")
Après avoir réussi son introduction en bourse avec un succès inégalé en septembre, l'éditeur de datawarehouse natif cloud Snowflake a annoncé la semaine dernière une série d’évolutions autour de son architecture Data Cloud. Celle-ci s’appuie sur sa plateforme de gestion de données et datawarehouse SaaS pour créer un écosystème où les entreprises peuvent, d’une part, unifier leurs données en s’affranchissant des silos répartis entre différents clouds et applications on-premise, et d’autre part, partager ces données avec leurs partenaires, clients et fournisseurs de façon sécurisée. La plateforme Snowflake permet de le faire quelle que soit le cloud public choisi par les différentes entreprises et la localisation des données. Au sein du Data Cloud, les données sont accessibles à tous les utilisateurs de la plateforme Snowflake, a rappelé Frank Slootman, CEO de l’éditeur, lors d’un point presse en ligne. « Le partage des données va devenir central à la gestion opérationnelle des données, nous pensons vraiment que cela devrait devenir la norme et pas l’exception », a-t-il indiqué.
Cette capacité d’échange s’est formalisée autour d’une Data Marketplace qui permet un accès à des données tiers d’une centaine de fournisseurs. Rappelons que la technologie de partage proposée fournit l’accès aux données sans avoir à copier celles-ci ou à les déplacer. Désormais, la marketplace intègre des fournisseurs de services de données. A travers Data Services, un utilisateur peut créer des accès directs, sécurisés et bi-directionnels sur des données sur lesquelles il souhaite exécuter des services ou qu’il veut enrichir : par exemple évaluer les risques sur des données clients ou exploiter des outils d’analyse prédictive externes tiers.
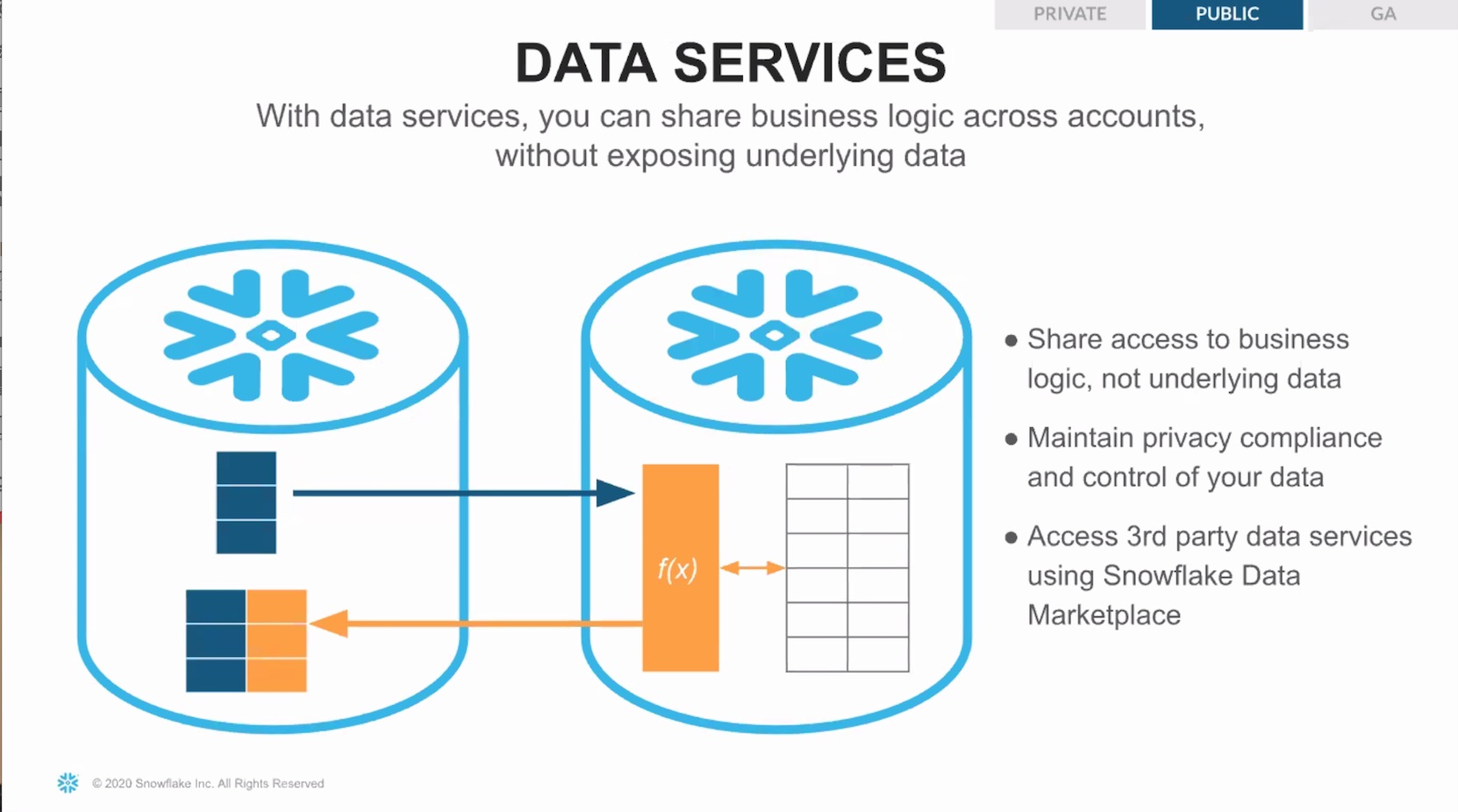
Data Services permet de partager une logique métier, sans partager les données auxquelles celle-ci est appliquée. (Crédit : Snowflake)
Snowpark permettra de coder dans le langage de son choix
Sur le coeur de la plateforme Snowflake elle-même, l’éditeur californien poursuit ses avancées, en particulier sur l’expérience offerte aux utilisateurs, « Nous voulons une expérience unique et cohérente, pas des blocs à assembler », a souligné de son côté Christian Kleinerman, senior vice-président de l’innovation produit, en pointant la couche d’abstraction fournie au-dessus des différents usages. Parmi les nouveautés introduites sur la gestion du pipeline de données, l’expérience de développement Snowpark va permettre aux data engineers, aux data scientists et aux développeurs d’écrire du code dans les langages de leur choix puis d’exécuter des charges de travail de type ETL/ELT, préparation et ingénierie de données sur Snowflake. Il sera ainsi possible d’intégrer davantage de pipelines de traitement au sein de la même plateforme gouvernée en utilisant les compétences existantes et en améliorant la productivité. Les utilisateurs pourront débugger les pipelines avec les outils qu’ils connaissent et amener des bibliothèques tierces. Pour l’instant, le support démarre avec Scala et Java avec l’objectif d’ajouter d’autres langages dans le futur. La possibilité d’utiliser des fonctions externes est pour l’instant en préversion publique dans AWS et Azure (GCP à venir).
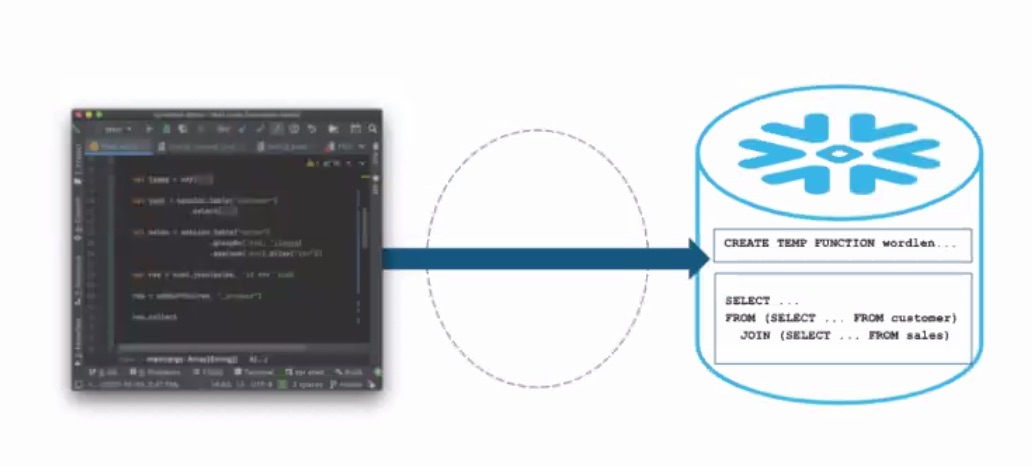
Snowpark pousse toutes ses opérations directement vers Snowflake sans Spark ni aucun autre intermédiaire, explique Snowflake.
« C’est une toute nouvelle façon de programmer les données dans Snowflake, c’est entièrement optimisé, les clients pourront faire tous les workflows qu’il veulent », a indiqué Christian Kleinerman. Snowpark est pour l’instant uniquement disponible dans des environnements de test. Encore en gestation également chez l’éditeur, des fonctions serverless vont permettre d’automatiser le pipeline, Snowflake gérant l’allocation de ressources et leur programmation. Un cas d’usage typique pour ces tâches porte sur les pipelines pour gérer les traitements des données provenant de capteurs IoT.
Une gouvernance renforcée sur l'accès aux données
La gestion des données non structurées augmente très rapidement. Pour les prendre en charge, Snowflake annonce maintenant le support de l’audio, de la vidéo, des fichiers pdf, de l’imagerie et d’autres formats. La plateforme va pouvoir orchestrer les pipelines d’exécution de leur traitement et apporter une gouvernance fine sur ce type de fichiers et les métadonnées associées. Cette fonctionnalité est disponible en préversion.
Concernant la gouvernance, Snowflake va permettre de créer des politiques de restriction d’accès à certaines lignes de données lors des requêtes. Le filtrage des lignes de la base auxquelles l’utilisateur peut accéder se fait au moment de la requête, en se basant sur le rôle de l’utilisateur. Cette fonctionnalité devrait aider les entreprises à se conformer aux différentes réglementations régionales de protection des données. Elle sera fournie en préversion privée d’ici la fin de l’année.
En juin, Snowflake avait annoncé un service d’optimisation des recherches actuellement en préversion publique. Il développe maintenant un service d’accélération des requêtes qui va paralléliser certaines portions des requêtes.
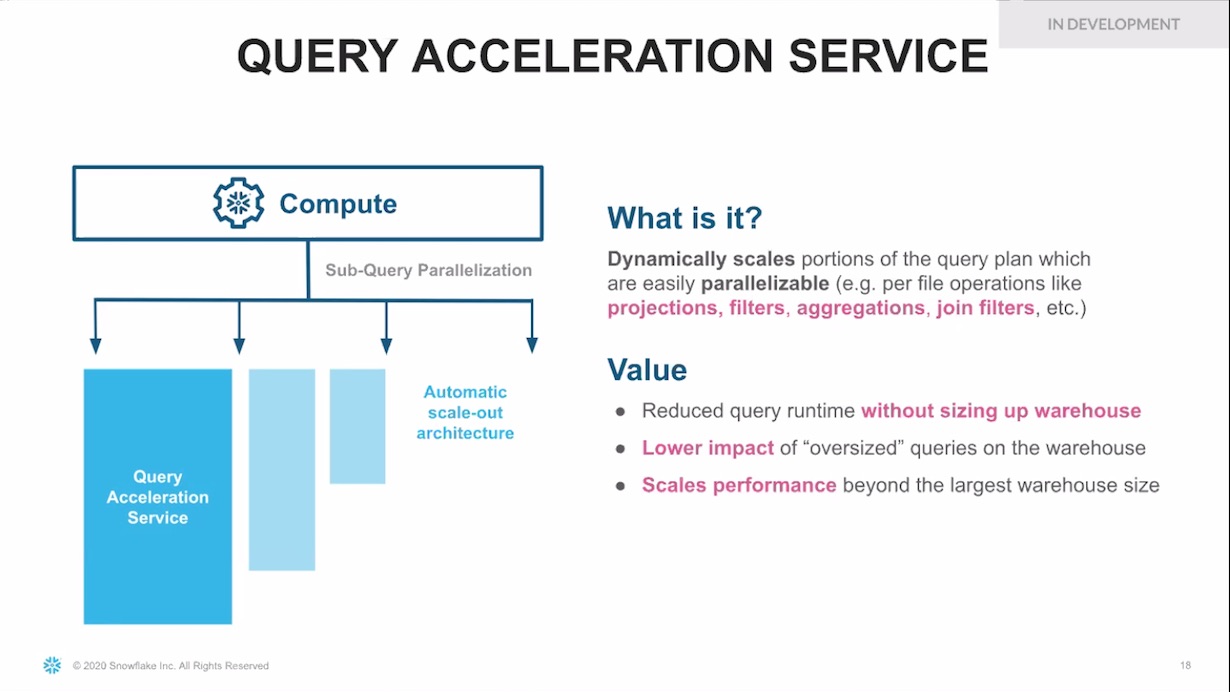
En développement chez Snowflake, un service d'accélération des requêtes qui utilisera automatiquement l'architecture scale-out. (Crédit : Snowflake)
Commentaire