")
Depuis que Le Monde Informatique a commencé à couvrir l'essor de diverses applications de l'IA, comme la génération d'image - notamment avec Stable Horde - les dépôts de code sur GitHub et les liens sur Reddit fourmillent de modèles d’IA. Certains d’entre eux se retrouvent en fait sur des sites commerciaux, qui développent leurs propres algorithmes ou en adaptent d'autres qui ont été publiés en open source. Un excellent exemple de site d'IA audio existant est Uberduck.ai, qui propose littéralement des centaines de modèles préprogrammés. Il suffit d'entrer le texte dans le champ prévu à cet effet pour qu'un Elon Musk, un Bill Gates, un Daffy Duck, ou même un Siri lisent les lignes préprogrammées.
Pour entraîner une IA à reproduire la parole, il faut télécharger des échantillons de voix claires. L'IA apprend comment le locuteur combine les sons dans le but d'apprendre ces relations, de les perfectionner et d'imiter les résultats. Normalement, l'assemblage d'un bon modèle vocal peut demander un certain entraînement, avec de longs échantillons pour indiquer comment une personne particulière parle. Ces derniers jours, cependant, quelque chose de nouveau est apparu : Microsoft Vall-E, enrichi par un document de recherche (avec des exemples concrets) sur une voix synthétisée qui ne nécessite que quelques secondes d'audio source pour générer une voix entièrement programmable. Naturellement, les chercheurs et autres admirateurs de l'IA ont voulu savoir si le modèle Vall-E avait déjà été mis à la disposition du public. La réponse est non. En attendant, il est possible de jouer avec un autre modèle si vous le souhaitez, appelé Tortoise. (L'auteur précise qu'il s'appelle Tortoise parce qu'il est lent, ce qui est vrai, mais il fonctionne).
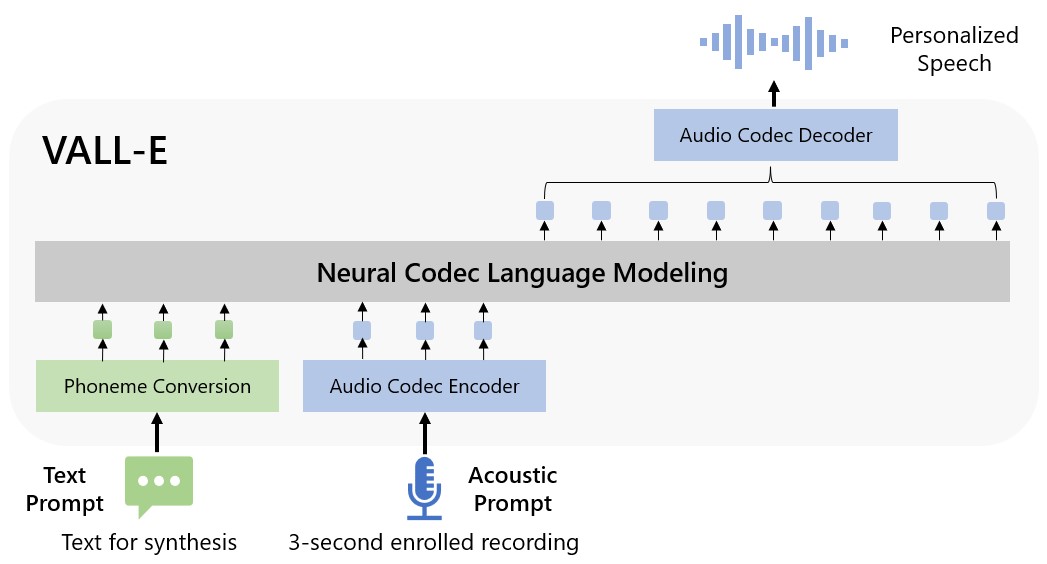
La vue d'ensemble de VALL-E. (Crédit : VALL-E / Microsoft)
Entraîner sa propre voix d'IA avec Tortoise
Ce qui rend Tortoise intéressant, c'est que chacun peut entraîner le modèle sur la voix de son choix en téléchargeant simplement quelques clips audios. La page GitHub de la solution indique qu’il faut disposer de quelques clips d'environ une douzaine de secondes. Il faut ensuite les enregistrer dans un fichier .WAV avec une qualité spécifique. Comment cela fonctionne-t-il ? Grâce à un service cloud méconnu : Google Colab (ou « Colaboratory »). Il permet d'écrire et d'exécuter du code Python dans son navigateur sans aucune configuration requise, avec un accès sans frais aux GPU et un partage facile. Le code que vous (ou quelqu'un d'autre) écrivez peut être stocké dans un carnet de notes, qui peut ensuite être partagé avec les utilisateurs qui ont un compte Google générique. La ressource partagée Tortoise est ici.
L'interface semble intimidante, mais elle n'est pas si mauvaise. Il faut être connecté en tant qu'utilisateur Google, puis cliquer sur « Connecter » dans le coin supérieur droit. Si ce module ne télécharge rien sur votre Google Drive, d'autres modules peuvent le faire. A noter que les fichiers audio qu'il génère, en revanche, sont stockés dans le navigateur mais peuvent être téléchargés sur votre PC. Petite précision qui a son importance : si quelqu’un exécute un code écrit par quelqu'un d'autre, il est possible que l’utilisateur reçoive des messages d'erreur, soit à cause d'une mauvaise saisie, soit parce que Google a un problème en arrière-plan, comme le fait de ne pas avoir de GPU disponible. Tout cela est un peu expérimental.
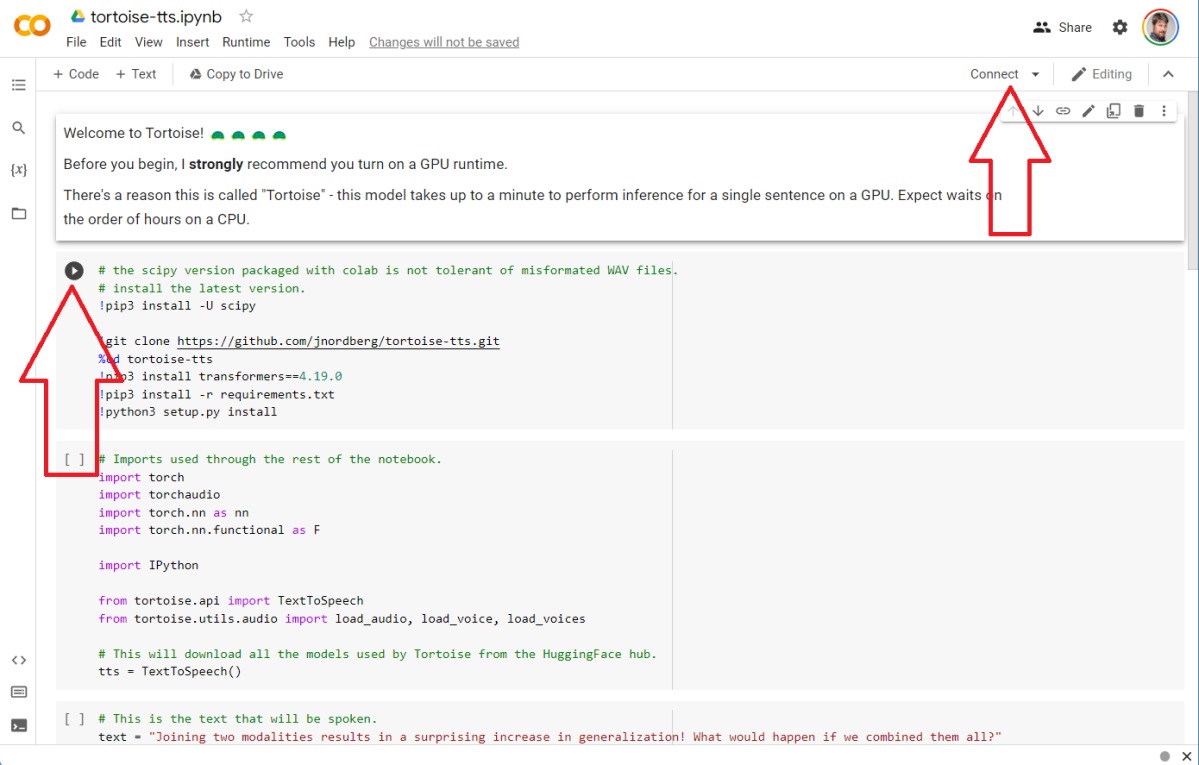
The Tortoise Collab. Cliquez sur le bouton « Connecter » pour commencer, puis cliquez sur la petite icône « play » à côté de chaque bloc de code à tour de rôle. (Crédit : Mark Hachman / IDG)
Chaque bloc de code a une petite icône « play » qui apparaît si l’on passe sa souris dessus. Il faudra cliquer sur « play » sur chaque bloc de code pour l'exécuter, en attendant que chaque bloc s'exécute avant de passer à l’exécution du suivant.
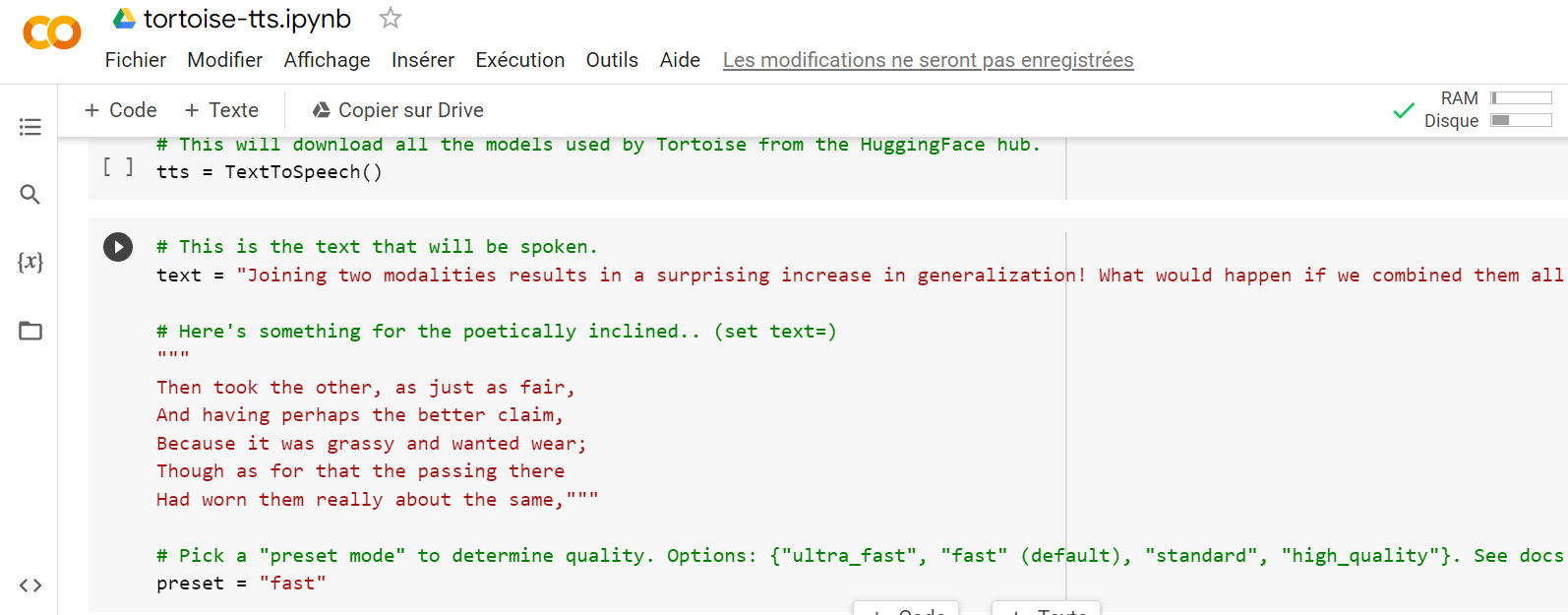
(Crédit : Colaboratory)
Sans entrer dans le détail, notons que le texte rouge est modifiable par l'utilisateur, comme le texte suggéré que l’on veut que le modèle prononce. Environ sept blocs plus bas, l’utilisateur aura la possibilité de former le modèle, le nommer puis télécharger les fichiers audios. Une fois cette opération terminée, il suffit de sélectionner le modèle audio dans le quatrième bloc, exécuter le code, puis configurer le texte dans le troisième bloc. Enfin, il faut exécuter ce bloc de code. Si tout se passe comme prévu, le résultat est une petite sortie audio de son échantillon de voix. Cela fonctionne plutôt bien, voire plus vrai que nature.
Commentaire