Flux RSS
Architecture logicielle
2077 documents trouvés, affichage des résultats 221 à 230.
| < Les 10 documents précédents | Les 10 documents suivants > |
(13/06/2011 10:21:39)
USI 2011 : Connecter les objets et rendre intelligible la vie des utilisateurs (entretien avec Rafi Haladjian)
LeMondeInformatique : Vous avez cofondé la société Violet qui a donné naissance à différents objets communicants, dont le Nabaztag, et vous interviendrez le 29 juin prochain dans le cadre de l'USI 2011 sur l'intérêt de connecter ensemble les objets. Sous quel angle prévoyez-vous d'aborder ce sujet ?
Rafi Haladjian : Le slogan de Violet, en 2003, c'était « Make all things be connected ». Dans notre vision, tous les objets pouvaient être connectés. Depuis, sept ou huit ans ont passé. L'Internet des objets dont on ne parlait pas du tout à l'époque est devenu un sujet sinon brûlant, en tout cas chaud, dont on parle un peu partout. Mais notre réflexion a également évolué et nous pensons que, précisément, connecter les objets n'est pas la bonne façon de poser le problème. Je me suis rendu compte, lorsque l'on parlait de l'Internet des objets, que l'on imaginait souvent quelque chose d'assez futuriste. Il y a toujours ce mythe du réfrigérateur communicant que chacun imagine avoir un jour et c'est finalement assez gênant. Je pense que ce qui est en jeu et ce qui est en train de se produire, ce n'est pas tant la connexion des objets entre eux, mais le fait que l'on est en train de déborder les frontières de l'ordinateur et du téléphone portable pour rendre intelligible l'espace physique dans lequel nous vivons. Jusqu'à présent, l'interaction que l'on avait avec les ordinateurs, avec les données ou avec les systèmes intelligents, se faisait à travers un guichet qui était un écran.
C'est-à-dire à travers un terminal, quel qu'il soit ?
...à travers un dispositif vers lequel on se tournait pour faire ses transactions. Aussi commode et petit, puisse-t-il être, là n'est pas la question. Mais ce qui se passait réellement dans le monde physique, le monde réel, était inconnu. C'était une espèce de zone d'ombre dont on ne tenait pas compte. L'utilisateur venait devant son écran, déclarait un certain nombre de choses : « voilà ce que j'écris, ce que je pense, ce que je fais ». Alors que désormais, de plus en plus, il y a des dispositifs qui permettent d'occuper le reste de l'espace, comme les GPS, ou les accéléromètres que l'on trouve sur les iPhone. Tout un ensemble de dispositifs qui existent déjà. Donc, cette tendance à rendre intelligible le reste du monde physique est quelque chose qui commence à se produire. Et, l'Internet des objets, c'est avant tout cela. Ce n'est pas le fait de connecter les réfrigérateurs, ce qui est anecdotique et accessoire. Il faut voir le vrai sens de ce qui est en train de se passer.
Quel va être le rôle de ces dispositifs ?
L'objectif, c'est de comprendre ce qui se passe dans la vie des gens, de rendre intelligible ce qu'ils sont en train de faire sans qu'ils aient besoin de le dire. Par exemple, dans une conférence, si l'on veut savoir ce que l'auditoire a pensé de l'exposé, on demande aux participants de remplir un formulaire ou d'aller sur une application pour donner leur appréciation. On pourrait procéder autrement. Ce que j'ai vu à l'Université de Bilbao, par exemple, ce sont des prototypes de fauteuils dans lesquels on a placé des capteurs de pression, tout bêtes, qui sondent la façon dont les gens sont assis sur leur fauteuil. Sont-ils avachis, signe que, peut-être, ils s'ennuient ? Semblent-il au contraire attentifs à qu'ils sont en train d'écouter ? Vous pouvez de cette façon avoir une compréhension immédiate de ce que les gens sont en train de penser de la présentation en cours, sans que les personnes aient forcément besoin de l'exprimer. Il s'agit ici de recherche universitaire. Ce n'est qu'un exemple. Le but du jeu, c'est de ne pas s'arrêter à la possibilité de connecter tous les objets, mais de se demander en quels sont les moyens dont on dispose pour comprendre ce qui se passe dans un environnement sans avoir à le demander à l'utilisateur. Cela ouvre des opportunités, surtout pour les entreprises.
Dans quels domaines et pour quelles applications ?
Une entreprise qui, par exemple, fabrique des objets, va se demander quels services elles peut inventer au-dessus. Certains services existent depuis très longtemps déjà et l'on ne s'en rend pas compte. Tous les télécopieurs de bureau sont connectés à une ligne téléphonique et les fabricants qui les louent peuvent les surveiller pour savoir à l'avance si vous allez manquer d'encre, de papier, afin d'en livrer avant que vous ne veniez à en manquer. Il n'est pas nécessaire d'aller jusqu'à un dispositif aussi incongru qu'un Nabaztag pour imaginer les objets communicants qui vont arriver. La capacité à anticiper les besoins de l'utilisateur, à ressentir ce qu'il fait, à mettre en commun ce que font différents utilisateurs à un moment donné et de les comparer à d'autres... Google ne procède pas autrement. C'est en accumulant ces masses d'informations sur le comportement de millions d'internautes qu'il arrive à déterminer, à suggérer des comportements qui ont un sens pour d'autres utilisateurs. Observer ce que tout le monde boit comme café le matin et vous serez capable de prédire à un utilisateur particulier ce qu'il va aimer comme café, non seulement en observant son comportement, mais aussi celui des autres.
A quel horizon voyez-vous ces applications se concrétiser ?
Technologiquement, rien n'empêche de le faire demain. Pour que cela existe sur le marché, il faudrait compter trois ans. C'est globalement le temps de mettre au point le hardware, plus difficile à élaborer que le logiciel, et de le commercialiser. D'un point de vue technologique, on n'attend rien. On a tout ce qu'il faut. Il n'y a rien d'autre à inventer que ce qui est déjà sur le marché. Donc, il manque juste la volonté des industriels d'y aller. Mon rôle, en participant à des conférences comme l'USI, c'est de continuer à sensibiliser et à évangéliser. J'étais là au tout début de l'Internet, en 1994, et jusqu'en 1999, nous avons passé notre temps à convaincre nombre de grandes entreprises qui ne voyaient pas l'intérêt d'aller sur Internet. Au début, il faut faire ce travail-là. C'est un peu ingrat.
Vous avez créé une autre société, « Sen.se » dont la devise est cette fois « Feel, Act, Make Sens ». Quels sont vos objectifs ?
Sen.se, c'est avant tout une infrastructure qui permet de connecter n'importe quoi avec n'importe quoi. Ce peut être une source d'information par exemple, la météo, votre calendrier Google, votre poids transmis par votre balance Withings, toutes sortes de flux de données, personnels ou non, et puis des informations qui sont mesurées par des appareils comme des capteurs de chaleur dans votre domicile, votre accéléromètre, un mouchard installé dans votre voiture, des machines. De la même façon qu'il existe le Machine-to-Machine, nous définissons cela comme le Whatever-to-Whatever (n'importe quoi à n'importe quoi).
Vous utilisez une infrastructure de type cloud pour regrouper les informations ?
Absolument. Cette infrastructure, nous la déclinons de trois manières. Nous la mettons d'abord à la disposition d'entreprises qui voudraient mettre au point des objets communicants parce que, non seulement, il faut concevoir et fabriquer l'objet lui-même, mais encore faut-il qu'il se connecte à une infrastructure qui va gérer les services associés. C'est ce que nous proposons. C'est la partie « Business Sen.se » de notre activité. La deuxième partie s'appelle « Open Sen.se ». C'est celle que l'on voit quand on va sur notre site (http://open.sen.se/). Elle s'adresse aux designers, aux développeurs et à tous ceux qui veulent jouer avec cela. C'est gratuit. Vous avez développé vous-même votre petit appareil, vous avez détourné un Nabaztag ou un pèse-personne, par exemple, et vous pouvez commencer à imaginer vous-mêmes des usages en combinant des applications.
Vous fournissez des interfaces de programmation (API) ?
Il y a des API si vous avez envie d'écrire du code. Si vous n'en avez pas envie, nous proposons des applications toutes faites. Si vous voulez que votre plante verte vous envoie un « tweet » lorsqu'elle a besoin d'eau, vous pouvez le faire sans avoir à écrire de code du tout. Si vous voulez recueillir des températures à différents emplacements, obtenir une moyenne et recevoir cette information une fois par semaine, c'est possible. Nous utilisons de petites applications en ligne que vous allez configurer. L'idée, c'est d'imaginer des usages et de pas limiter ces possibilités à des développeurs.
Vous avez évoqué une troisième déclinaison de votre infrastructure.
C'est celle que nous démarrerons plutôt vers la fin de cette année, avec laquelle nous allons proposer aussi de nouveaux types d'appareils. Qui ne seront d'ailleurs pas exclusifs. Il sera possible d'utiliser nos appareils et ceux fournis par d'autres fabricants. Nous ne croyons pas à un monde fermé, mais à un monde dans lequel on trouve des données de toutes sortes de provenance. Il faut organiser tout cela autour de l'individu et non pas avoir un utilisateur qui butine d'un appareil à un autre comme s'il s'agissait d'un archipel d'objets.
(...)
Tribune de Georges Abou Harb : Le meilleur des mondes serait-il dans le cloud communautaire ?
Les partisans du cloud considèrent ce dernier comme un bouleversement fondamental dans la manière dont les entreprises utilisent et consomment l'IT. Du point de vue du directeur financier, il permet de diminuer sensiblement les dépenses informatiques, et transforme ce poids financier en charge opérationnelle planifiée sur la base des abonnements. Pour les directeurs opérationnels et les managers, le cloud permet à leurs équipes de bénéficier d'un support IT réactif en quelques jours, voire en quelques heures, là où il fallait précédemment compter en mois ou en années. Pour les directeurs informatiques, il est synonyme de facilité d'exécution et de simplification des contraintes d'achat, de ressources et de traitement administratif.
Tous ces avantages sont bien réels, même s'il encore un peu tôt pour dire si le cloud computing est une révolution, ou une évolution. Mais il existe d'autres types de bénéfices futurs qui méritent d'être plus amplement explorés. Parmi ceux-là se trouvent l'une des perspectives les plus intéressantes : le cloud au service des communautés d'intérêt et de leurs bénéfices mutuels.
Ceux d'entre nous qui travaillent dans l'IT sont habitués à parler de clouds privés, de clouds publics ou même de clouds hybrides. Mais une autre idée - parfois désignée sous le terme de cloud communautaire - mérite une plus grande attention en raison de sa capacité potentielle à combiner les intérêts du cloud public avec les avantages plus spécifiques et sur mesure du cloud privé.
Qu'est-ce que le cloud communautaire, exactement ? Il est décrit par l'Institut National des Standards et des Technologies (National Institute of Standards and Technology) comme tel lorsque :
« L'infrastructure de cloud est partagée par plusieurs organisations et sert plusieurs communautés ayant des intérêts communs (par exemple en termes de mission, d'exigences de sécurité, de politique ou de conformité). Il peut être géré par les organisations ou par une tierce partie, et doit exister on premise ou off premise. »
Pour lire la suite de la tribune de Georges Abou Harb, directeur général en charge des activités Future IT & Cloud chez Logica France, cliquez sur ce lien. (...)(08/06/2011 10:34:16)
Les technologies de l'IBM Watson appliquées au big data
Mi-février, le superordinateur Watson conçu par IBM a battu deux champions au jeu télévisé Jeopardy, un quizz de culture générale où il s'agit de trouver une question à partir d'une réponse. Pour y parvenir, Watson a, entre autres, absorbé une quantité phénoménale d'informations disponibles sur le web et d'une qualité toute relative. Des données qui ont nourri ses multiples algorithmes sollicités à chaque réponse pour aboutir rapidement à une question associée à un indice de confiance. Une partie du problème auquel se sont attelés les 25 informaticiens d'IBM qui ont développé Watson est similaire à celui que rencontrent les Google et Facebook lorsqu'il s'agit de scanner d'énormes quantités de données non-structurées pour répondre rapidement à une requête. Un problème, ou plutôt une solution, dont ils ont d'ailleurs fait un modèle d'affaires avec le succès que l'on connaît.
Bien loin des laboratoires de recherche, des plateaux télé et des géants d'Internet, les entreprises, grandes et petites, font face à des défis analogues. D'un côté, elles sont de plus en plus conscientes que l'analyse des données et les découvertes (insights) qui en résultent sont essentielles au pilotage informé de leurs opérations et à leur compétitivité, d'où l'essor des projets de business intelligence. De l'autre, elles croulent sous une masse indigeste d'informations de toutes sortes et de toute provenance le plus souvent négligées et considérées comme un problème. Disposer d'un Watson est sans doute un rêve que caressent beaucoup de leurs décideurs.
Selon une étude IDC commandée par EMC, l'univers digital - la somme de toutes les données numériques - a crû de 1,2 million de pétaoctets en 2010 et pourrait atteindre 35 millions de pétaoctets à l'horizon 2020. L'écrasante majorité de cette masse est constituée de textes et de fichiers audio et vidéo. Donc de données sans structure, contrairement à celles reposant dans une base de données classique. Cette déferlante concerne aussi les entreprises, qui sont sans cesse plus nombreuses à collecter des informations sur les réseaux sociaux, les outils collaboratifs et les centres d'appel. A cela s'ajoute de nouvelles données mises à disposition par des organismes publics ou générées par les senseurs dont sont équipés les smartphones.
Par leur énorme volume de l'ordre de plusieurs téraoctets, par leur qualité incertaine et par leur caractère fugace, ces big data ne ressemblent en rien aux données relationnelles qui alimentent les solutions de business intelligence usuelles (voir le graphique). Leur exploitation diffère tout aussi fondamentalement. Alors que la BI fournit des réponses exactes à des questions précises connues d'avance, l'exploration expérimentale des big data livre des réponses probables à des questions ad-hoc et suggère de nouveaux questionnements. Pour employer la métaphore de Tom DeGarmo, responsable des technologies chez PricewaterhouseCoopers: «Au lieu de trouver une aiguille dans une botte de foin, ces techniques permettent de chercher d'autres bottes de foin».
[[page]]
Il y a quelques années encore, ce type d'analyse à grande échelle était surtout pratiqué par des instituts de recherche scientifique (physique, astronomie, bioinformatique, finance), souvent à l'aide de superordinateurs extrêmement onéreux. Faute visibilité quant à leur potentiel, faute de compétences statistiques et faute de moyens technologiques et financiers, les entreprises ne s'y sont guère intéressées. Sous l'effet de la prolifération de données non-structurées (typiquement 80% des données d'une entreprise), le domaine connaît un intérêt nouveau dans des sociétés qui se demandent comment exploiter ces données brutes qui sommeillent ou qui n'ont pas (encore) fait l'objet de formalisation par les architectes. A l'affût de nouveaux besoins, plusieurs grands fournisseurs IT ont d'ailleurs acquis récemment des sociétés spécialisées dans le domaine du big data: EMC avec Greenplum, IBM avec Netezza, HP avec Vertica ou encore Teradata avec Aster Data Systems début mars. Un mouvement également suivi par plusieurs éditeurs de business intelligence qui élargissent leur offre à l'analyse de larges volumes de données. Le dénominateur commun de la plupart de ces solutions est leur utilisation du projet open source Hadoop dérivé des développements de Google.
Au début des années 2000, face à la croissance folle des contenus internet, Google a en effet dû développer sa propre solution pour être en mesure de continuer à les indexer en des temps raisonnables. Les ingénieurs de la société ont développé un système de stockage robuste et extensible (GFS) et un système de traitement des données répartissant les tâches sur un grand nombre de serveurs fonctionnant en parallèle et à même de synthétiser leurs résultats (MapReduce). Ainsi, au lieu de s'appuyer sur des algorithmes complexes et des ordinateurs surpuissants, la solution de Google utilise des batteries de serveurs standards, qui peuvent être ajoutés ou supprimés, auxquels sont confiées des tâches relativement simples. Le projet Hadoop est en fait une implémentation open source de MapReduce gérée par la fondation Apache, à laquelle sont venus se greffer d'autres composantes destinées aux big data, comme un système de fichiers distribué (HDFS) ou une base de données (HBase). Yahoo! est l'un des pionniers en la matière et coopère avec Facebook, dont le cluster Hadoop serait actuellement le plus gros du monde (voir le lien à droite).
La robustesse, le coût et la flexibilité de cette technologie séduisent également des sociétés hors du monde internet. Le New York Times a ainsi utilisé Hadoop pour générer les PDF de 11 millions d'articles publiés entre 1851 et 1922, et l'emploie désormais pour l'analyse de texte et le web mining. La chaîne de librairies Barnes & Noble l'utilise pour comprendre les comportements d'achats de ses clients sur ses divers canaux de distribution. Disney teste la technologie avec des objectifs similaires en s'appuyant sur des ressources dans le cloud et sur des serveurs inutilisés en raison de ses efforts de virtualisation. McAfee y fait par exemple appel pour détecter des corrélations parmi les spams. Pour simplifier les déploiements, ces sociétés et les autres utilisateurs précoces du big datausent fréquemment d'outils commerciaux basés sur Hadoop qui offrent une large palette de fonctions additionnelles.
[[page]]
Pour Abdel Labbi, responsable de la recherche en analyse de données au centre de recherche d'IBM à Zurich, ces développements technologiques conduisent à une convergence entre les données transactionnelles en mouvement, typiques des acteurs du web, et les données au repos des sociétés traditionnelles». Exemple de cette convergence, l'analyse en temps réel des données récoltées sur les points de vente pour dresser des profils de clients. «Ce n'est plus la requête qui va chercher des données, mais les données qui découvrent des phénomènes», estime le chercheur. Le lien avec Watson - l'ordinateur de Jeopardy - apparaît d'emblée et ouvre de nouvelles perspectives.
Watson : vers une analyse intelligente des données
Pourtant, de prime abord, le superordinateur d'IBM ne représente pas une innovation majeure mais plutôt une manière innovante de combiner des technologies existantes. Au niveau hardware, Watson est «massivement redondant» pour reprendre les termes du responsable de sa conception David Ferucci, avec une kyrielle de transistors économiques. Idem pour les algorithmes qui sont nombreux mais relativement simples. Quatre points cependant en font une machine assez prodigieuse pour disputer la victoire à des humains. Tout d'abord, sa capacité à exécuter simultanément de multiples algorithmes, donc à suivre plusieurs pistes en parallèle, à une très grande vitesse. Ensuite, sa faculté d'apprentissage qui lui permet avec le temps d'évaluer quelles ressources et quels algorithmes donnent les meilleurs résultats. Troisièmement, son habilité à décider entre plusieurs réponses et à leur attribuer un indice de confiance. Enfin, sa compréhension du langage naturel et donc son habileté à résoudre des ambiguïtés.
La combinaison de ces diverses facultés pourrait avoir dans le futur un impact considérable sur l'analyse de données en entreprise. La compréhension du langage permettrait par exemple d'étendre l'analyse aux requêtes orales des clients pour y répondre de manière automatisée. Associée aux recherches en analyse sémantique et des sentiments, ce type d'intelligence pourrait répondre précisément à une question ad-hoc, au lieu de simplement pointer sur une source dans laquelle se trouve la réponse comme le font des moteurs de recherche. Elles pourraient également résoudre le problème des données non-structurées en faisant émerger une structure sur la base de corrélations. Comme le dit Abdel Labbi, on pourrait déboucher sur des systèmes où «la donnée trouve la donnée».
HP s'engage sur la voie du cloud hybride
La stratégie cloud d'HP passe par plusieurs étages. C'est un peu le message que le constructeur a voulu faire passer lors de son évènement Discover (infrastructures et solutions logicielles), qui s'est tenu à Las Vegas. HP a commencé par dévoiler les évolutions de sa stratégie Converged Infrastructure, en présentant notamment plusieurs gammes de son offre Converged Systems, package clé en main intégrant matériel, logiciels, services de conseil et de support.
Au sein de cette offre, on peut citer trois axes, HP VirtualSystem qui est un produit prêt à l'emploi dans le domaine de la virtualisation allant de l'environnement serveur au VDI. Il se décline en fonction du nombre de VM activées. La deuxième orientation est baptisée CloudSystem, déjà annoncé en janvier dernier et permet de construire et d'administrer les services de clouds publics, privés et hybrides. Enfin, AppSystem accélère le déploiement et optimise la gestion des applications. HP indique des offres spécifiques, comme par exemple Vertica Analytics System qui s'occupe du traitement des big data.
Le cloud hybride comme accompagnateur vers le cloud public
Si l'idée du cloud privée fait son chemin, les entreprises dans une logique de consommation de ressources informatiques à l'usage et d'un catalogue de service étendu, peuvent avoir envie de se tourner ponctuellement vers le cloud public. Mais il peut y avoir des freins à cela comme la sécurité, les problèmes d'interopérabilité, etc. Pour HP, la réponse se situe dans le cloud hybride, ou ce qu'il nomme Hybrid Delivery avec quelques éléments supplémentaires. Ainsi, pour résoudre la question de l'interopérabilité ou de la sécurité, le constructeur a mis au point un programme nommé Cloud Agile, qui sera composé de partenaires fournisseurs de cloud public (opérateur de télécommunication, intégrateur, ISP, etc). Ce programme vient d'être lancé et donc aucun nom n'a été donné.
Deuxième étape, en cas de pic de trafic, deux options sont envisageables, le DSI peut faire appel à des ressources issues du cloud public et les partenaires de Cloud Agile sont là pour y répondre. Seconde possibilité comme Philippe Rullaud, directeur division serveurs ISS chez HP l'indique « l'entreprise pourra utiliser les ressources de son cloud privé pour ces pics d'activité avec l'offre CloudSystem ». Le constructeur assure que sa couche middleware capable de gérer ces « burst » sera multi-vendeur « nous sommes sur un marché de serveur hétérogène » précise Philippe Rullaud. Il s'agit aussi d'un moyen d'attendre la mise en orbite du cloud public d'HP, qui n'a pas été annoncé à Las Vegas.
Des annonces qui arrivent en réponse aux solutions présentées par IBM en avril dernier.
Apple WWDC 2011 : Mac OS X Lion, iOS 5 et iCloud à l'honneur
La WWDC 2011 d'Apple a été l'occasion pour Steve Jobs, qui avait tenu à faire la présentation inaugurale en personne, et son équipe dirigeante de faire plusieurs annonces, Mac OS X Lion, iOS 5 et iCloud.
Une grande partie de la présentation consacrée à Lion a permis de revenir plus en détail sur un certain nombre de fonctionnalités, dont certaines avaient été révélées l'automne dernier, quand Apple avait tracé les grandes lignes de la mise à jour majeure de Mac OS X. Premier constat, de nombreuses fonctionnalités apparues pour la première fois dans le système d'exploitation mobile iOS d'Apple vont se retrouver dans Lion. Parmi elles, le support des actions multitouch, l'affichage plein écran pour les applications, et une nouvelle fonction Launchpad qui reproduit un écran d'accueil sur le modèle de l'iPad.
Apple a également livré de nouvelles informations sur Lion, en particulier, sa date de sortie et son prix. Jusqu'ici, l'entreprise californienne Apple avait annoncé sans trop de précision une date de sortie pendant l'été. Mais, lundi, la firme a fait savoir que le prochain OS X serait disponible en juillet au prix de 30 dollars. Par ailleurs, et c'est une première, Lion ne sera vendu que par l'intermédiaire de sa boutique en ligne Mac App Store, lancée en janvier, et qui aura une place majeure dans Mac OS X Lion. Côté développeurs, Apple dit que Lion apporte plus de 3000 API supplémentaires qui pourront être intégrées dans des applications comme la gestion des versions, les notifications Push, le suivi gestuel, le mode plein écran, et davantage encore.
iOS 5 se met à jour par les airs
Comme pendant la présentation de Lion, qui a offert un aperçu de 10 fonctionnalités dans la mise à jour à venir, les responsables d'Apple ont montré une dizaine de modifications et d'améliorations dans la version d'iOS 5 à venir. Apple a indiqué que la mise à jour de son système d'exploitation mobile, prévu pour l'automne, comporterait 200 fonctionnalités complémentaires. Le changement le plus attendu est peut-être celui du système de notification avec ses pop-up uniques pour chaque alerte. iOS 5 apporte un centre de notifications combinant toutes les alertes, auxquelles on peut donc accéder d'un seul coup. Autre changement important attendu avec iOS 5, la possibilité de réaliser les mises à jour d'un appareil sous iOS ou d'effectuer des téléchargements, sans avoir à le relier à un ordinateur. Ainsi, les prochains iPhone afficheront un écran permettant d'activer l'appareil sans besoin de le connecter à un Mac ou à un PC, et les mises à jour logicielles et la synchronisation pourra s'effectuer en mode sans fil (en mode OTA over the air).
[[page]]
Parmi les autres améliorations d'iOS 5, on trouve une application de messagerie pour tous les périphériques sous iOS, des fonctionnalités dans la version mobile de Safari, l'identification unique pour Twitter, un lecteur de news qui ressemble beaucoup à iBooks, plus des améliorations des fonctions de la caméra, comme le lancement de l'application depuis le bouton de verrouillage de l'écran et l'usage des touches de volume pour prendre des photos.
iCloud ou la synchronisation ultime
Le PDG d'Apple, Steve Jobs, a terminé son tour d'horizon des nouveautés par iCloud, la plate-forme de synchronisation de données sans fil d'Apple, accessibles aux appareils sous iOS, et aux ordinateurs Macs et PC. Ce service gratuit prendra la place de MobileMe, pour la synchronisation des contacts, des agendas, et des mails entre différents appareils. Il offre également une fonctionnalité de sauvegarde automatique pour stocker des données importantes sur le Cloud.
iCloud intègre trois nouvelles applications : Documents in the Cloud, qui sait importer des documents iWork pour synchronisation ; Photo Stream qui permet aux utilisateurs de synchroniser des photos prises sur un appareil avec d'autres appareils ; iTunes in the Cloud qui permet aux utilisateurs d'accéder à des titres déjà achetés sur l'iTunes Store d'Apple et de les télécharger sur un maximum de 10 appareils. Pour la musique qui n'a pas été acheté sur iTunes, Apple propose iTunes Match, un service facturé 25 dollars à l'année, qui scanne la bibliothèque iTunes et la compare avec les 18 millions de titres vendus par Apple. iCloud, annoncé pour l'automne, sera livré en même temps que iOS 5. Les utilisateurs auront droit à 5 Go d'espace de stockage gratuit pour le mail, les documents et la sauvegarde. La musique, les applications, les livres numériques achetés, et les photos de Photo Stream ne comptent pas dans ce volume.
Illustration: Steve Jobs présentant les trois offres
Crédit Photo: D.R
(...)(07/06/2011 11:46:40)HP livre un tableau de bord au-dessus de son offre logicielle
Sous la forme d'un tableau de bord destiné aux directions informatiques, le logiciel IT Executive Scorecard, annoncé la semaine dernière par HP, vient chapeauter le portefeuille applicatif de gestion des performances IT constitué par le groupe californien. Un portefeuille que HP a largement étoffé au fil des années, notamment avec les rachats de Peregrine, Mercury, ArcSight, ou encore, Fortify (cf encadré ci-dessous).
A travers le tableau de bord, qui propose plus de 200 indicateurs de performances (KPI), les DSI vont pouvoir faire remonter des informations issues des différentes solutions de HP installées dans l'entreprise : le développement applicatif (ALM), la gestion des infrastructures (Operations Management), les fonctions de sécurité, la planification financière. Ils pourront dès lors bénéficier d'une vision plus claire pour répondre aux diverses questions qu'ils se posent quotidiennement : « Est-ce que je dépense correctement mon budget ? Mes clients sont-ils satisfaits par rapport aux benchmarks de mon secteur d'activité ? Quels sont les projets en retard ? », donne en exemple Claire Delalande, responsable Marketing et Partenaires HP Software France.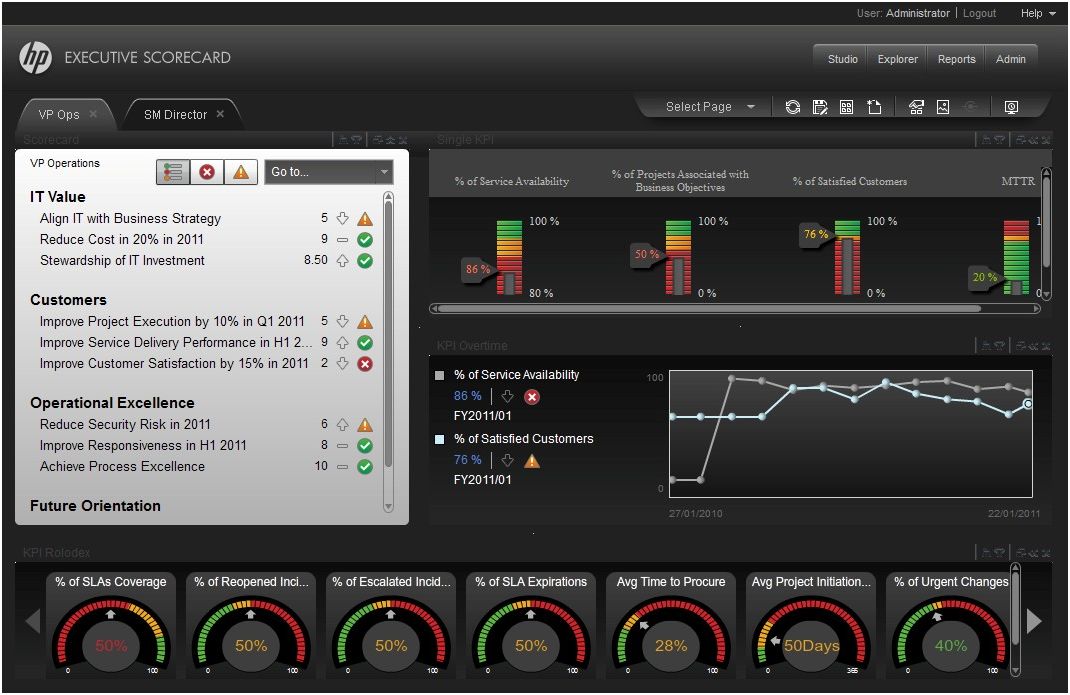
Ci-dessus, quelques indicateurs pouvant être affichés dans l'IT Executive Scorecard de HP (cliquer ici pour agrandir l'image)
Un jeu de données unifié
A partir d'une technologie fournie en OEM par SAP Business Objects, l'IT Executive Scorecard s'appuie sur l'IT Data Model pour intégrer les données provenant de l'ensemble de la suite applicative de HP, désormais regroupée sous le nom de « IT Performance Suite ». L'objectif du logiciel, c'est d'unifier ces informations issues de différentes sources dans un seul jeu de données.
Il est également possible de récupérer des mesures provenant de logiciels édités par d'autres fournisseurs. Le logiciel IT Executive Scorecard propose des rapports préétablis qui peuvent être personnalisés. Il devrait être disponible en juillet prochain. (...)
Google, Microsoft et Yahoo réunis autour du référencement web
Une fois n'est pas coutume. Dans le domaine de la recherche sur le web, Google a joint ses efforts à ceux de ses concurrents associés, Microsoft et Yahoo, afin d'améliorer l'exploration des sites et l'indexation des données structurées. Généralement issues de bases de données, ces dernières perdent leur format d'origine lorsqu'elles sont converties en HTML.
Sur le site « Schema.org », les trois sociétés proposent ainsi différents jeux de balises HTML qu'elles aimeraient voir utilisées par les responsables de sites web afin de mettre en évidence les données structurées de leurs pages. En encourageant le recours à des tags communs, l'objectif est d'aider les moteurs de recherche à mieux comprendre les sites web par une meilleure identification, exploration et indexation des données structurées, explique Google dans un billet de blog.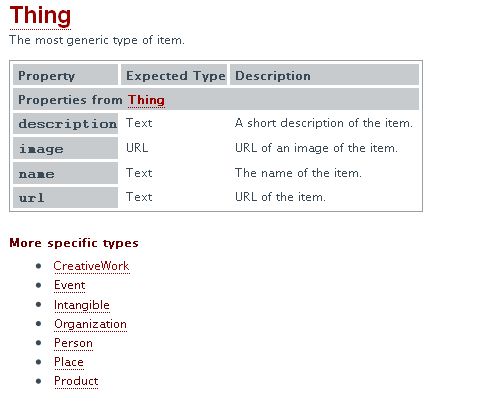
Schema.org contient plus d'une centaine de tags HTML différents répartis entre plusieurs catégories : les productions créatives (articles de presse, livres, logiciels, blogs, films, tableaux...), les événements (sportifs, culturels...), les éléments intangibles (énumérations, quantités, classements...), les organisations (entreprises, clubs, administrations, établissements publics, boutiques...), les personnes, les lieux, les produits. A chaque type d'objets sont associés de propriétés. L'ensemble est présenté dans une arborescence.
Schema.org succède à SearchMonkey
Yahoo a été le premier à lancer une initiative de ce type avec sa plateforme de développement SearchMonkey, qui fut en son temps assez largement popularisée. Elle avait vocation à inciter les webmasters à renforcer le signalement des données structurées sur les sites, rappelle Hadley Reynolds, analyste chez IDC. Lorsque Yahoo décida d'arrêter SearchMonkey l'an dernier, ce fut une sérieuse perte pour le secteur des technologies de recherche, a-t-il indiqué par mail à nos confrères d'IDG News Service. L'analyste trouve donc intéressant de voir les trois principaux fournisseurs du domaine de la recherche se regrouper sur la question des données structurées.
« Au fur et à mesure que les responsables de sites ajouteront des tags qui correspondent au nouveau catalogue de schémas publié, il sera plus facile pour les trois grands moteurs de recherche de restituer le type d'interactions enrichies qui s'annoncent comme devant être la prochaine étape de concurrence entre eux dans la course à l'audience », souligne Hadley Reynolds.
Dans l'esprit, le nouveau programme reprend certains aspects de SearchMonkey, auquel s'ajoute l'apport significatif de Google et Microsoft, estime l'analyste d'IDC. « L'une des priorités des développeurs web va donc être de faire monter leurs sites dans les classements des moteurs de recherche ». (...)
VMware CloudFoundry s'ouvre au langage Scala
VMware vient d'annoncer que sa plateforme Cloud Foundry est désormais à même d'héberger des applications programmées dans le langage Scala. Développé à l'EPFL, Scala combine des caractéristiques de la programmation objet et de la programmation fonctionnelle. Il est entre autres utilisé par Twitter, Linkedin et Foursquare pour sa robustesse et son extensibilité. Les développeurs utilisant ce langage pourront donc déployer leurs applications sur Cloud Foundry, comme c'est déjà le cas pour Java et Ruby. Selon l'environnement de développement employé et l'appel à des services tiers (base de données par exemple), des modifications mineures peuvent être nécessaires, avertit toutefois VMware.
www.ictjournal.ch
Crédit photo : D.R. (...)
IBM dote les villes d'un outil de gouvernance IT
Karen Parrish, vice-présidente d'IBM sur l'activité solutions industrielles a annoncé « cette plateforme qui doit permettre aux municipalités de faire des économies et d'avoir une réponse rapide en cas de catastrophe ». Ce logiciel, baptisé Intelligent Operations Center, synthétise un ensemble de données issues d'une grande variété de systèmes IT, tels que les réseaux d'eau, la traçabilité des équipements publics, les transports ou la gestion du trafic routier. Il offrira visuellement un résumé des données recueillies, en utilisant un certain nombre de règles développées par IBM.
IOC proposera une série de tableaux de bord, ainsi que des connecteurs pour les différents systèmes de gestion back-end. Il comprend aussi un certain nombre de programmes IBM, comme le serveur d'applications WebSphere et la base de données DB2. « Nous avons construit un centre opérationnel qui est capable de récupérer un ensemble de flux en temps réel, travailler et analyser les données et fournir des renseignements essentiels aux gestionnaires afin qu'ils puissent prendre des décisions plus rapidement et de manière plus efficace », précise Karen Parrish.
Cliquer sur l'image pour l'agrandir
Du sur-mesure avec des « faisceaux de points communs »
IBM a conçu IOC de façon modulaire. Différents modules seront lancés au cours des 12 à 18 prochains mois. Ces unités complémentaires couvrent des données spécifiques, telles que la gestion de l'eau ou la sécurité publique. « Les responsables locaux pourront donc intégrer ces modules en fonction de leurs besoins les plus critiques », souligne Karen Parrish et d'ajouter « nous allons construire ces modules à partir des expériences de plusieurs projets individuels et en extraire les redondances ». Aucun d'eux ne sera néanmoins disponible lors du lancement de la solution.
Pour construire ces unités additionnelles, IBM s'appuie sur 2 000 projets qu'elle a réalisés pour des villes comme New York, Memphis, Washington et Dubuque (on peut citer également la ville de Nice qui a emporté en mars dernier le Challenge Smarter Cities pour bénéficier de l'expertise d'IBM en matière de planification stratégique, de gestion des données et de compétences technologiques). Avec ce travail préalable, Big Blue a remarqué des « faisceaux de points communs», comme la gestion centralisée du personnel ou la décongestion du trafic routier.
IBM prévoit le lancement d'IOC à partir du 17 juin prochain. Karen Parrish n'a pas voulu révéler certains détails comme le prix ou la durée d'intégration d'un tel logiciel. Elle a simplement indiqué que le logiciel se connectera facilement à des systèmes IT normalisés et des adaptations particulières seront nécessaires si les systèmes sont plus anciens. La dirigeante a également indiqué que la version initiale du logiciel sera intégrable directement chez le client, mais une offre en mode hébergée est envisagée dans les futures versions.
Illustration: Intelligent Operations Center
Crédit Photo: IBM
(...)
Oracle livre la bêta de JavaFX 2.0
L'équipe Java d'Oracle vient de livrer la version beta de JavaFX 2.0, une mise à jour majeure de l'environnement de développement d'applications Internet riches (RIA, Rich Internet Applications) en Java, créé à l'origine par Sun Microsystems. Dans sa feuille de route, Oracle évoque l'intégration d'API Java pour JavaFX, si bien que les bibliothèques de la nouvelle version seront directement accessibles à tous les développeurs Java sans qu'ils aient à apprendre le langage de script de JavaFX. L'utilisation de JavaFX Script, jusque là nécessaire pour accéder aux capacités de JavaFX, n'est de fait plus utile.
A la page des téléchargements de la beta JavaFX 2.0, on trouve un SDK JavaFX, un runtime et un plug-in JavaFX 2.0 pour l'environnement de développement NetBeans 7.0 (http://javafx.com/downloads/all.jsp). « JavaFX offre une interface utilisateur puissante basée sur Java qui permet de gérer de grosses applications nécessitant des traitements intensifs et faisant appel à beaucoup de données. Les applications JavaFX sont entièrement développées en Java, et s'appuient sur des pratiques de programmation et des modèles de conception normalisés et bien établis », a déclaré Tori Wieldt, responsable de la communauté de développement Java chez Oracle, dans un billet de blog.
« L'interface utilisateur de JavaFX a été améliorée, notamment en ce qui concerne les contrôles, les graphiques et les API pour le multimédia. En particulier, son moteur de rendu permet de hautes performances graphiques grâce à l'usage d'une accélération matérielle, un moteur Web et un moteur de média qui simplifient le développement d'applications immersives. »
Accélération graphique
Parmi les autres éléments cités dans la feuille de route, on remarque la possibilité d'intégrer du contenu HTML au sein d'une application JavaFX, la lecture de médias, ainsi qu'une meilleure capacité de déploiement. On note aussi des améliorations du côté du multithreading. En outre, le runtime de JavaFX devrait être plus rapide au démarrage, en particulier pour les applications simples et classiques. Un pipeline pour l'accélération graphique matérielle, du nom de « Prism », cible DirectX sur Windows et OpenGL sur d'autres plateformes.
JavaFX 2.0 supporte également la vidéo plein écran, et une nouvelle implémentation des transitions animées réduit la charge du processeur et permet davantage de transitions simultanées, comme le précise la feuille de route. D'autres fonctionnalités, également citées mais reportées à plus tard, comprennent une grille de présentation des feuilles de style CSS (Cascading Style Sheets), des animations en CSS, et un contrôle prêt à l'emploi pour lire des contenus médias.
De quoi aider JavaFX à regagner en popularité auprès des développeurs dans un marché du développement de clients riches plutôt encombré qui comporte non seulement Flash d'Adobe, mais également Silverlight, la plate-forme de Microsoft basée sur le standard HTML5.
Illustration : site de téléchargement d'Oracle / blog Java Team at Oracle (montage LMI)
| < Les 10 documents précédents | Les 10 documents suivants > |