Flux RSS
HPC
138 documents trouvés, affichage des résultats 41 à 50.
| < Les 10 documents précédents | Les 10 documents suivants > |
(16/06/2011 15:54:59)
Affaire Itanium : HP porte plainte contre Oracle
Quelques semaines après l'annonce tonitruante d'Oracle concernant la fin du développement d'applications (e-Business Suite, Hyperion, Oracle Database, Siebel ou encore Enterprise Manager) pour la plate-forme serveur Intel Itanium et la menace de procès de Hewlett-Packard, qui est aujourd'hui le principal utilisateur de l'architecture IA-64, la tension est encore montée d'un cran avec le refus de l'éditeur d'Oracle de corriger des bugs et le dépôt d'une plainte par HP.
L'éditeur de Redwood aurait refusé de fournir des correctifs pour des bogues critiques à destination des clients qui exploitent ses logiciels sur des serveurs HP Integrity. Dans une plainte déposée le mercredi 15 juin, HP allègue qu'Oracle pousse ses clients à abandonner la plate-forme Itanium - et donc les serveurs Integrity - au profit de ses propres solutions matérielles héritées du rachat de Sun en janvier 2010.
Après la menace, l'attaque juridique
L'action juridique de HP fait suite à la décision d'Oracle en mars dernier de mettre fin au développement de nouvelles versions de ses logiciels pour les processeurs Intel Itanium. HP accuse en effet Oracle d'avoir violé ses engagements juridiques afin de miner la vente de ses produits. « La fin soudaine du soutien à long terme d'Oracle pour la plate-forme Itanium est une décision calculée pour contrecarrer la concurrence de HP et nuire à ses clients », a déclaré Hewlett-Packard dans sa plainte, déposée devant la Cour supérieure de Santa Clara en Californie (voir illustration principale).
HP s'était déjà plaint la semaine dernière qu'Oracle déstabilisait ses clients en ne respectant par les accords conclus. Dans sa plainte, HP décrit en détail ce qu'elle considère les manoeuvres « coercitives » d'Oracle. Quand l'éditeur a annoncé son intention de mettre fin à tous les développements pour les systèmes Itanium, il a déclaré qu'il fournirait un support aux clients exécutant les versions existantes de ses logiciels sur la puce d'Intel. Au lieu de cela, selon HP, Oracle a refusé de fournir à ses clients sur Itanium des correctifs de bogues critiques pour ses logiciels.
« Oracle a déclaré à ses clients que les correctifs ne sont pas disponibles et que pour résoudre le problème ils devront passer à la prochaine version des logiciels d'Oracle (voir tableau ci-dessous ou lien) », assure HP. « Parce qu'Oracle a annoncé que les prochaines versions de ses logiciels ne fonctionneront pas sur les serveurs Itanium, cette ligne de conduite d'Oracle force de facto les clients à abandonner leurs serveurs Itanium pour des serveurs qu'ils ne préféreraient pas ». Oracle ne supporte plus aujourd'hui que les processeurs Intel et AMD x86-64, les puces maison Sparc et les PowerPC d'IBM. Pour les OS, on retrouve Windows, Linux, Solaris et Aix.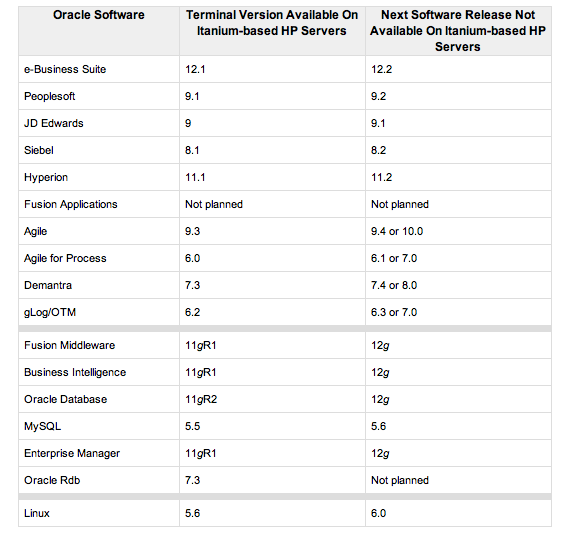
Cliquer sur l'image pour l'agrandir
[[page]]
Selon HP, Oracle aurait même été jusqu'à offrir les plates-formes matérielles à ses clients pour les pousser à abandonner les serveurs de HP. Suite au rachat de Sun et à l'arrivée de Mark Hurd (ex-CEO de HP) chez Oracle, la bataille s'est intensifiée entre les deux géants californiens. Impossible à ce jour de connaître le détail quant aux accords secrets passés entre HP et Oracle puisque la plainte rendue publique hier a été sévèrement caviardée pour éviter de dévoiler des informations confidentielles. Dans les parties visibles du document, HP accuse Oracle d'avoir rompu un accord tacite, de diffamations et d'interférences intentionnelles en vue d'exploiter un avantage économique potentiel.
Un porte-parole d'Oracle a refusé de commenter les allégations spécifiques de cette plainte. Dans un communiqué, Oracle nie toute malversation et accuse au contraire HP de l'avoir incité à signer un accord en septembre dernier l'engageant à poursuivre le support des systèmes Itanium, même si HP savait déjà à l'époque qu'Intel avait prévu d'arrêter le développement d'Itanium.
Oracle menace de mouiller Intel
« Nous pensons que HP a expressément demandé à Oracle une garantie de support à long terme pour Itanium dans l'accord passé en septembre 2010 parce que HP savait déjà tout des plans d'Intel concernant l'abandon d'Itanium et que HP était préoccupé par ce qui se passerait si Oracle découvrait ce plan, » a précisé Oracle.
Intel n'a pas annoncé l'abandon de la plate-forme Itanium. HP et le fondeur de Santa Clara insistent depuis plusieurs mois sur leur intention de poursuivre le développement de la puce IA-64. Kari Aakre, porte-parole d'Intel, a réitéré le mercredi 15 juin que le fondeur prévoit de livrer au moins deux générations d'Itanium, des processeurs connus sous les noms de code Poulson et Kittson. Pourtant, Oracle a déclaré mercredi que « les plans d'Intel pour mettre fin à l'Itanium seront a révélé au tribunal. »
À partir du document lourdement expurgé (la plainte de HP, voir ci-dessous), il est très difficile d'établir si Oracle a bien violé le contrat qui le lié à HP. Un porte-parole de HP a refusé de fournir tout commentaire supplémentaire. Certaines des injonctions demandées par HP sont également censurées. La firme de Palo Alto demande en effet au tribunal de contraindre Oracle à réviser sa position sur Itanium, de l'empêcher de faire des «déclarations fausses et trompeuses » sur Itanium, et de payer des dommages et intérêts, selon la plainte déposée.
Cliquez sur l'image pour l'agrandir
IBM porte le HPC dans le cloud
Pour Brian Connors, vice-président de l'activité HPC au sein d'IBM, le logiciel nommé HPC Management Suite for Cloud « réunit des environnements HPC qui sont traditionnellement isolés en mode silos ». Généralement, les entreprises qui ont des opérations d'ingénierie complexes privilégient des fermes de serveurs séparées et qui ne sont utilisées que par quelques groupes d'ingénieurs. Cette méthode laisse souvent des ressources de calcul inutilisées. Pour beaucoup d'entreprises, la mutualisation de plusieurs systèmes HPC peut avoir des avantages qui vont au-delà du simple gain d'efficacité. En combinant toutes les ressources des systèmes haute performance d'une entreprise, des équipes d'ingénieurs pourraient avoir accès à davantage de coeurs et ainsi terminer les projets plus rapidement.
IBM a testé ce logiciel en interne avant de le rendre disponible pour les entreprises. Plus de 3 000 ingénieurs à travers le monde au sein de l'activité System Development ont partagé des ressources pour développer la famille de processeurs Power7. Big Blue prétend ainsi avoir réduit les coûts de moitié et baissé le cycle de conception de six mois avec le logiciel.
Des versions optimisées pour différentes industries
Cette solution fonctionne sur les serveurs x86 ainsi que la plate-forme Power d'IBM. Elle n'utilise pas de virtualisation, qu'évitent les ingénieurs, car cela peut ralentir le travail. IBM fournit également un logiciel de gestion des charges. Le redémarrage des machines n'est pas nécessaire en cas de changement de workload, indique Brian Connors.
Le constructeur offre aussi des services d'accompagnement à l'installation et à l'utilisation de la solution. La verticalisation du produit intéresse IBM, qui va proposer une version optimisée pour les entreprises spécialisées dans l'électronique, les constructeurs automobiles et l'industrie aéronautique. IBM n'est pas le premier à proposer un tel logiciel pour une meilleure utilisation des ressources HPC. En 2009, Platform Computing offrait des outils pour que ses clients construisent des clouds privés regroupant plusieurs clusters. Microsoft Azure et SGI ont fait de même plus récemment.
Les services HPC cloud d'IBM seront disponibles au troisième trimestre.
Cray intègre GPU/CPU dans ses supercalculateurs
Le Cray XK6, qui vient d'être présenté, montre un environnement de programmation reposant sur une combinaison x86/GPU (processeur classique/graphique). « L'intégration des GPU avec nos systèmes provient de la demande des clients » précise Barry Gras, vice-président des produits Cray. Il a admis que l'entreprise n'a pas été la première à intégrer ces capacités - IBM a longtemps utilisé cette technologie pour ses propres systèmes - mais ce procédé est le plus à même et le moins coûteux pour proposer des capacités de calcul en exascale. Le modèle actuel XK6 prépare le terrain pour ce type de calcul souligne le dirigeant.
Les GPU ne sont pas destinés pour le rendu des graphiques sur l'écran, mais sont utilisés pour le traitement des grands volumes de données. En étant spécialisé, ils sont plus rapides et plus efficaces que les puces x86.
Arriver à 50 petaflops
Les équipements présentés comprendront des GPU Nvidia Tesla 20, ainsi que des processeurs AMD Opteron Série 6200 (nom de code «Interlagos») et le système d'interconnexion Gemini de Cray. Le constructeur indique qu'il peut assembler des machines XK6 jusqu'à une puissance de traitement de 50 petaflops (à titre de comparaison, les équipements en tête du classement des supercalculateurs sont capables de traiter chacun entre 2,4 et 2,5 petaflops).
La société a également annoncé le premier client de XK6, le centre de supercalcul à Manno en Suisse. Il va moderniser son système Cray XE6m, appelé « Piz Palu » vers une configuration XK6. Le centre utilise le supercalculateur dans plusieurs domaines comme les prévisions climatiques.
Les clients disposant de systèmes XT4, XT5, XT6 ou XE6 pourront migrer vers XK6 en remplaçant les lames actuelles par des modules XK6.
Sapphire 2011 : SAP et Dell, partenaires pour le cloud et l'in-memory
Dans un premier temps, les clients de SAP seront en mesure de déployer les applications au sein de l'environnement VIS Next Generation Datacenter Platform de Dell. Celui-ci a été renforcé ces dernières années par des acquisitions comme celle du vendeur de solutions de stockage optimisées Ocarina Networks ou encore celle de Scalent Systems, spécialisé dans les logiciels de virtualisation pour les datacenters. « Pendant Sapphire, SAP et Dell seront rejoints par un représentant de l'Université du Kentucky, laquelle a décidé de migrer son implémentation SAP vers un cloud géré par Dell, » a déclaré Kaj Van de Loo, vice-président senior de la stratégie technologique chez SAP. « Voilà quelques années que SAP a achevé ses travaux de recherche et de développement pour s'assurer que son logiciel pouvait être facilement virtualisé. Mais des tests et une certification ont été nécessaires pour valider la compatibilité avec les outils de gestion et d'autres éléments de la plate-forme de Dell, » a ajouté le vice-président.
HP, Fujitsu et Dell partenaires matériels de SAP
Dell va également rejoindre le cercle des fournisseurs de matériel qui proposent des solutions utilisant la technologie in-memory database HANA de SAP. Le traitement en mémoire permet de conserver les données à traiter dans la RAM au lieu de les lire sur disque, ce qui offre de meilleures performances. Les boîtiers HANA peuvent traiter des données provenant aussi bien de SAP que d'autres sources, et supportent également une série d'applications spécialisées destinées à gérer des situations spécifiques, en fonction de l'activité. Selon un communiqué, les machines HANA de Dell utiliseront le puissant serveur rack PowerEdge R910. Le distributeur de boissons alcoolisées Charmer Sunbelt Group fait parmi des premiers clients du système, selon un communiqué.
Hewlett-Packard et Fujitsu sont également partenaires de la plate-forme matérielle HANA. Tous vont livrer des machines répondant à un standard de tailles « petites, moyennes et grandes », qui donnera une indication globale quant à la puissance sous-jacente, » a indiqué Kaj van de Loo. Pour l'instant, les grilles de tarifs sont rares, mais elles devraient sortir au moment de la disponibilité de HANA, soit au mois de juin prochain.
Des appliances en plein essor chez SAP, Oracle et IBM
Les projets de SAP concernant HANA contrastent avec la solution de base de données Exadata Database Machine d'Oracle, qui repose sur un hardware propre à Oracle. « Nous savons que les clients sont déjà engagés dans des relations qu'ils veulent maintenir, » a déclaré le vice-président. « Mais nous sommes convaincus que cette stratégie va nous aider à innover, dans un domaine où tout autre pourrait être tenté de proposer une pile intégrée tous usages. »
IBM de son côté va lui aussi proposer des appliances hautes performances exploitant la base DB2. Comme nous l'a confié Didier Faulque, vice président System & technology group chez IBM France, « l'idée consiste à proposer des solutions dans le cadre de notre programme Smarter Computing, des systèmes Big Data pour gérer les nouvelles natures des données structurées et non structurées et accélérer les workloads avec des systèmes optimisés pour du DB2 intensif. Le but n'est pas de proposer des performances 2 à 3 fois supérieures, mais 10 fois supérieures... »
IBM veut porter les technologies de Watson dans les entreprises
« IBM espère que les technologies sous-jacentes de Watson pourront être exploitées dans des domaines où il s'agit de fournir des réponses précises à des requêtes complexes, via des interfaces faisant appel au langage naturel, » a déclaré la semaine dernière Guru Rao, ingénieur système en chef chez IBM. « Appliquées aux entreprises, les technologies sous-jacentes de Watson pourraient analyser des montagnes de données structurées ou non structurées, et donner des réponses auxquelles on pourra accorder un niveau de confiance élevé. »
Selon le chercheur, les technologies de Watson seraient applicables à de nombreux secteurs. Par exemple, les services de santé pourraient bénéficier de réponses précises pour diagnostiquer des maladies ou des banques pourraient détecter des fraudes à la carte de crédit en temps réel. Ces technologies pourraient également être utilisées dans des affaires juridiques pour fournir des réponses pertinentes fondées sur des recherches prenant en compte les éléments de preuves disponibles. « Dans le domaine de la santé, plus on dispose d'informations sur les maladies, plus notre connaissance est précise. Avec un système de requêtes utilisant les formulations du langage naturel, on pourrait profiter d'un degré de précision encore plus élevé, » a déclaré Guru Rao.
Au mois de février, lors de la finale du Jeopardy opposant l'homme à la machine, le supercalculateur Watson d'IBM a battu les champions en titre Brad Rutter et Ken Jennings. Le jeu a montré que des ordinateurs pouvaient répondre à des questions demandant un niveau élevé de réflexion, un peu comme les humains. Watson a répondu aux questions posées par l'animateur (l'ordinateur ne parle pas, mais ses réponses ont été lues par une voix de synthèse). Des statistiques sur le degré de pertinence des réponses étaient aussi affichées sur un écran.
Un supercalculateur conçu dans un but précis
« Watson repose sur une architecture avec des processeurs Power7 en parallèle affichant un total 2 680 coeurs environ, » a expliqué le chercheur. « Sur les 15 To de données stockées dans sa mémoire, seul 1 To a été utilisé pour répondre aux questions, » a ajouté Guru Rao. Des algorithmes spécifiques ont permis le traitement des requêtes en langage naturel, tandis que d'autres logiciels et algorithmes ont pris en charge les requêtes en les associant à des mots-clés, des réponses connues et d'autres informations stockées dans le système. « Ce dernier a pu traiter l'information en parallèle en conservant les données en mémoire, ce qui réduit les temps de latence et les problèmes de lecture/écriture quand les données sont stockées sur un disque, » a déclaré le chercheur.
« Grâce au traitement des données en mémoire, à ses capacités d'analyse et au matériel extrêmement performant dont il est composé, Watson a répondu aux questions en deux à trois secondes, » a ajouté Guru Rao. Celui-ci a notamment utilisé le General Parallel File System d'IBM (GPFS) et des logiciels comme Hadoop, lequel fournit une plate-forme pour analyser des données structurées et non structurées en parallèle à travers plusieurs serveurs. « IBM va probablement travailler avec des partenaires pour construire des architectures serveur autour de Watson, utilisables en entreprise, » a encore déclaré l'IBMer. Les technologies logicielles de Watson pourraient être adaptées à des appareils dédiés à des fonctions spécifiques, comme la sécurité et la conformité.
Des améliorations constantes
Watson atteste des progrès réalisés dans le domaine informatique. En 1996, son ancien collègue Deep Blue avait perdu une finale d'échecs contre le champion du monde Garry Kasparov. Mais il avait pris sa revanche en 1997, remportant plusieurs matchs contre Kasparov, après une mise à niveau améliorant ses performances. « Je ne vois pas IBM fournir un service de jeu vidéo basé sur Watson ! » a déclaré Guru Rao. « Notre but n'est pas de produire des jeux pour ordinateur, mais d'utiliser cette science informatique révolutionnaire pour répondre à des besoins au niveau des entreprises. » IBM veut aussi faire la démonstration de nouvelles interactions possibles entre l'homme et l'ordinateur et montrer comment extraire des informations pertinentes d'une masse de données disponibles.
L'entreprise a ajouté des FPGA (réseau de portes programmables in situ) pour réaliser des traitements de données spécifiques sur les serveurs, tout en ajoutant plusieurs coeurs pour accélérer les processeurs. Big Blue est également en train de redessiner les serveurs pour réduire la latence entre le processeur et la mémoire, de façon à accélérer les performances des applications. Le serveur EX5 conçu par IBM, présenté l'an dernier, s'éloigne de l'architecture traditionnelle des serveurs x86 : le constructeur a découplé la mémoire des processeurs en les intégrant dans des boîtes séparées ce qui permet aux serveurs d'accéder à un pool de mémoire plus grand. Par ailleurs, la firme d'Armonk a conçu une puce particulière, juxtaposée à la CPU, qui réduit la latence entre la mémoire et le processeur. « La technologie EX5 pourrait également inclure un système de stockage flash pour procurer de la mémoire supplémentaire, » a expliqué Guru Rao.
Illustration principale : Guru Rao, ingénieur système en chef chez IBM
A Grenoble, HP valide les solutions HPC de ses clients
Pourquoi les clients ont besoin de HPC s'est interrogé Xavier Poisson Gouyou Beauchamps, directeur des ventes EMEA cloud et HPC et d'apporter plusieurs réponses, une augmentation de capacité de calcul pour réduire les coûts, travailler sur des sujets aussi variés que la simulation, la recherche, mais aussi le divertissement. Il a présenté le centre de benchmark HPC qui est basé dans les locaux de Grenoble. Ce centre permet aux différents clients de HP de pouvoir tester, analyser in situ, comparer les différentes configurations de calcul haute performance selon leur besoin propre.
Différents types de POC (proof of concept) peuvent être imaginés, comprenant plusieurs topologies de noeuds, d'évolutivité technique (capacité de stockage, type de processeurs, besoin de connectivité). Ces tests peuvent durer jusqu'à 6 mois. Ces installations fonctionnent en général à 80% 24h/24 et 7j/7. L'objectif avoué est de trouver le bon équilibre entre les besoins de calcul du client et l'infrastructure souhaité par le client. Xavier Poisson le rappelle « des projets de HPC ne sont pas des investissements sur 1 an, mais sur 3 à 5 ans ». Une raison de plus pour bien tester son projet.
Ces tests et ces comparatifs permettent aussi selon Xavier Poisson de répondre aux grands défis pour les prochaines années que sont le contrôle de la consommation énergétique et l'amélioration de la bande passante (temps réel, faible taux de latence, connexion réseau). Une première réponse est apportée par la modularité de ce type de salle via les containers POD proposés par HP. Mais le constructeur mise aussi sur ces partenaires et notamment Intel. Ce dernier est revenu sur les dernières annonces du fondeur concernant les puces Xeon E7 améliorant la performance tout en diminuant la consommation énergétique, via des technologies comme Turbo Boost ou l'Hyper Threading.
De l'accélération de particules au cinéma
L'intérêt pour le calcul haute performance comprend des activités variées. Sur le plan scientifique par exemple, le Cern est très friand de ce type d'infrastructures. Surtout avec la mise en place de son accélérateur de particules. Celui-ci, selon le Dr Pierre Vande Vyvre du Cern, doit répondre à plusieurs questions dont l'origine de la masse des particules, peut-on unifier toutes les forces présentes, etc. ? Lors d'une simulation d'une collision de particules, l'impact est photographié avec des temps de décompositions de l'ordre de la nanoseconde, les chercheurs ont été confrontés à deux problématiques sur les données récupérées.
La première concerne la définition de la qualité des informations. Pour ce faire, le Cern a imaginé avec HP une traitement à la volée basé sur des algorithmes spécifiques. En matière de matériel, le laboratoire genevois s'est équipé en HPC 7000, BL2x 220c G6 (Intel E5540 : 2,53 GHz 4 cores) et l'intégration de 40 agents pour capter les données. Cette configuration a été testée à Grenoble et ensuite installée au Cern. Le résultat est une diminution du nombre de rack en passant de 3 à 1, mais également une meilleure analyse des données avec un facteur 3 à 4 par rapport à l'architecture existante 2 ans auparavant. La seconde problématiques était la compression des donnés et leur archivage. A chaque collision, près de 1000 « clichés » peuvent être intéressantes et cela représente un volume de 1 à 50 Mo d'informations à numériser. L'infrastructure déployé par HP a permis une forte amélioration du stockage de ces donnés.
Le cinéma gourmand en HPC
En matière de cinéma, la société française Quinta, spécialiste de la postproduction a elle aussi fait appel au savoir-faire d'HP. La problématique est simple, les films demandent de plus en plus d'effets spéciaux et d'intégration d'images 3D. Ces procédés sont gourmands en ressources informatiques et les sociétés de post-production sont confrontées à des contraintes budgétaires importantes. Cela demande donc des efforts sur la climatisation et contrôle des coûts énergétiques, la gestion de la place au sol et l'optimisation de la supervision.
Pour répondre à ces exigences, Quinta a fait appel au centre de benchmark d'HP qui a travaillé sur une architecture de 225 serveurs SL2 x 170z avec double processeur Intel Xeon 5620 cadencé à 2,4 Ghz et 24 Go de mémoire DDR3. Le résultat parle de lui-même : les performances ont été multiplié par deux, le nombre de rack est passé de 6 à 3 gagnant ainsi de la place au sol. Les coûts ont été réduits de 30 à 40% sur le refroidissement de la salle et de 10% sur la facture d'électricité. La société précise que le temps d'intégration des 225 serveurs a été rapide (4 jours).
Un supercalculateur Bull de 1,92 Tflops à la Réunion
Le supercalculateur choisi est de la famille Bullx, de Bull. Il est composé de 20 noeuds R422-E2 et un noeud SMP BullX S6030 reliés par un réseau InfiniBand. Au total, 200 coeurs offriront une puissance de calcul de 1,92 Tflops. 36 To de données seront partagées. Le coût du projet n'a pas été communiqué.
Illustration principal : Chassis Bullx 7u, crédit D.R. (...)(07/04/2011 15:46:03)
Un cluster Linux HPC de 10 000 coeurs dans le cloud d'Amazon
« C'est un chiffre rond très agréable», explique Jason Stowe, le PDG et fondateur de Cycle Computing, un fournisseur qui aide les clients à acquérir un accès rapide et efficace aux supercalculateurs habituellement réservés aux universités et aux grands laboratoires de recherche. Cycle Computing avait déjà construit quelques clusters sur le Cloud d'Amazon Elastic Compute qui pouvaient évoluer jusqu'à quelques milliers de coeurs. Mais Jason Stowe veut passer à une étape supplémentaire : l'allocation de 10 000 coeurs sur Amazon dans un cluster HPC. Cela implique d'utiliser une technologie d'ordonnancement de commandes et d'exécuter une application HPC optimisée.
« Nous n'avons pas trouvé de références sur quelque chose d'aussi grand », précise le dirigeant. Sur les tests de capacité de traitement, l'architecture de cluster basé sur Linux proposée sur Amazon serait assez importante pour intégrer le Top 500 des supercalculateurs les plus rapides du monde. Il revendiquerait la 114ème position avec 66 Terflops. Une des premières étapes a été de trouver un client qui bénéficierait d'un tel grand cluster. Il n'y a pas beaucoup d'utilisateurs pour ce type de supercalculateur. L'heureux élu est l'entreprise de biotechnologie Genentech, basée à San Francisco, où Jacob Corn, scientifique indique avoir besoin des capacités de calcul pour examiner comment les protéines se lient les unes aux autres. Cette recherche pourrait éventuellement mener à des traitements médicaux. Le scientifique indique par rapport au cluster de 10 000 coeurs, « nous sommes à un dixième de la taille en interne».
Du cloud et une dose de savoir-faire
Cycle Computing et Genentech ont déployé ce cluster le 1er mars dernier, un peu après minuit, sur les conseils d'Amazon, car il s'agissait du moment idéal pour mobiliser les 10 000 coeurs. Même si Amazon propose des instances de machines virtuelles optimisées pour l'informatique haute performance, les deux protagonistes du projet ont plutôt opté pour un cluster Linux reposant sur le standard « Vanilla CentOS » afin d'économiser de l'argent, souligne Jason Stowe. CentOS est une version de Linux basée sur une distribution Red Hat.
Les 10 000 coeurs sont composés de 1 250 instances avec huit coeurs chacun, ainsi que 8.75 To de RAM et 2 Po d'espace disque. 45 minutes ont été nécessaires pour mettre à disposition l'ensemble du cluster. Ce dernier a été utilisé pendant huit heures à un coût de 8 500 dollars, incluant toutes les redevances à Amazon et Cycle Computing. Pour Genentech, cet exercice n'était pas cher et se révèle plus simple que d'acheter 10 000 coeurs pour son propre centre de données et de les utiliser sur une courte durée. Jacob Corn explique qu'en utilisant ses propres ressources, les simulations auraient pris des semaines ou des mois car l'approche avec Amazon repose sur du calcul brut et ne s'embarrasse pas du dialogue entre les noeuds et certains effets du traitement massivement parallèle.
Cycle Computing a utilisé son propre logiciel CycleCloud, le système de planification pour le cluster et Chef Condor, un framework Open Source pour la gestion et la configuration. La société a également utilisé une partie de son logiciel pour détecter les erreurs et redémarrer les noeuds si nécessaire, un système de fichier partagé, et quelques noeuds supplémentaires au-dessus des 10 000 pour traiter certaines tâches. Pour assurer la sécurité, le cluster a été conçu avec Secure-HTTP et un chiffrement de 128/256 Advanced Encryption Standard (AES).
Crédit Photo: D.R
(...)
IBM multiplie les initiatives dans le domaine de l'eau
Au coeur des débats, des conflits et plus récemment des catastrophes naturelles, l'eau est aussi bien source de vie, que vecteur de désastre important. Pour prévenir, anticiper et améliorer, IBM a choisi cette ressource pour apporter son expertise informatique autour de 3 thèmes, les mers, les fleuves, les rivières (avec la surveillance de la qualité des eaux et autres indicateurs) ; les infrastructures (barrage, digues, tuyaux) et enfin les usages dans la ville via les compteurs intelligents, mais aussi des capteurs pour les fuites. Sur ces axes de travail, IBM a conçu des centres d'excellence, dont 3 sont en Europe, Olivier Hess est responsable de celui de Montpellier. « Le premier à avoir été créé est celui d'Amsterdam à la fin 2006 où IBM et d'autres partenaires ont travaillé sur la gestion intelligente des digues, comment éviter ou prévenir les risques de fissures ou plus graves de digues qui cèdent » explique-t-il. Un autre centre à Dublin s'intéresse quant à lui à la problématique de l'eau dans son environnement. Ainsi la baie de Galway en Irlande s'appuie sur un système de capteurs, qui récupèrent un grand nombre d'informations en temps réel sur l'état de l'eau, et sur des portails qui en publient l'analyse.
Une utilisation prédictive du HPC
Et Montpellier ? Le petit nouveau, comme le surnomme Olivier Hess, « est en charge de la modélisation des fluides. Nous utilisons le HPC (le calcul haute performance) pour anticiper un phénomène comme les inondations ». Concrètement, l'objectif est qu'en cas d'alerte météo, les autorités publiques (préfets, mairies, etc) disposent d'une évaluation des risques encourus et puissent ensuite prendre certaines décisions (évacuations, informations aux citoyens, organisation des secours). « Nous travaillons pour que cette évaluation soit la plus rapide possible, la décision doit se prendre en général entre 6 et 12h après les alertes » rapporte Olivier Hess en avouant « que les premiers tests ne donnaient que des résultats en quelques...jours ». Interrogé sur une éventuelle utilisation du cloud comme support pour améliorer et accélérer ses prévisions, le responsable reste pragmatique « c'est un axe de travail possible, mais en ce qui concerne nos recherches, nous préférons utiliser un cluster dédié à 100% ». Par contre, les 3 centres d'excellence ne vivent pas en circuit fermé et les découvertes des uns profitent aux autres. « Quand des digues se rompent, nos recherches sur la modélisation des fluides pourront apporter des réponses » rappelle Olivier Hess. Idem pour l'expérience menée à Dublin dans la baie de Galway, où prévisions et mesures pourront anticiper les risques de pollution du milieu marin en cas de forte pluie. Le champ d'investigation est donc important pour les ingénieurs d'IBM.
| < Les 10 documents précédents | Les 10 documents suivants > |