
L’équipe du laboratoire parisien de Facebook AI Research, créé il y a tout juste cinq ans, vient de publier sur arxiv.org un article sur la traduction non supervisée des langages de programmation. Ces travaux de recherche, menés par Marie-Anne Lachaux, Baptiste Roziere, Lowik Chanussot et Guillaume Lample, portent sur un modèle de transcompilateur neuronal, Transcoder, destiné à convertir du code source à partir d’un langage de développement de haut niveau tel que C++ ou Python. En mettant à profit les approches récentes de traduction machine non supervisée, l’équipe a montré qu’il était possible de traduire avec une grande précision des fonctions entre du code C++, Java et Python. Son modèle a été entraîné sur le code de projets open source gérés sur GitHub.
Les applications concrètes de ces travaux consistent à pouvoir « convertir du code écrit dans un langage lent à l’exécution, comme Python, vers un langage plus rapide comme le C ou le C++ », nous a expliqué l'un des chercheurs de Facebook AI Research, Guillaume Lample, contacté par mail. Ou bien de convertir des programmes et librairies de code écrits dans des langages vieillissants, comme Cobol (60 ans mais toujours vert) ou autres, dans des langages plus modernes. Habituellement, les transcompilateurs utilisés pour porter des lignes de code d’un langage vers un autre s’appuient sur des règles de réécriture manuelle appliquées à l’arbre de la syntaxe abstraite du code source. Ainsi que le rappelle l’article de Facebook AI Research, le résultat obtenu manque souvent de lisibilité et ne respecte pas vraiment les conventions du langage cible, ce qui nécessite des corrections manuelles, prend beaucoup de temps et augmente par conséquent le coût du portage. Et même si les modèles neuronaux font mieux que ces transcompilateurs basés sur des règles, leurs applications ont été limitées en raison de la rareté de données parallèles dans ce domaine.
Basé sur les méthodes conçues pour traduire les langues naturelles
« Notre méthode s’appuie exclusivement sur du code source monolingue, ne requiert aucune expertise dans les langages source ou cible et peut être facilement généralisée à d’autres langages de programmation », indiquent les chercheurs français dans leur article. « Une particularité du projet est que les méthodes utilisées sont les mêmes que celles développées pour la traduction de langues naturelles », nous a expliqué Guillaume Lample. « Nous avons développé ces méthodes il y a 2 ans, pour traduire des langues avec peu de ressources, telles que le Sinhala, Urdu, Pachto ou Népalais. Et ce sont exactement les mêmes techniques que nous avons utilisées pour traduire du code source d'un langage de programmation à un autre ». Les méthodes en question reposent sur trois principes illustrés ci-dessous.
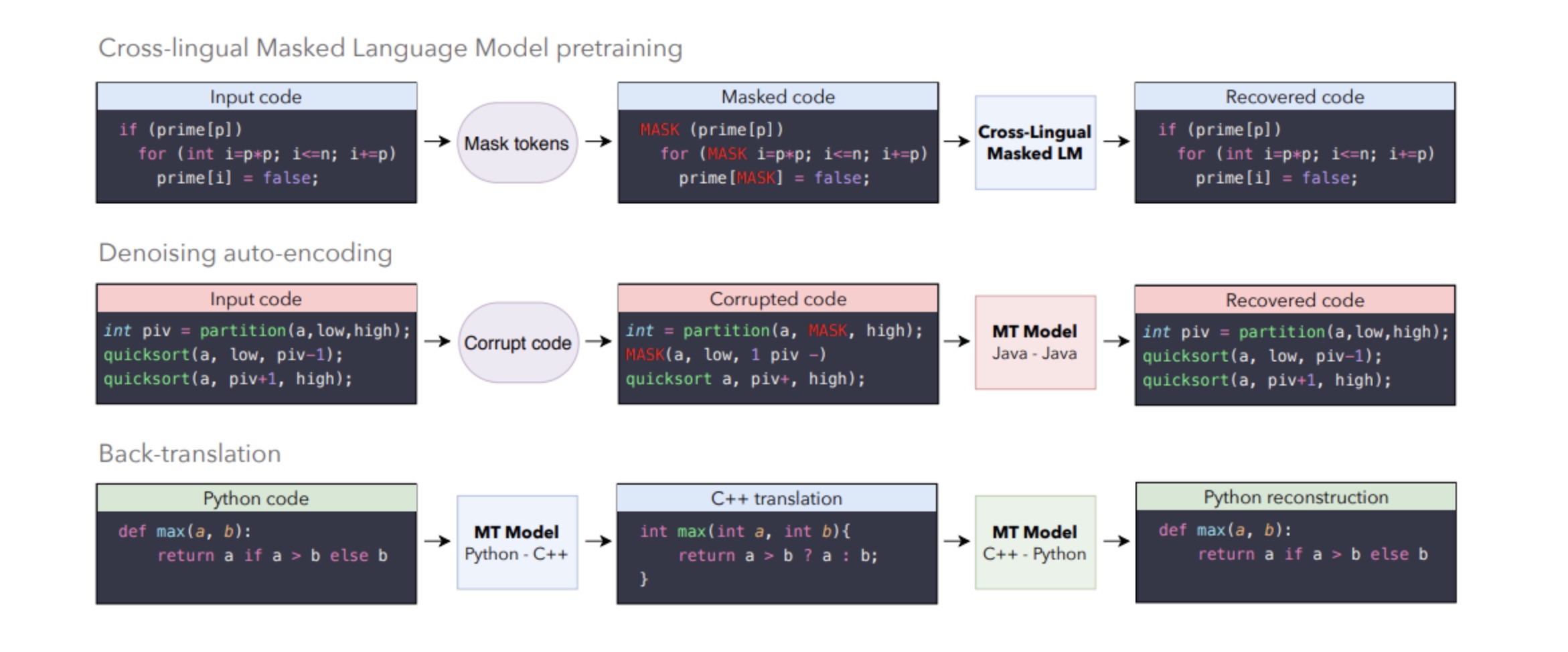
Facebook AI Research s'appuie sur trois méthodes de traduction des langues naturelles : Cross-lingual masked language model pretraining, Denoising auto-encoding et Back-translation. (Crédit : Facebook AI Research / agrandir l'image)
« La méthode la plus intuitive est la "back-translation" », précise Guillaume Lample. « On entraine un modèle à traduire du Python vers le C++, et on l'entraine à reconstruire le code Python initial en se basant sur la traduction générée, approximative, en C++ », décrit-il en renvoyant également sur un billet de blog qui résument ces techniques appliquées aux langues naturelles.
Concernant le transcompilateur neuronal non supervisé sur lequel travaille le laboratoire parisien de Facebook AI Research, l'équipe livre un jeu de test composé de 852 fonctions parallèles, ainsi que des tests unitaires pour vérifier l’exactitude des traductions. Les résultats obtenus montrent que leur modèle surpasse de façon significative les outils de référence commerciaux basés sur des règles.
Commentaire