")
Un an après avoir racheté Hortonworks, Cloudera lance la plateforme de données intégrée sur laquelle les deux équipes réunies ont travaillé activement depuis le début de l’année. En mars, l’éditeur avait eu l’occasion de présenter dans les grandes lignes cette CDP, Cloudera Data Platform, et les premières intégrations réalisées entre les deux offres, lors de l’événement DataWorks Summit 2019, à Barcelone. Les principales nouveautés concernent les services de datawarehouse et d'apprentissage machine conçus pour le cloud et le Data Hub permettant de migrer les charges de travail on-premise vers le cloud. Comme attendu, la plateforme apporte des capacités multifonctions sur les charges de travail analytiques proposées « as a service », à exploiter sur un large éventail de cas d’usages, en incluant les applications basées sur l’IA et celles situées en bout de réseau (at the edge). La CDP apporte 5 ensembles de services pour l’exploitation des données : des outils de gestion des flux et du streaming, des outils d’ingénierie de données, un datawarehouse natif cloud, une base de données opérationnelle et un service d’apprentissage machine natif cloud.
Sur la protection et la gouvernance des données, la CDP intègre les technologies SDX, shared data experience, qui doivent permettre de créer un data lake sécurisé, quel que soit le cloud utilisé. La mise en place de ces fonctions se fait « en quelques heures plutôt qu’en termes de jours ou de semaines », assure Arun C. Murthy, chief product officer de Cloudera. A l’heure du multicloud, la plateforme disponible on-premise et en mode hybride pourra être déployée sur différents clouds, avec des métadonnées et des fonctions de sécurité et de gouvernance partagées. Les services Data Warehouse, Machine Learning et Data Hub de la CDP sont accessibles sur le cloud public d'AWS.
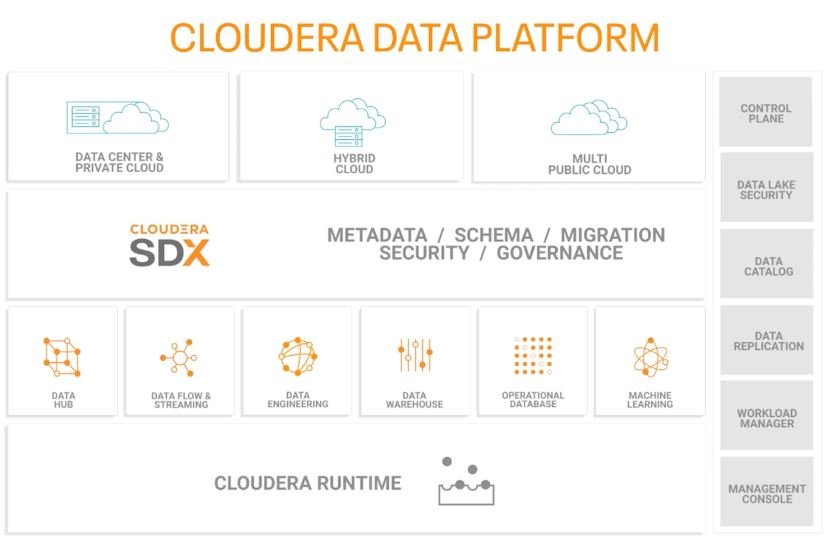
Les outils de métadonnées et de sécurité de la CDP sont partagées sur l'ensemble des services. Parmi les utilisateurs de la CDP, le groupe pharmaceutique GlaxoSmithKline compte mettre à profit les capacités SDX pour gérer ses métadonnées et sa gouvernance sur l’information de façon centralisée.
Mise à l'échelle automatique du datawarehouse
Sur la partie datawarehouse, qui exploite des moteurs open source comme Impala, Hive LLap, Hive on Tez et des outils tels que Hue ou Workload XM, Cloudera met en avant les capacités de mise à l’échelle automatique du service pour accueillir des centaines d'utilisateurs supplémentaires, ainsi que l'exploitation simultanée des différents services analytiques en partageant les métadonnées et les fonctions SDX. Les charges de travail on-premise, pour le reporting, les tableaux de bord, les requêtes ad hoc ou l’analytique avancée, peuvent être déplacées sur le cloud et sont accessibles en self-service. « Des centaines d’utilisateurs peuvent provisionner leurs propres ressources sur un clic et analyser les données en même temps, que ce soit on-premise ou dans le cloud », pointe Anupan Singh, general manager pour le datawarehouse chez Cloudera. Pour l’analyse de données, le datawarehouse peut s’exécuter directement au-dessus des espaces de stockage objets sans requérir de dupliquer les données dans des espaces spécifiques.
L’entrepôt de données cloud est intégré avec les outils d’apprentissage machine et avec le service Data Hub. Ce dernier permet aux utilisateurs de migrer la gestion des données on premise et les charges de travail analytiques vers le cloud où ils pourront mettre en place de nouveaux workloads à travers un choix de types de cluster, de workloads, d’infrastructures, d’options de configuration et de personnalisation. Avec cette offre, Cloudera va affronter sur le marché la concurrence d'un pure player du datawarehouse natif cloud, Snowflake, qui a su ces dernières années conquérir des clients à un rythme accéléré avec ses capacités élevées de mise à l'échelle et sa rapidité de traitement sur de gros volumes s'appuyant sur une base de données en colonnes. Il trouvera aussi face à lui Google Big Query, Amazon Redshift ou encore Oracle Autonomous Datawarehouse.
Services de datawarehouse et de ML facturés à l'heure
Sur la partie Machine Learning, la CDP permet aux data scientists et développeurs de déployer en quelques clics des espaces de travail pour les projets, les data scientists pouvant utiliser les outils de leur choix et répliquer les jeux de données en environnement hybride, là aussi en maintenant les contrôles de sécurité et de gouvernance. La CDP fournit une expérience utilisateur englobant le traitement des données, l’entraînement des modèles, le suivi de l’expérimentation, ainsi que le déploiement et la gestion des modèles de production. A cela s'ajoute la possibilité de porter les données dans différents environnements « sans créer des silos déconnectés » et sans modifier l’expérience des data scientists pour créer des processus ML de bout en bout, assure Cloudera. La concurrence ne manque pas non plus sur le terrain de l'apprentissage machine avec les offres clouds de Machine Learning d'Amazon Web Services, Google, Microsoft Azure et IBM pour ne citer que les principales. Cloudera fera valoir les avantages d'une plateforme intégrée à déployer en environnement hybride.
Les services cloud Data Warehouse, Machine Learning et Data Hub sont disponibles sur le cloud public d’AWS et facturés à l’heure pour différents types d’instances et différentes options de CPU, GPU et RAM. Une option on-premise, CDP Data Center, est actuellement disponible en préversion pour un nombre limité de clients de Cloudera. Elle sera livrée à l’échelle mondiale d’ici la fin de l’année et vendue sous forme d’abonnement annuel démarrant à 10 000 dollars par nœud. D’autres détails de tarification sont fournis sur le site de l’éditeur.
Commentaire