à Google ou Bing).
Niveau de compétences : expert
Fonctionne sur tout navigateur web.
En savoir plus : http://openlayers.org/
Il y a d'autres bibliothèques JavaScript pour incruster des informations sur les cartes, telles que Polymaps. Il existe également d'autres plateformes de cartographies : Google Maps et ses nombreuses API, Yahoo Maps Web Services, Bing Maps et GeoCommons.
18 - OpenStreetMap : une cartographie communautaire
C'est un peu le Wikipedia de la cartographie, doté de fonctions de routes ou d'immeubles auxquelles ont contribué différents utilisateurs dans le monde. L'intérêt principal, c'est son caractère communautaire qui a débouché sur des utilisations intéressantes. Il est par exemple compatible avec la plateforme mobile Ushahidi http://www.ushahidi.com/
utilisée pour récupérer des informations après les tremblements de terre en Haïti et au Japon (alors que Ushahidi peut utiliser plusieurs fournisseurs pour les couches cartographiques, en incluant Google et Yahoo, certains créateurs de projets se sentent plus à l'aise avec des solutions en Open Source).
Inconvénients : Comme pour tout projet acceptant les contributions publiques, il peut y avoir des problèmes d'exactitude certaines fois sur les informations fournies (sur le positionnement de certains services sur les cartes, par exemple). Quoi que ce genre de choses peut arriver avec Google Maps. Par ailleurs, l'apparence des cartes est moins bonne que celles des produits commerciaux concurrents.
OpenStreetMap.org (cliquer ici pour agrandir l'image)
Niveau de compétences : débutant avancé et intermédiaire
Fonctionne sur tout navigateur web.
En savoir plus : http://www.openstreetmap.org/
http://openstreetmap.fr/
[[page]]
- Analyse de données temporelles
19 - TimeFlow : les concepteurs du projet ont rejoint Google
Ce logiciel pour poste de travail a été développé pour analyser des données ayant une composante temporelle. Ses créateurs, Fernanda Viégas et Martin Wattenberg (tous deux se trouvant derrière le projet Many Eyes d'IBM) ont créé la société Flowing Media, un studio de visualisation spécialisé sur les groupes médias et les projets grand public http://hint.fm/about/. Ils ont rejoint Google en 2010 pour diriger son groupe de visualisation de données Big Picture.
TimeFlow (cliquer ici pour agrandir l'image)
En savoir plus : https://github.com/FlowingMedia/TimeFlow/wiki
- Les nuages de mots et de textes
Certaines spécialistes de la visualisation de données n'aiment guère ces nuages qui affichent les mots d'un fichier texte en faisant varier leur taille en fonction du nombre de fois où ils figurent dans le fichier. Ils ne les trouvent pas sérieux ou jugent qu'ils ont été trop utilisés. Ceux qui veulent néanmoins y recourir peuvent se tourner vers trois outils.
20 - IBM Word Cloud Generator : dans Many Eyes
Plusieurs des outils déjà cités dans la liste établie par Computerworld permettent de créer des nuages de mots. C'est le cas de l'API Visualization de Google et de Many Eyes où l'on trouve Word-Cloud Generator. On peut aussi le faire avec Wordle http://www.wordle.net/ (un outil pratique pour créer ces nuages à partir de sites web plutôt que de fichiers texte).
Word Cloud Generator dans Many Eyes (cliquer ici pour agrandir l'image)
- Outils d'analyse de réseaux sociaux
Ces outils se réfèrent à la définition SNA (social network analysis) pré-Facebook/Twitter. Ils servent à rechercher des liens entre des individus en s'appuyant sur différents jeux de données. Il est nécessaire d'avoir des notions de statistiques pour les utiliser.
21 - Gephi : pour établir des relations dans un réseau complexe
Présenté comme un Photoshop pour les données. Ce projet Open Source est conçu pour visualiser des informations statistiques, incluant des relations au sein de réseaux de type graphe comptant jusqu'à 50 000 noeuds et un demi-million de connexions, de même que l'analyse de facteurs tels que l'intermédiarité, la proximité auxquels s'ajoute un coefficient d'agglomération.
Gephi (cliquer ici pour agrandir l'image)
Fonctionne sur Windows, Linux, Mac OS X avec Java 1.6
En savoir plus : http://gephi.org/
22 - NodeXL : plug-in pour Excel pour explorer Twitter et Flickr
Ce plug-in pour Excel affiche des graphes de réseaux à partir d'une liste de connexions, afin d'aider à dégager des modèles et des liens entre les données. NodeXL combine l'ancienne et l'actuelle définition de SNA. Il est optimisé pour analyser les médias sociaux en ligne. Il intègre notamment des connexions pour appeler les API de Twitter, Flickr et YouTube, ce qui permet de dessiner des réseaux d'utilisateurs et leurs activités, explique Peter Aldhous, responsable du bureau de San Francisco du magazine New Scientist.
NodeXL (cliquer ici pour agrandir l'image)
Fonctionne sur Excel 2007 et 2010 sur Windows.
En savoir plus : http://nodexl.codeplex.com/
Base de données : SAP vise désormais la place de numéro 2
Le projet HANA, dont la paternité revient au fondateur de SAP, Hasso Plattner, et au CTO, Vishal Sikka, a été initialement présenté au milieu de l'année 2010 comme une plateforme permettant d'exécuter des charges de travail analytique beaucoup plus rapidement qu'avec les bases de données traditionnelles. Selon SAP, ce mode de fonctionnement où le système inscrit les données qu'il doit traiter en RAM, au lieu de les lire sur les disques, permet des gains en performance significatifs, voire très impressionnants.
Mais, rapidement, SAP a commencé à évoquer la capacité de HANA à gérer des charges de travail transactionnelles dans le domaine de l'ERP (Enterprise Resource Planning) et dans d'autres types d'applications, le positionnant comme une alternative éventuelle à certains produits, notamment la base de données phare d'Oracle. « C'est une opportunité très stimulante, parce qu'elle ouvre sur la possibilité de développer des applications totalement nouvelles », a déclaré Vishal Sikka à la keynote qu'il a donné à l'Influencer Summit de Boston. Sur une diapositive, il a montré la future pile logicielle basée sur HANA. À la base de la pile se trouvent HANA et les services d'infrastructure et de gestion du cycle de vie associés. Viennent ensuite les services d'applications, puis ABAP et les services de la plateforme Java, surmontés par les environnements de développement, et enfin les applications construites par SAP et celles des vendeurs tiers.
SAP bientôt numéro 2 dans les SGBD ?
SAP trace aussi d'autres perspectives, annonçant une série d'initiatives en relation avec HANA de la part de vendeurs de middleware et d'analytiques comme Tibco, du fournisseur d'ERP UFIDA, du vendeur de visualisation de données BI (business intelligence) Tableau and Jive Software, connu pour ses solutions de réseau social pour l'entreprise. « Dorénavant, SAP entend disposer d'un « écosystème tout à fait ouvert » pour HANA, » a indiqué Vishal Sikka. Cela paraît logique, bien sûr, étant donné que HANA est un produit relativement nouveau qui a beaucoup de choses à rattraper pour se mettre au niveau d'Oracle et d'autres. Cela n'a pas empêché un autre responsable de SAP de faire une prédiction très optimiste, mardi, après la keynote de Vishal Sikka. « Retenez-ce que je vais vous dire : en 2015, nous serons le deuxième vendeur de bases de données sur le marché, » a déclaré Steve Lucas, Global General Manager Business analytics and technology. « Je sais qui nous devons dépasser. Ce ne sont pas de petits acteurs. Il va nous falloir quelques années et beaucoup d'ingénierie pour y arriver. Mais nous le ferons. »
« SAP va également chercher à conclure des partenariats avec des éditeurs de logiciels qui intégreront HANA dans leurs produits, » a ajouté Steve Lucas. Une autre bonne manière pour SAP d'avancer vers son objectif serait d'ajouter le support HANA pour son logiciel phare Business Suite, dont de nombreuses mises en oeuvre fonctionnent sur Oracle. « Ce travail est en cours, et comme aucune date d'achèvement n'a été fixée, on peut s'attendre à une mise à jour pour la conférence Sapphire de l'année prochaine, » a déclaré Sethu Meenakshisundaram, CTO adjoint de SAP. « C'est un projet de première importance et nous avançons. » SAP n'a pas encore décidé « si elle vendra aussi HANA comme base de données autonome, » a encore déclaré Vishal Sikka dans une interview.
Déjà 100 millions de dollars de vente pour HANA
« En attendant, SAP a récemment franchi une étape avec HANA, dépassant les 100 millions de dollars de ventes, » comme l'a révélé le directeur technique de SAP au cours de sa keynote. HANA est vendu sous forme d'appliance par un certain nombre de fabricants. « Les 100 millions de dollars ne prennent en compte que les revenus de licence du logiciel de SAP, » a aussi précisé Vishal Sikka dans son interview. « Autre signe du succès de HANA, dans toutes les régions du monde, les clients ont racheté d'autres produits intégrant le système, » a ajouté le dirigeant. « CSC, l'un des leaders mondiaux dans le conseil, l'intégration de solutions d'entreprise et l'externalisation devrait adopter HANA, » a déclaré David McCue, vice-président et CIO de CSC, dans une interview. « La première instance de production concernera environ 1 téraoctet de données, mais CSC réfléchit, encore à quel type d'usage elle sera affectée, » a-t-il ajouté.
« HANA est un produit jeune, mais c'est aussi une solution viable, » a encore déclaré le CIO de CSC. « Nous sommes suffisamment confiants pour l'acheter, et nous réaliserons plusieurs mises en oeuvre pour le compte de nos clients, » a-t-il ajouté. Ce dernier a aussi donné un point de vue mesuré sur le projet à long terme envisagé par SAP pour HANA. « S'il est matériellement réalisé, le produit aura un très bon retour, » a-t-il estimé. « Sans aucun doute, HANA a montré dans sa version actuelle qu'il avait assez de ressources pour qu'on s'y intéresse. Mais comme toute prospective à long terme, celle-ci pourrait être contredite par les événements. »
[[page]]
Hier à Boston, SAP a également abordé la question de sa stratégie logicielle dans le cloud computing, récemment agitée par le rachat de SuccessFactors pour 3,4 milliards de dollars. C'est le PDG du vendeur de logiciels de gestion des ressources humaines à la demande, Lars Dalgaard, qui sera placé à tête de l'activité cloud de SAP une fois la transaction achevée. Cette acquisition intervient après plusieurs années pendant lesquelles SAP s'est employé à peaufiner précisément son approche du logiciel dans le cloud. Cela n'a pas été une mince affaire pour un éditeur comme SAP, dépendant du modèle de logiciel sur site et du flux de revenus prévisibles et lucratifs rapportés par le renouvellement perpétuel des licences et les services de maintenance. Ce concept a du être bouleversé et remplacé par un système d'abonnement, devenu le standard du cloud.
« Mais SAP a encore le temps de voir venir, et l'expérience de SuccessFactors va être un atout majeur, » a déclaré Jim Hagemann Snabe, le co-CEO, lors d'un discours liminaire. « 80% des clients importants n'ont pas fait leur choix de stratégie pour le cloud, et pensent encore en terme de cloud privé. On voit aussi que les applications de pointe sont encore confiées à des services de cloud public. » « La combinaison de nos actifs et de SuccessFactors transforme une entreprise qui a essayé de bien faire les choses... en une entreprise qui va croitre rapidement dans le monde, » a-t-il ajouté. « Nous passons aussi d'un mode défensif, à un mode offensif. »
(...)(06/12/2011 09:38:54)Oseo repense sa gestion des données non-structurées
L'entreprise publique Oseo qui investit dans les entreprises innovantes et participe ainsi à leur développement, utilise une GED qui dispose d'un moteur de recherche interne. Mais ce dernier ne donnait pas satisfaction. D'une part son indexation était limitée au seul Intranet. D'autre part, la qualité des informations remontées était insuffisante avec un taux de bruit trop important.
Oseo a donc cherché à se doter d'un moteur de recherche plus transversal et délivrant des informations plus pertinentes. Après différents tests, l'organisme a choisi Enterprise Search de Polyspot. Ce moteur indexe désormais la totalité des documents non-structurés de l'entreprise et les rend disponibles au travers d'une interface intuitive accessible via un gadget du bureau Windows. Les résultats remontés sont plus pertinents qu'auparavant et il est possible d'affiner via la notion de « facettes ».
Le projet devrait être étendu dans les mois à venir à d'autres sources de données comme les espaces collaboratifs. Le coût du projet n'a pas été dévoilé.
| < Les 10 documents précédents | Les 10 documents suivants > |