Il y a quelques mois, Informatica a introduit une approche distribuée de sa technologie d'intégration de données avec Vibe, un moteur de machine virtuelle de données (VDM, virtual data machine). Ce dernier distingue, d'une part, la logique métier de manipulation des données et, d'autre part, la technologie d'exécution sous-jacente. Cela permet aux entreprises de créer des mappings d'intégration et des designs de traitement qui pourront être déployés et exécutés ensuite à différents niveaux, dans le cloud ou sur site, dans les bases de données, dans des applications, sur un cluster Hadoop, en batch ou en temps réel.
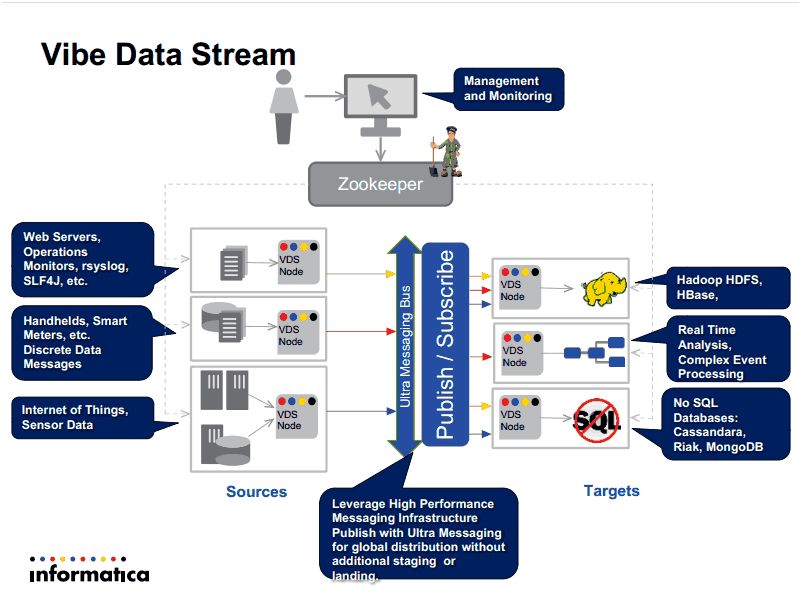
L'un des objectifs d'Informatica est, notamment, que Vibe puisse être exploitée, au niveau le plus bas, pour collecter les données générées par les multiples capteurs qui commencent à peupler l'Internet des objets. Avec différents niveaux d'analyse possibles : à la fois sur les données de détail, sur les données consolidées à différentes étapes, ou analysées globalement via Hadoop. Jusqu'à présent, le fournisseur proposait des VDM pouvant être placées à de multiples niveaux, mais il ne prenait pas encore en charge lui-même le transport de l'information entre les équipements et les systèmes centralisés. Il vient de compléter son schéma avec l'annonce de Vibe Data Stream for Machine Data, « conçu pour gérer de très gros volumes de données en temps réel », nous a décrit Bruno Labidoire, directeur technique Europe du Sud d'Informatica, lors d'un entretien téléphonique. « Nous pouvons maintenant, non seulement mettre les moteurs aux bons endroits, mais aussi les faire communiquer. »
Vibe Data Stream
Basé sur un logiciel d'ultra-messaging
Vibe Data Stream utilise des agents installés du côté client pour collecter les données en temps réel. Ces dernières pourront être remontées vers des environnements de traitement big data comme Hadoop et Cassandra, ou bien vers PowerCenter, la plateforme d'intégration d'Informatica, ou encore vers son application de gestion des événements complexes (CEP). Tout type de terminal est potentiellement susceptible de se connecter à Vibe Data Stream, à l'instar d'une machine virtuelle Java (JVM). Pour mettre au point cette couche de transport, Informatica est parti de la technologie d'ultra-messaging qu'il a développée et mise en oeuvre dans le monde de la finance et du trading. « Nous avons travaillé sur sa robustesse sa résilience, ainsi qu'autour des fonctionnalités de gestion du failover et c'est ce produit amélioré qui a servi de base à Vibe Data Stream », nous a expliqué Bruno Labidoire. « C'est une solution basée sur un logiciel très éprouvé, réarchitecturé pour couvrir un nouveau besoin. Mais dans le principe, nous sommes toujours sur de l'ultra-messaging ». L'expérience, acquise au cours d'années de fonctionnement dans des environnements très stressants, a donc été matérialisée dans d'autres types d'équipements, mais toujours avec le même principe de clients et d'API. Au niveau d'Hadoop, Informatica est compatible avec toutes les bases du marché, ainsi qu'avec une base de données NoSQL comme Cassandra.
Face à Vibe, Cloudera Flume ou Scribe de Facebook
C'est dans le domaine des opérateurs de télécommunications qu'Informatica a trouvé les premiers utilisateurs de Vibe Data Stream, « early adopters » de sa toute récente technologie de transport. Ces utilisateurs génèrent de très gros volumes de données en réalisant des consolidations intermédiaires, sur les tickets d'appels notamment, et ils doivent être capables de resynthétiser l'information. Informatica investit particulièrement dans ce secteur d'activités, pour être en mesure de montrer les bénéfices obtenus.
Sur le terrain exploré par Vibe Data, les principaux concurrents se trouvent plutôt sur le versant Open Source, avec des offres comme Cloudera Flume, Apache Kafka ou encore, du côté de Facebook, avec un serveur comme Scribe conçu pour agréger des données de connexions récupérées en temps réel.
Informatica raccorde l'Internet des objets à Hadoop
0
Réaction
Après avoir annoncé des machines virtuelles de données à embarquer dans les capteurs peuplant l'Internet des objets, Informatica s'est appuyé sur son logiciel d'ultra-messaging pour faire remonter les données en temps réel vers Hadoop.
")
Newsletter LMI
Recevez notre newsletter comme plus de 50000 abonnés
Commentaire