Flux RSS
HPC
138 documents trouvés, affichage des résultats 11 à 20.
| < Les 10 documents précédents | Les 10 documents suivants > |
(25/01/2012 17:03:36)
Intel va acheter les actifs InfiniBand de QLogic
Intel a annoncé lundi dernier qu'il avait accepté d'acheter la division InfiniBand de Qlogic que le fabricant de puces exploitera dans ses solutions serveur et stockage pour permettre à ses nombreux clients de réaliser des supercalculateurs exaflopique. Dans un communiqué, Qlogic a déclaré qu'Intel allait acquérir ses actifs InfiniBand pour un montant de 125 millions de dollars. L'achat est attendu ce trimestre une fois que les conditions seront réunies.
InfiniBand est une technologie réseau qui fournit une interface haut débit entre des serveurs ou des baies de stockage. Cette acquisition permettra à Intel d'étendre son portefeuille en solution réseau pour fournir une bande passante plus importante et accompagner l'augmentation des performances des processeurs et des serveurs.
Des liens indispensables pour les clusters de puissance
Le mois prochain, le fabricant de puces va dévoiler, avec ses partenaires habituels, ses nouvelles puces serveur Xeon E5 qui accompagneront la montée en puissance des machines dédiées au calcul intensif. Intel espère bien que les prochains systèmes pourront atteindre, avant 2018, des performances exaflopiques, soit une puissance de calcul 100 fois plus rapide que les superordinateurs les plus véloces aujourd'hui.
«La technologie et l'expertise de Qlogic fourniront des actifs importants pour construire les composants évolutifs nécessaires à l'exécution de cette vision », a déclaré dans un communiqué Kirk Skaugen, directeur général de l'activité Data Center and Connected System chez Intel.
Recentrage de l'activité pour QLogic
Qlogic propose aujourd'hui des adaptateurs, des commutateurs, des logiciels (Fabric Suite) et d'autres produits basés sur InfiniBand. La vente des actifs InfiniBand aidera la compagnie à se recentrer sur la convergence des réseaux (sur base Ethernet) et le SAN (sur base Fiber Chanel). Bataille où elle affronte des acteurs comme Emulex, Brocade ou Juniper. De son côté, Intel étoffe ses solutions réseau pour les datacenters. En juillet dernier, le fondeur avait déjà signé un protocole d'accord pour acquérir la société Fulcrum qui conçoit des puces réseau 10 et 40 Gigabits Ethernet et des produits de commutation Ethernet.
Il est logique pour Intel d'acquérir les actifs InfiniBand de Qlogic, a déclaré Zeus Kerravala, analyste principal chez Research ZK. Avec les liens InfiniBand pour le réseau et les serveurs, la firme de Santa Clara sera en mesure d'étendre son offre pour ses clients développant des solutions de calcul de haute performance en cluster. «Je ne pense pas que [InfiniBand] va devenir un marché énorme, mais il est en expansion et il est là pour un moment », a déclaré M. Kerravala. Cette acquisition permet également à Intel d'améliorer la convergence avec les offres de Qlogic pourraient être utilisées dans ses puces ou au niveau des racks. Intel a annoncé qu'un «nombre significatif» d'employés InfiniBand de Qlogic allait accepter son offre et rejoindre Intel.
En 2012, la demande en serveurs économes en énergie va profiter aux puces ARM
Les processeurs de type basse consommation proposés par des compagnies comme ARM pourraient être massivement utilisés dans les centres de calcul en 2013, et leur association avec des puces graphiques pourrait apporter des améliorations de performances et entrainer d'importantes économies d'énergie, selon les analystes. Les premières expériences autour des processeurs ARM dans des serveurs sont déjà en cours -chez HP notamment- , et les puces graphiques sont déjà utilisées dans certains des supercalculateurs les plus rapides du monde.
L'efficacité énergétique a été un des éléments déterminants pour l'achat de serveurs chez les clients désirant maintenir leurs coûts d'exploitation tout en déployant des applications , selon les analystes. Cette année, on a assisté à un pic dans l'accumulation de clouds et de serveurs haute performance autour du modèle « hyperscale », dans lequel la densité des machines est très élevée pour réduire la consommation d'énergie tout en augmentant la performance globale.
Passer de x86 à ARM pour certains usages
Pour réaliser des économies électriques supplémentaires, les entreprises pourraient envisager d'utiliser à l'avenir des serveurs avec processeurs ARM basse consommation, qui sont aujourd'hui à l'oeuvre dans la plupart des tablettes et smartphones. «Les clients font des tests avec beaucoup de technologies différentes. Ils essaient de gagner en efficacité», a déclaré Jed Scaramella, directeur de recherche chez IDC. Les entreprises mesurent désormais leur consommation en kilowatt et en mètre carré/euros, et la mesure des performances par watt des serveurs est devenue beaucoup plus précise. La croissance des plates-formes de type cloud computing contribue à l'augmentation des ventes de serveurs, avec de nombreuses entreprises qui construisent des clouds publics et privés. Beaucoup de serveurs x86 bi-socket ont été achetés pour créer des infrastructures de ce type autour du modèle hyperscale, qui permet à de nouvelles machines d'être raccordées très facilement pour augmenter les performances globales. Les serveurs utilisant cette architecture hyperscale sont généralement utilisés pour des applications analytiques et décisionnelles. «Elles ne sont pas jetables, mais elles sont clairement conçues pour travailler avec des coûts réduits. C'est vraiment une question d'efficience énergétique ... et de souplesse à l'usage », a déclaré M.Scaramella.
Des serveurs denses avec des processeurs ARM pourraient être une alternative à la technologie x86 dans les prochaines années quand les DSI exigeront encore plus de densité et d'économies d'énergie. Les analystes soulignent que l'agrégation de puces ARM basse consommation pourrait fournir une capacité de traitement plus efficace sur des plates-formes de type cloud computing de nuages que les traditionnelles puces serveurs x86 (Intel Xeon ou AMD Opteron), qui sont plus gourmandes en énergie. Les processeurs ARM sont cependant moins intéressants que les puces x86 pour traiter des tâches gourmandes en ressources comme les ERP (Enterprise Resource Planning).
Des serveurs ARM en cours de tests chez les clients de HP
En 2011, certaines entreprises ont introduit des serveurs expérimentaux reposant sur des processeurs ARM. Hewlett-Packard a ainsi annoncé en novembre dernier une machine utilisant des puces quad-core Calxeda, sur un design ARM, qui consomment 1,5 watt de puissance par puce. De son coté, Nvidia a indiqué le mois dernier qu'un supercalculateur a été construit à Barcelone autour de sa puce Tegra 3, qui repose sur une architecture ARM quad-core. Et pour accélérer les calculs scientifiques et mathématiques, un bloc de trois puces Tegra - soit douze coeurs - est jumelé avec des processeurs graphiques. « Ce qui s'est passé en 2011, c'est que l'on a commencé à voir des feuilles de route et des produits. Les solutions sont devenues « réelles », mais cela ne signifie pas qu'elles vont gagner des parts de marché l'année prochaine [en 2012, NDLR], a déclaré M. Scaramella.
[[page]]
Une rupture dans l'architecture serveur traditionnelle x86 au profit de celle d'ARM sera étroitement surveillée, mais l'impact ne se fera vraiment sentir qu'en 2013 au plus tôt, a déclaré Dan Olds, analyste principal chez Gabriel Consulting Group. Presque tous les fabricants majeurs de serveurs vont expérimenter des machines avec des processeurs ARM, a poursuivi M. Olds. « Si c'est suffisamment réel pour que HP lui donne le feu vert, cela signifie que le marché existe », a déclaré l'analyste. « Cela va dépendre de la feuille de route 64 bits d'ARM. »
Il manque encore les instructions 64 bits
Les processeurs ARM actuels ne supportent que l'adressage 32 bits et ne possèdent que des fonctionnalités très limitées pour la correction d'erreurs. Avec les instructions 64 bits, les ordinateurs peuvent utiliser une plus grande quantité de stockage et de mémoire, ce qui est bénéfique pour les applications intensives. Fin octobre 2011, ARM avait présenté sa première architecture microprocesseur 64 bits, l'ARMv8, destinée aux marchés des systèmes embarqués et des serveurs.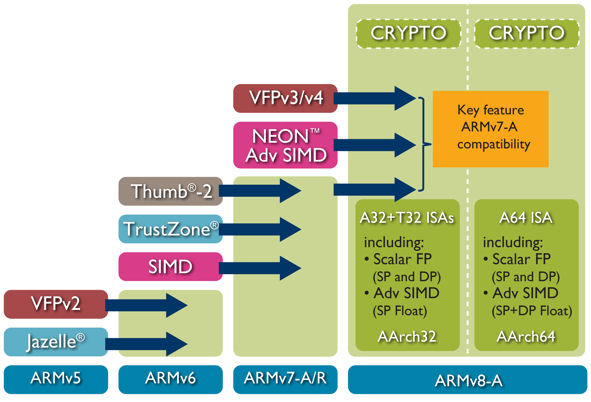
L'idée du couplage CPU ARM et GPU est également fascinante, selon M. Olds. Les circuits graphiques sont utilisés sur certains des supercalculateurs les plus rapides au monde, et sont capables d'offrir des performances bien supérieures à celles des processeurs traditionnels pour exécuter certaines applications. « Une telle combinaison serait un moyen d'offrir une densité beaucoup plus élevée, avec un coût au watt moindre », a poursuivi l'analyste.
La transition x86 vers ARM risque de prendre du longtemps
Les processeurs graphiques s'infiltrent progressivement dans les supercalculateurs et sont de plus en plus utilisés pour le calcul haute performance dans l'énergie, les produits pharmaceutiques, les services financiers, les médias et d'autres industries, selon M. Olds.
Mais les analystes conviennent que le passage de l'architecture x86 à celle d'ARM reste encore un défi en raison des problèmes matériels et logiciels. Les clients sont déjà en train de réfléchir aux différentes options d'achat avec les matériels disponibles, pour optimiser la charge de travail de leurs systèmes en regroupant serveurs, stockage, réseaux et logiciels. Si la plate-forme ARM offre certains avantages, elle reste un élément perturbateur et son adoption prendra du temps. « C'est un long voyage, il ne se déroulera pas une seule nuit », a ajouté M. Scaramella d'IDC.
Gerry McCartney, DSI de l'Université de Purdue dans l'Indiana, se fait l'écho de cette assertion, en indiquant que son université a beaucoup investi dans son infrastructure informatique actuelle. Elle s'appuie largement sur des serveurs x86, et une grande partie du code utilisé par les chercheurs est écrit pour le jeu d'instructions x86. «Les chercheurs ne veulent pas changer de logiciels », a déclaré M. McCartney. Il faudra plusieurs années d'efforts pour passer de l'architecture x86 à une autre et beaucoup ne voudraient pas aller vers cette nouvelle architecture. Notre université ne va probablement pas s'éloigner des puces x86, car les serveurs d'Intel sont de plus en plus économes en énergie, a déclaré M. McCartney.
À titre d'exemple, le supercalculateur Purdue Carter, qui se classe 54e au monde Top 500, offre plus de performances par watt que les quatre autres supercalculateurs, également sur base Intel, achetés au cours des quatre dernières années. «Je ne pouvais pas me débarrasser des quatre machines précédentes, et j'utilise aujourd'hui un quart de l'énergie qu'elles consommaient auparavant », a déclaré M. McCartney. Le ratio de performance/consommation des puces Intel s'améliore avec chaque nouveau composant, selon lui. "Il y a eu quelques améliorations modestes dans l'encombrement, et nous sommes satisfaits en termes de consommation électrique », a déclaré McCartney.
Le Cedars Sinai Hospital à Los Angeles intègre l'IBM Watson à son équipe de médecins
IBM et WellPoint, le plus grand programme de santé du Blue Cross Blue Shield, ont mis au point des applications qui vont transformer le supercalculateur Watson en conseiller spécialisé, au service des oncologues du département Samuel Oschin Comprehensive Cancer Institute de l'hôpital Cedars-Sinai de Los Angeles, comme l'a indiqué Steve Gold, directeur du marketing mondial d'IBM Watson Solutions.
La base de données que possède déjà le Cedars-Sinai sur le cancer, mais aussi les dossiers cliniques de patients en cours de traitement, vont être versés dans la mémoire d'une déclinaison du supercalculateur Watson d'IBM, qui sera installée au siège de WellPoint. L'ordinateur va servir de référentiel en matière de données médicales sur de multiples types de cancer. WellPoint travaillera ensuite avec les médecins du Cedars-Sinai Hospital pour concevoir et développer des applications, et valider leurs capacités. Le Dr M. William Audeh, directeur médical de l'institut de recherche pour le cancer, travaillera en étroite collaboration avec des experts cliniciens de WellPoint pour fournir des conseils sur la meilleure façon dont Watson peut être utilisé dans la pratique médicale et apporter une meilleure compréhension des connaissances acquises sur le cancer, y compris sur des thérapies alternatives moins bien connues des médecins. IBM avait fait savoir plus tôt cette année que la santé serait la première application commerciale de l'ordinateur qui avait réussi à battre les deux champions « humains » du jeu Jeopardy au mois de février.
Cet automne, WellPoint s'est associé avec IBM pour développer des applications pour le supercalculateur Watson, destinées à améliorer les soins aux patients en mettant à profit des pratiques médicales qui ont pu faire leur preuve. L'idée est aussi de normaliser les traitements aux patients après avoir identifié les meilleures pratiques. Un exemple de cette médecine fondée sur la pratique, c'est quand un professionnel de santé met systématiquement un patient qui a subi une crise cardiaque sous aspirine au moment de sa sortie de l'hôpital. Cedars-Sinai est la première émanation de ce partenariat. « Là où Watson se montre vraiment utile dans ce contexte, c'est sur la richesse des informations qu'il est capable de traiter, informations en constante évolution, qui lui parviennent sous différentes formes, structurées et non structurées, depuis des systèmes eux-mêmes disparates », a expliqué Steve Gold. « Le secteur de la santé est particulièrement bien adapté pour tirer profit de cette compétence. »
[[page]]
Le supercalculateur Watson, vainqueur des champions du Jeopardy, était constitué de 90 serveurs Power Express 750 IBM intégrant des processeurs 8 coeurs - quatre dans chaque machine - avec un total de 32 processeurs par machine. Les serveurs ont été virtualisés en utilisant une machine virtuelle libre sur noyau Linux (KVM), de manière à créer un cluster de serveurs ayant une capacité de calcul de 80 téraflops (un téraflop = 10 puissance 12 opérations en virgule flottante par seconde). La déclinaison de Watson qui sera utilisée par le Cedars-Sinai Hospital est beaucoup plus petite, a confirmé le directeur du marketing mondial d'IBM Watson Solutions (le supercalculateur sera hébergé par WellPoint et accessible à distance via un réseau étendu). « Le Watson qui a concouru pour le Jeopardy avait une configuration bien précise. Il disposait notamment d'une application en mémoire lui permettant de répondre à une question en trois secondes », a déclaré Steve Gold. « Il abritait 2 880 coeurs et 15 téraoctets de mémoire. La plupart des situations ne nécessitent pas un tel temps de réponse. Si la réponse parvient au médecin en 6 à 10 secondes, c'est suffisant... D'autant que la qualité de la réponse et ses implications sont plus importantes que le délai nécessaire pour l'obtenir. »
Le modèle Watson qui sera utilisé par le Cedars-Sinaï Hospital sera donc beaucoup plus petit, mais il aura la même capacité d'analyse de données provenant de systèmes disparates, données à la fois structurées et non structurées. IBM a notamment travaillé avec l'éditeur Nuances Communications, dont le logiciel effectue de la reconnaissance vocale et de l'imagerie. Avec ce logiciel, le supercalculateur peut aider les professionnels de santé à déterminer le meilleur traitement possible en fonction d'une maladie spécifique, après avoir examiné des gigaoctets ou des téraoctets d'informations médicales sur les patients. Ainsi, la technologie d'analyse de Watson, associée au système de reconnaissance vocale et de compréhension du langage médical de Nuance, pourrait aider un médecin à prendre en compte l'ensemble des textes relatifs à la maladie de tel patient, les matériaux de référence, les cas cliniques connus, les dernières connaissances médicales publiées sur le sujet dans des revues et dans la littérature médicale. L'analyse pourrait aider les médecins à effectuer rapidement un diagnostic et à déterminer le traitement le plus approprié.
« Watson sera probablement un bon assistant pour aider les médecins à prescrire les traitements qui auront les meilleurs résultats », a fait valoir Steve Gold d'IBM. « Par exemple, pour un patient atteint d'un cancer, son traitement doit être en général modifié dans un cas sur deux entre la première et la seconde prescription, selon la manière dont il réagit au premier traitement », explique Steve Gold. Watson pourrait permettre de mieux prescrire le traitement initial en comparant les données du patient à toutes les informations se rapportant à la maladie. « L'objectif est d'aider les médecins à choisir le traitement le mieux adapté, en s'appuyant sur une pratique médicale actualisée, dont il peut avoir connaissance en quelques secondes », a t-il déclaré.
La Russie construit un supercalculateur de 10 pétaflops
T-Platforms, une entreprise technologique moscovite, qui a déjà construit certains des plus grands systèmes informatiques en usage dans le pays, a annoncé qu'elle développait un supercalculateur 10 pétaflops pour le compte de l'Université d'État MV Lomonosov de Moscou. Ce projet vient rejoindre la liste des supercalculateurs les plus importants en cours de développement dans les pays les plus impliqués dans ces technologies. Il marque aussi l'intention de la Russie de devenir un acteur majeur dans la course à l'Exascale. Le pays doit rattraper son retard pour se placer dans un peloton de plus en plus rapide dans lequel on trouve actuellement la Chine, le Japon, les États-Unis et l'Europe. L'enjeu : être, dans la décennie, le premier pays à réaliser un supercalculateur Exascale, c'est à dire un système ayant une puissance de calcul de mille pétaflops (un petaflop correspond à 10 puissance 15 opérations en virgule flottante par seconde).
La mise au point d'un système Exascale nécessite de nouvelles approches en matière de microprocesseurs, d'interconnexions, de mémoire et de stockage. Si des avancées se produisent en dehors des États-Unis, on pourrait voir apparaitre des entreprises technologiques capables de rivaliser avec les entreprises américaines, aujourd'hui dominantes dans ce secteur. La Russie « s'est engagée à disposer de capacités de calcul Exascale d'ici 2018-2020, et le pays est prêt à y consacrer les investissements nécessaires pour y parvenir », a déclaré Mike Bernhardt, auteur de l'Exascale Report, qui a répondu à un questionnaire de Computerworld. « Nous aurons plus de détails sur les dispositions que prendra la Russie pour mener son projet Exascale dans le courant de l'année prochaine », a t-il ajouté.
Un système de 1,3 pétaflop pour l'Université Lomonossov
L'entreprise T-Platforms, qui se positionne comme le leader du HPC en Russie, s'est également constituée un portefeuille de clients à l'étranger, en Europe notamment. Elle a déjà construit un système de 1,3 pétaflop pour l'Université Lomonossov. Le futur système que l'entreprise doit livrer à l'université moscovite sera refroidi à l'eau et devrait être opérationnel d'ici la fin de 2013. « Il intègrera des puces Intel et Nvidia, et peut-être même des puces MIC d'Intel, si elles sont disponibles en 2012 au moment de la phase de conception », a indiqué T-Platforms.
La position de la Russie en matière de supercomputing est assez proche de celle de l'Europe. Russes et Européens aimeraient être moins dépendants des technologies américaines pour construire des systèmes haute performance. « A ce stade, tout le monde s'accorde pour dire qu'il n'y pas une entreprise dans le monde qui pourrait prétendre maîtriser cette technologie et affirmer qu'elle sait comment ou avec quels composants construire une machine Exascale », a déclaré Mike Bernhardt. « Ces systèmes seront hybrides, hétérogènes et uniques. Il reste encore trop d'inconnues, de même qu'il y a beaucoup de recherches en cours explorant différentes pistes, pour prédire quelle solution sera la bonne. La Russie pourrait très bien mettre au point sa propre technologie qui dépendra peu, voire pas du tout, des technologies extérieures », a déclaré l'auteur du rapport.
[[page]]
A l'heure actuelle, le monde dépend de l'américain IBM, dont la technologie équipe près de 45% des plus grands systèmes mondiaux figurant sur la liste du Top 500 des supercalculateurs. Hewlett-Packard compte pour 28% et Cray pour 5,4%. L'Europe explore déjà des technologies alternatives. Elle étudie notamment la possibilité d'utiliser des processeurs ARM construits par l'entreprise anglo-saxonne ARM Holdings. « Le calcul Exascale est un défi scientifique, mais c'est aussi une opportunité pour l'Europe de devenir leader dans le calcul haute performance », a déclaré Leonardo Flores Añover, membre de la Commission européenne en charge de l'initiative européenne Exascale, par courriel à Computerworld.
« Cet objectif ne peut être atteint que s'il y a une vraie politique européenne impliquant les États membres de l'UE. La volonté de l'UE est de soutenir l'excellence de l'offre européenne et de promouvoir l'utilisation du HPC dans tous les domaines qui sont stratégiques pour l'Europe (dans l'industrie, le secteur scientifique et la société en général) », a déclaré Leonardo Flores Añover. « En particulier du côté de l'offre, l'objectif est de favoriser le développement d'une capacité industrielle européenne », a t-il ajouté. A l'image de la Chine, qui a développé ses propres processeurs et ses propres systèmes d'interconnexions, qu'elle utilise désormais dans certains de ses systèmes HPC.
Les États-Unis déploient de multiples efforts pour développer une architecture et des technologies pour les plateformes Exascale. Mais le financement d'un projet étalé sur plusieurs années, qui coûtera vraisemblablement plusieurs milliards de dollars, est pour l'instant en attente de la décision du Congrès - annoncée pour le 10 février prochain. Celui-ci doit statuer sur le rapport soumis par le Département américain à l'Énergie (DOE) dans lequel il expose l'importance d'une initiative Exascale aux États-Unis, les avancées internationales dans ce domaine, et le coût pour y parvenir.
En formant ses étudiants à Cuda, la Chine se renforce dans le HPC
Le ministère chinois de l'Éducation a ainsi annoncé qu'il allait offrir la plate-forme de développement Nvidia Cuda (Compute Unified Device Architecture) à 200 universités, charge à elles ensuite de former jusqu'à 20 000 étudiants par an.
Architecture de calcul parallèle, Cuda permet aux développeurs d'adapter leur programme pour les environnements parallèles reposant sur les GPU Nvidia. Un outil toutefois particulièrement difficile à maitriser. Si Cuda a été développée par Nvidia, la compagnie a indiqué dans un communiqué diffusé après la conférence de presse chinoise qu'elle allait ouvrir la plate-forme en libérant le code source du compilateur.
Devenir un poids lourd dans le domaine du calcul sur GPU
Sumit Gupta, directeur marketing senior chez Nvidia, a ainsi déclaré que la décision de la Chine de développer la formation à Cuda est une reconnaissance « de la poursuite des investissements de la Chine dans la programmation parallèle et le calcul haute performance », et que l'utilisation des GPU était un bon moyen pour enseigner la programmation parallèle. C'est dû en partie à la grande disponibilité des GPU sur toutes les machines, des ordinateurs portables aux serveurs, a-t-il ajouté.
La formation à Cuda est désormais disponible dans trois ou quatre universités en Chine, mais le langage est enseigné dans près de 500 universités dans le monde, a déclaré M.Gupta. L'ouverture du code source permettra de soutenir plus de langages de programmation, et d'autres architectures processeurs, même alternatives, telles que celle proposée par AMD. Cuda supporte aujourd'hui le C, le C + + et le Fortran.
Un plan quinquenal pour le calcul parallèle
Nathan Brookwood, analyste principal chez Insight 64, a déclaré qu'une formation à la programmation parallèle est nécessaire. « La plupart des développeurs n'ont pas été formés à la façon d'écrire spécifique des approches parallèles, et, dans une certaine mesure, les outils pour écrire ces approches parallèles sont relativement obscurs ».
M.Brookwood ajoute que c'est à mettre au crédit de Nvidia qui a livré des outils tels que Cuda. « Ils permettent aux utilisateurs d'exploiter leurs algorithmes de façon plus parallèle et donc d'afficher une meilleure adéquation avec les GPU. Il y a énormément de gens très intelligents en Chine, et maintenant ils vont être formés à la meilleure façon de profiter de ces outils, » a déclaré l'analyste. Cette formation aidera également la Chine à développer son industrie d'externalisation, a poursuivi M.Brookwood.
En annonçant le plan de formation à Cuda en Chine, Li Maoguo, directeur de la division du bureau de l'enseignement supérieur au Ministère chinois de l'Éducation, a déclaré dans un communiqué qu'« à l'ère de l'économie de la connaissance, l'éducation technologique est un élément essentiel pour la compétitivité des étudiants dans un environnement mondial. »
Selon Nvidia, les GPU pour consoles atteindraient « la dizaine de téraflops d'ici 2019 ».
Le concepteur de puces graphiques Nvidia pronostique que les consoles de jeu vont offrir des performances de l'ordre de la dizaine de téraflops d'ici la fin de la décennie. Ces consoles seront capables d'afficher en temps réel des vidéos avec la qualité que l'on retrouve aujourd'hui dans les fameuses scènes cinématiques d'introduction ou de transition dans les jeux actuels, selon le PDG de la compagnie Jen-Hsun Huang.
Les consoles de jeux de demain finiront par offrir le même niveau de performance que certains superordinateurs actuels, a-t-il poursuivi. Une PlayStation 3 a actuellement une capacité de traitement de quelques centaines de gigaflops seulement, selon M.Huang. Mais en 2019, les consoles de jeu se rapprocheront des performances du supercalculateur Red Storm, qui a été initialement conçu pour atteindre les 41,5 téraflops. Mais contrairement aux supercomputers qui exigent des mégawatts d'électricité pour fonctionner, les consoles de jeu à venir fonctionneront avec la même quantité d'énergie qu'aujourd'hui, a-t-il précisé.« Nous serons en mesure d'offrir ce niveau de capacité en 2019 dans une console de jeu consommant 100 watts », a ajouté le dirigeant.
Combiner GPU et CPU pour réduire la consommation électrique
Huang a fait ces déclarations ce mercredi à Beijing et ajouté que Nvidia s'efforce également d'améliorer les performances des GPU (unités de traitement graphique) équipant les supercalculateurs. Les puces graphiques de la société sont déjà installées dans certains des superordinateurs les plus rapides du monde pour aider à rendre les systèmes plus économes en énergie. En Chine, le Tianhe-1A, qui a brièvement occupé la première marche du podium Top 500 en 2010, emploie plus de 7 000 GPU Nvidia.
Combinées aux processeurs, les puces graphiques de Nvidia vont aider les superordinateurs à atteindre des performances plus élevées sans augmenter d'autant la consommation électrique, a indiqué M.Huang. Ce qui finira par permettre à un superordinateur d'atteindre une vitesse de traitement d'un exaflop (1 milliard de milliards d'opérations en virgule flottante par seconde) d'ici l'an 2019 en consommant seulement 20 mégawatts, a-t-il ajouté.
Actuellement en construction, le supercalculateur américain Titan va utiliser 18 000 GPU Nvidia. Le Titan aura une vitesse de pointe de 20 pétaflops, soit beaucoup plus que le superordinateur le plus rapide aujourd'hui, le K japonais, qui pointe à 8 pétaflops et consomme près de 10 mégawatts d'électricité.
Intel corrige une faille permettant de contourner une sécurité intégrée dans ses processeurs
Intel a mis en oeuvre un processus complexe pour développer un patch destiné à corriger une faille découverte récemment dans les SINIT ACM, autrement appelés System INITialisation Authenticated Code Modules. Ces modules sont susceptibles de subir une attaque par dépassement de mémoire tampon et de laisser passer un malware capable de contourner la plate-forme TXT (Trusted Execution Technology) pour prendre le contrôle total de la machine infectée. La technologie TXT, propre aux processeurs et chipsets d'Intel (Core 2, Core i5 et i7 et enfin Xeon, voir liste compléte), combine des éléments matériels et logiciels. Elle a pour but de bloquer l'exécution de codes par un ensemble de signatures logicielles certifiées.
La mise en évidence de cette vulnérabilité par élévation de privilège revient à l'entreprise de sécurité Lab Invisible Things, dont les chercheurs avaient repéré une faille similaire dans les SINIT ACM il y a deux ans. En fait, selon Joanna Rutkowska, fondatrice et CEO de l'entreprise, le problème découvert en 2009 était un sous-ensemble de cette vulnérabilité nouvellement mise à jour. Si bien qu'elle se dit étonnée qu'Intel ait qualifié la gravité de cette vulnérabilité comme importante, alors qu'en 2009, le fondeur l'avait jugé comme critique. « Ce qui est vraiment intéressant dans cette attaque, ce sont les conséquences du mode de détournement de SINIT, notamment la capacité à contourner la TXT et le panneau de configuration LCP (Local Control Panel) d'Intel, mais aussi celle de compromettre le système de gestion de RAM (SMRAM), » a déclaré Joanna Rutkowska dans un blog.
Une vulnérabilité importante
Cette vulnérabilité est importante parce que la technologie Trusted Execution d'Intel sert d'extension matérielle aux microprocesseurs et aux chipsets du fondeur et son objectif est de fournir un mécanisme de protection contre les attaques logicielles. La TXT peut être utilisée par les entreprises pour contrôler la façon dont les informations sont stockées, traitées et échangées dans leurs systèmes. Intel a publié un avis ce lundi pour annoncer que la mise à jour des SINIT ACM et celle du microcode étaient disponibles afin de résoudre ce problème. Cependant, selon la CEO de Lab Invisible Things, le processus de correction a demandé un effort significatif à l'entreprise. « Intel a dû non seulement modifier les modules SINIT, mais aussi mettre à jour le microcode de tous les processeurs affectés. Le fondeur a dû également travailler avec les vendeurs de BIOS afin qu'ils livrent de nouveaux BIOS capables de charger inconditionnellement le microcode mis à jour (sans compter les mécanismes anti-rollback pour empêcher les BIOS et le microcode de revenir aux versions antérieures). Autant dire, un gros travail », explique le chercheur.
Pour ceux qui s'intéressent aux aspects techniques, Lab Invisible Things a publié un document de recherche qui décrit en détail le fonctionnement de la vulnérabilité et de l'exploit développé par les chercheurs pour contourner la TXT et le panneau de configuration LCP d'Intel. L'entreprise de sécurité conseille aux administrateurs système qui s'appuient sur cette technologie de demander les mises à jour du BIOS permettant de résoudre la vulnérabilité à leurs équipementiers respectifs et de les déployer dès que possible. Dans le cas où cette mise à jour ne serait pas encore disponible ou que la technologie n'est pas utilisée, Lab Invisible Things recommande tout bonnement de désactiver la TXT dans le BIOS.
Supercalculateurs : Bull renforce l'efficacité énergétique des bullx
Sur le terrain du calcul haute performance, Bull redouble d'efforts pour améliorer l'efficacité énergétique de ses supercalculateurs. Le constructeur national vient d'annoncer pour le deuxième trimestre 2012 le premier modèle de sa série bullx B700 DLC, pour Direct Liquid Cooling. Celui-ci recevra des lames double largeur équipées des futurs processeurs Xeon E5 (architecture Sandy Bridge) d'Intel. Bull indique que ce système est capable d'évacuer beaucoup plus de calories qu'un serveur lame classique (jusqu'à 80 kW par rack contre 40 kW actuellement), ce qui lui permettra aussi d'intégrer les prochaines générations d'accélérateurs de calcul (GPU) ou de processeurs MIC (many integrated core) d'Intel, multi coeur, ultra denses.
Le groupe français a par ailleurs annoncé sa série de lames de calcul bullx B510, destinée à des systèmes de quelques noeuds de calcul jusqu'aux HPC multi-pétaflopiques. Il indique que celles-ci ont déjà été retenues pour le supercalculateur Curie installé au centre TGCC, en France, ainsi que pour le système Helios pour F4E, à Rokkasho, au Japon, dans le cadre du projet ITER du CEA. Basée sur des noeuds de calcul bi-socket regroupés par paire sur une lame, la série bullx B510 offre une puissance en crête supérieure à 37 Tflops par rack. Elle s'appuie sur des processeurs Xeon E5 d'Intel, avec une capacité mémoire pouvant aller jusqu'à 256 Go par lame. L'interconnexion entre les noeuds est assurée par des liens InfiniBand QDR ou FDR. Les lames bullx B510 seront commercialisées de façon générale au premier trimestre 2012, lorsque les processeurs Xeon E5 seront disponibles.
Le châssis bullx 7U reçoit 9 lames doubles, soit 18 noeuds de calcul (crédit photo : Bull)
Un circuit d'eau à température ambiante
Pour réduire l'énergie consommée par ses systèmes, Bull utilisait déjà la technologie de porte froide. Avec la technologie DLC, ses équipes de R&D ont tablé sur un principe de refroidissement qui évacue la chaleur par un liquide situé au plus près des composants qui la génèrent. « Le refroidissement s'effectue à l'intérieur de la lame, par contact direct entre les composants chauds (processeurs, mémoires...) et une plaque froide dans laquelle circule un liquide caloporteur », explique le constructeur dans un communiqué. Dans la mesure où les processeurs fonctionnent à plus de 50° et les disques SSD à plus de 40°, un circuit d'eau à température ambiante suffit pour assurer le refroidissement. Le système peut donc être raccordé au circuit d'eau du site. En évitant de devoir produire de l'eau froide, on réduit d'autant la consommation électrique.
Un indicateur PUE réduit à 1,1
L'ensemble de ces dispositifs permet d'atteindre pour le système un indicateur d'efficacité énergétique (PUE*) de 1,1 dans des conditions normales d'utilisation, contre 1,8 pour les datacenters qui doivent recourir à d'autres équipements électriques, en particulier des climatiseurs. Bull précise en outre que ces serveurs présentent un niveau sonore très inférieur à celui des systèmes refroidis par air.
L'armoire bullx DLC a une capacité de montage de 42U (202 x 60 x 120 cm). Ses châssis 7U peuvent contenir 9 lames doubles, soit 18 noeuds de calcul. Le bullx B710 DLC fonctionne sous Red Hat Enterprise Linux et la suite bullx supercomputer.
(*) Le PUE (power usage effectiveness) mesure le ratio entre l'énergie consommé par l'ensemble de l'installation et l'énergie réellement consommée par les serveurs, établie à 1.
Illustration : bullx (crédit : Bull)
SC11 : Les futurs HPC exaflopiques doivent réduire leur consommation
A la Supercomputing Conference 2011 (SC11) qui se tient à Seattle du 12 au 18 novembre, l'objectif de parvenir au calcul exaflopique (exascale en anglais) dans la décennie, semble presque obsessionnel. Cette puissance de calcul multiplie par 1000 tout ce qui existe dans ce domaine aujourd'hui. Pour la plupart d'entre nous, une perspective à huit ou neuf ans est de l'ordre du long terme. Mais à la SC11, l'horizon de la décennie est déjà en vu. Une partie de la pression vient du département Américain de l'Énergie (DOE), lequel s'est engagé à financer ces énormes systèmes. Cet été, le DOE avait déclaré aux industriels qu'il voulait disposer d'un système exaflopique autour de 2019-2020, et que celui-ci ne devait pas consommer plus de 20 MW. Depuis, le gouvernement étudie les propositions sur la manière d'y parvenir.
Pour ce qui est de l'exigence de consommation de 20 MW, il y a déjà le supercalculateur qu'IBM construit pour le Lawrence Livermore National Laboratory, un laboratoire du Département de l'Énergie. En terme de puissance, ce système sera capable d'atteindre les 20 pétaflops (20 millions de milliards d'opération par seconde). Ce sera l'un des plus grands supercalculateurs au monde, mais aussi l'un des plus économes en énergie. Sauf que l'année prochaine, date à laquelle il sera complètement achevé et opérationnel, il consommera toujours entre 7 à 8 MW, selon IBM. Comparativement, un système exaflopique fournit une puissance de calcul de 1 000 pétaflops (soit mille millions de milliards d'opérations en virgule flottante par seconde). « Le monde dans lequel nous vivons désormais nous impose des contraintes en terme d'énergie, » a déclaré Steve Scott, CTO en charge de l'activité Telsa au sein de Nvidia Corp. « Si bien que la performance que nous pouvons obtenir sur un puce est limitée, non pas par le nombre de transistors que nous pouvons y mettre, mais plutôt par sa consommation énergétique. »
Combiner CPU et GPU pour améliorer le rendement énergétique
Selon le CTO, l'informatique x86 est limitée par ses processus de traitement qui impliquent des surconsommations. Alors que les processeurs graphiques, GPU, peuvent fournir du débit avec très peu de surcharge, et en consommant moins d'énergie par opération. Nvidia a construit des systèmes de calcul haute performance HPC avec ses GPU et des CPU provenant souvent de chez AMD. Une autre approche hybride, impliquant un GPU et un CPU, commence à se retrouver avec des processeurs ARM, un type de puce largement répandu dans les smartphones et les tablettes. Steve Scott pense que l'objectif de 20 MW demandé par le DOE peut être atteint en 2022. Mais si le programme exascale que veut lancer le gouvernement est accompagné par des financements, alors Nvidia pourrait mettre plus de ressources dans les circuits et les architectures. Dans ce cas, l'objectif pourrait être atteint en 2019. Selon le CTO de Nvidia, pour atteindre ce niveau d'efficacité, il faudra améliorer l'usage énergétique de 50 fois. Par ailleurs, si 20 MW semblent une puissance encore élevée, Steve Scott fait remarquer que les installations de cloud computing nécessitent jusqu'à 100 MW pour fonctionner.
Rajeeb Hazra, directeur général de l'activité Technical Computing chez Intel, avait déclaré que le fondeur comptait satisfaire aux exigences d'un exascale à 20 MW d'ici 2018, soit avec un an d'avance sur les attentes du gouvernement américain. Celui-ci avait apporté cette précision lors de l'annonce du processeur 50 coeurs Knights Corner, capable de fournir une puissance soutenue de 1 téraflop. Alors que les fabricants de matériel doivent résoudre des questions liées à la consommation d'énergie et à la performance, l'exaflopique, comme l'informatique pétaflopique, confronte les utilisateurs HPC à des défis de mise à l'échelle des codes, nécessaires pour utiliser ces systèmes à leur pleine capacité. Avant l'exascale, les fabricants vont produire des systèmes de l'ordre de la centaine de pétaflops, comme IBM, par exemple, qui affirme que son nouveau système Blue Gene/Q fournira une puissance de 100 pétaflops.
Pour l'heure, Kim Cupps, chef de la division informatique et directeur du projet Séquoia au Lawrence Livermore, se dit comblé, avec son système de 20 pétaflops à venir. « Nous sommes ravis d'avoir bientôt cette machine, » a t-il déclaré. « Grâce à ce système, nous allons résoudre de nombreux problèmes d'importance nationale, qui ce soit dans le domaine de la modélisation des matériaux, l'armement, le changement climatique et l'énergie.» Quant à l'annonce par IBM d'un système à 100 pétaflops. « C'est IBM qui le dit ! Je me porte garant pour 20 pétaflops ! » a t-il répondu.
(...)(16/11/2011 16:10:34)Dell, HP et IBM annoncent leurs serveurs Opteron 6200
Dell, HP et IBM, soit les 3 principaux fournisseurs de serveurs, ont fait part de leur intention de proposer des machines exploitant les Opteron 6200 d'AMD qui repoussent les limites du genre avec pas moins de 16 coeurs par processeur. Également connues sous le nom de code Interlagos, ces puces sont de 25 à 30% plus rapides que les précédentes (Opteron 6100 avec 12 coeurs) selon le fondeur de Sunnyvale.
Un plus grand nombre de coeurs sur les puces d'AMD pourrait apporter plus de performances aux serveurs avec certaines applications tout contribuant à la réduction de la consommation d'énergie, a déclaré Dan Olds, analyste chez Gabriel Consulting Group.
Des puces pour les bulles virtuelles
Les serveurs animés par ces processeurs travailleront plus vite dans les environnements fortement virtualisés accueillant des bases de données et calcul haute performance, a précisé M.Olds. Plus de coeurs sur les serveurs offrent une plus grande granularité dans la répartition des charges de travail et contribuent également à la consolidation des plates-formes serveurs dans un centre de calcul. «AMD a augmenté de manière plus significative qu'Intel le nombre de coeurs et ils offrent une certaine parité en milieu et haut de gamme » a déclaré Olds. Pour l'instant, Intel ne propose que 10 coeurs max sur ses puces serveur Xeon.
Si les processeurs Intel fournissent de meilleures performances brutes, AMD propose une meilleure réactivité avec sa puce, selon l'analyste. Alors que les entreprises cherchent à réduire leurs coûts, AMD offre de meilleures performances par watt avec ses dernières puces par rapport à celles d'Intel. Les Opteron 6200 puces sont basées sur une nouvelle micro-architecture processeur baptisée Bulldozer (voir détails sur la plate-forme).
5 serveurs attendus chez HP
HP a introduit pas moins de cinq serveurs ProLiant G7 avec des puces AMD Opteron 6200. On peut ainsi monter jusqu'à 2048 coeurs par rack, soit 33% en plus par rapport à la génération précédente, a indiqué le constructeur. Ces machines amélioreraient leurs performances de 35 % pour l'exécution de certaines applications. Ces serveurs seront disponibles à partir du 29 novembre aux États-Unis aux prix suivants : à partir de 2 679 $ pour le BL465c, 9 559 $ pour le BL685c, 3699 $ pour le DL385, 6309 $ pour le DL585 et 1 559 $ pour le DL165.
De son coté, IBM mettra à jour son serveur System x 3755 M3 en rack avec ces puces, a déclaré Jim Smith, un porte-parole d'IBM. La plate-forme sera probablement disponible dans le courant décembre. Reposant sur une carte mère quatre sockets, ce serveur se destine aux environnements virtualisés ou aux applications intensives comme les bases de données, a déclaré le speaker d'IBM. Avec ses 16 coeurs, cette machine est également une option pour ceux qui veulent des serveurs haute performance à un prix abordable. Signalons enfin que l'x 3755 M3 est le seul serveur d'IBM sur base AMD. Les mesures de performances de cette machine seront publiées très bientôt selon M.Smith.
Si Dell va également mettre à jour ses serveurs avec les dernières puces d'AMD, aucun communiqué n'a été publié à ce jour. On sait juste que le PowerEdge 815 passera de 48 à 64 coeurs avec les Opteron 6200.
Cray et Amax poussent la puce sur le HPC
Dans les prochaines semaines, ces processeurs seront également disponibles dans les serveurs d'Acer et de Cray, a indiqué AMD. Avant la conférence SC11 à Seattle, Cray a précisé qu'il construisait un supercalculateur baptisé Blue Waters pour le compte du National Center for Supercomputing Aplications à l'Université de l'Illinois. Ce système aura 49 000 processeurs Opteron 6200 16 coeurs et fournira des performances en pointe de 11,5 Pétaflops. Rappelons que Cray a remplacé au pied levé IBM, qui avait initialement été contactée pour construire le système.
Toujours à l'occasion du SC11, un petit constructeur spécialisé dans le HPC, Amax, a montré deux serveurs - 1U et 2U - pouvant accueillir jusqu'à quatre processeurs 16 coeurs. La machine 1U, la HA-1402, peut accueillir jusqu'à quatre puces 16 coeurs dans son châssis, avec trois disques durs dans les emplacements 3,5 pouces. Le HA-2403 au format 2U possède un peu plus d'espace pour le stockage et peut accueillir en sus des unités SSD.
| < Les 10 documents précédents | Les 10 documents suivants > |