")
Twitter et ses messages contraints à 140 caractères constituent un champ d’exploration singulier pour l’analyse du discours politique. A cet égard, les élections présidentielles de mai 2017 ont fourni un terrain d’expérimentation propice aux chercheurs des laboratoires Agora et Etis (Ensea, UCP, CNRS UMR 8051). Directeur de recherche en linguistique à l’Université de Cergy-Pontoise, Julien Longhi a constitué une méthode d’étude de la sémantique des discours. C’est lui qui a porté le projet d’analyse des tweets politiques #Idéo2017, financé par la Fondation UCP. Ce projet s’est appuyé « sur un travail préparatoire effectué entre 2014 et 2016, avec un corpus de tweets constitué autour des élections municipales 2014 qui a permis de mettre en place #Idéo2017 pour les tweets de la campagne 2017 », nous a-t-il expliqué.
Accessible sur le web au printemps dernier, la plateforme a permis à tout un chacun de s’essayer à l’analyse linguistique de l’actualité politique sur les corpus de tweets postés par les 11 candidats à la Présidence de la République. Elle proposait d’une part une analyse des messages par candidat et d’autre part une analyse de tous les tweets contenant un mot choisi dans une liste prédéfinie de 13 mots parmi lesquels France, Etat, Sécurité, Loi, Travail ou encore Liberté. A la manœuvre derrière le portail, le moteur de recherche Elasticsearch dans sa version open source et des scripts développés dans l’outil d’analyse textuelle Iramuteq.
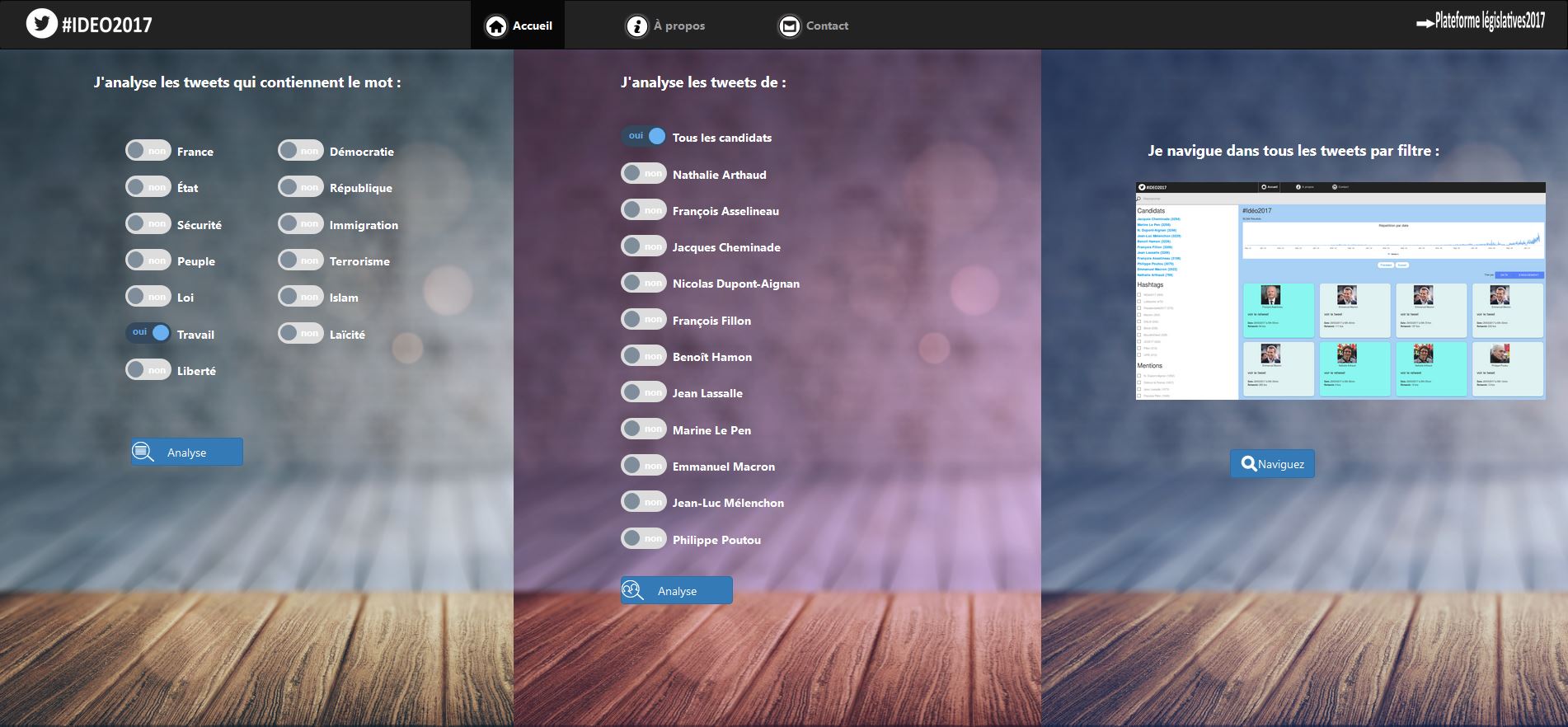
Sur #Idéo2017, on peut toujours analyser les tweets des 11 candidats à la campagne présidentielle à travers le moteur Elasticsearch. (agrandir l'image)
Une fois la Présidentielle passée, la plateforme s’est axée sur les messages Twitter liés aux Législatives. Elle propose maintenant une veille sur le quinquennat du Président Macron à partir des tweets des principaux responsables politiques.
Elasticsearch récupère les formes déclinées d'un mot
« J’ai des exigences linguistiques assez fortes, on ne fait pas n’importe quoi avec les mots », souligne Julien Longhi en rappelant qu’avec le big data, « on récupère une masse de données textuelles, mais on ne regarde pas l’organisation textuelle ». On ne tient par exemple pas compte de la fréquence, ni des champs lexicaux autour d’un thème, explique-t-il. Par ailleurs, la recherche en plein texte risque de restituer des résultats non pertinents pouvant influencer l’analyse linguistique en ramenant des faux positifs comme « emploi » avec une recherche sur le mot « loi ». D’où le choix du moteur Elasticsearch qui utilise un algorithme de pertinence et qui apporte une ouverture linguistique en récupérant les formes déclinées d’un mot.
Ainsi, « sur un mot comme travail, on récupère aussi travailleurs et travailleuses tandis qu’avec la textométrie, on récupère travail et c’est tout », pointe Julien Longhi. A travers Elasticsearch, #Idéo2017 permet aussi « d’effectuer des recherches avancées telles que la navigation par facettes pour explorer le corpus de tweets », explique Julien Longhi. Les utilisateurs peuvent filtrer les messages en choisissant à partir de trois filtres : l’un affichant les tweets par candidats, un autre filtrant par hashtag et le troisième par mention.
Kibana restitue les spécificités de Twitter : timelines, hastags...
Destinée au public le plus large, la plateforme devait rendre accessible en ligne un travail réalisé offline en offrant des requêtes simples et rapides sur les données. « Je voulais que ces résultats soient compréhensibles par des gens qui ne soient pas des chercheurs, pas des linguistes », ajoute le chercheur en linguistique en soulignant la qualité de la visualisation de données proposée par l’interface Kibana associée à Elasticsearch. « Cela fonctionne vraiment bien pour tout ce qui est lié aux spécificités de Twitter, les timelines, les hashtags utilisés, les mentions ».
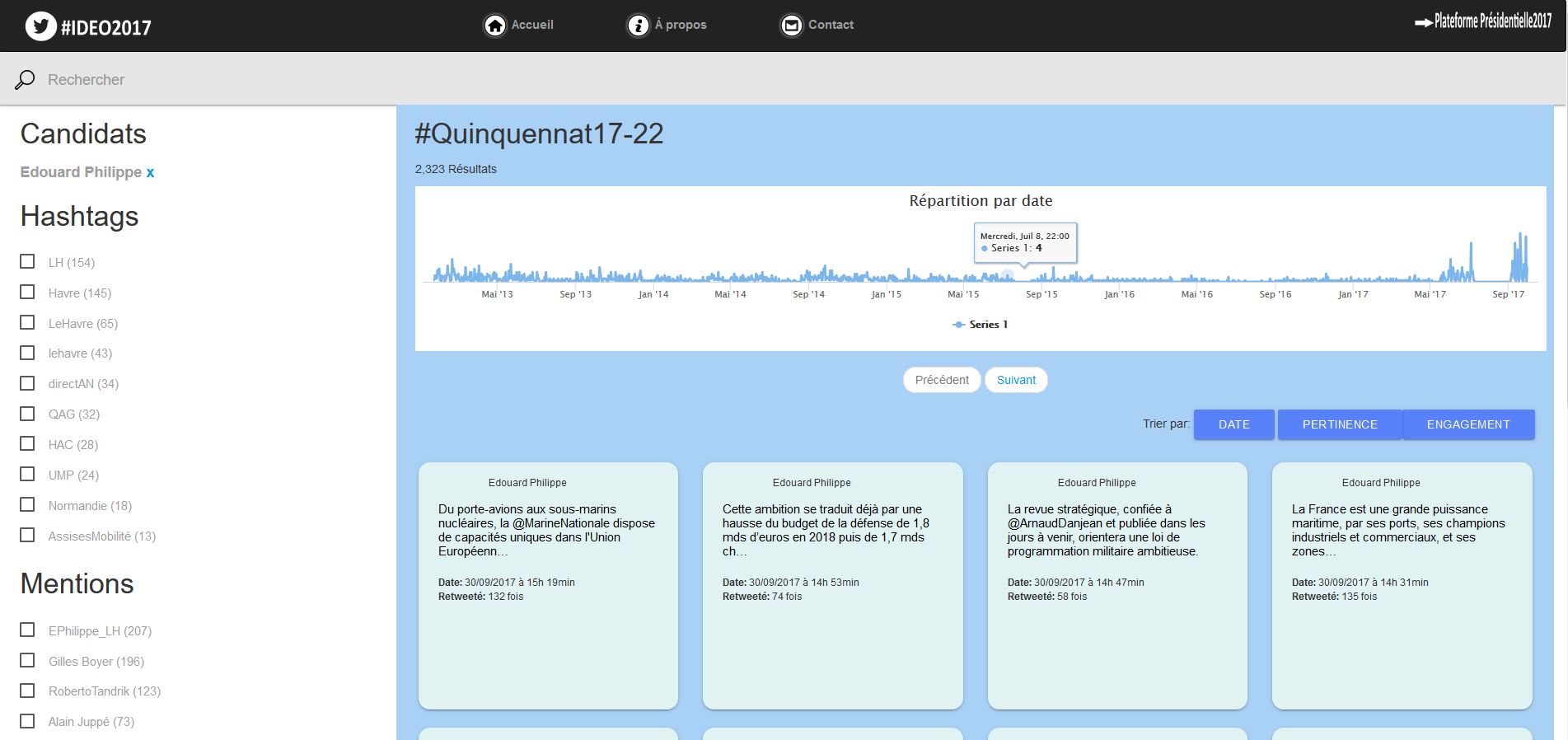
#Idéo2017 poursuit son analyse sur le quinquennat. Ci-dessus, l'affichage des tweets sur une timeline à travers l'interface Kibana. (agrandir l'image)
Il fallait aussi pouvoir supporter un nombre important de requêtes simultanées en garantissant des temps de réponses très courts. Elasticsearch représente l’information sous la forme d’un index clusterisé sur plusieurs nœuds qui répartit la charge des requêtes entre les nœuds et réalise une sauvegarde automatique et répliquée des données, détaille Julien Longhi dans un billet. L'interface de recherche est basée sur le framework AngularJS avec un contrôle d'accès restreignant les permissions à Elasticsearch en lecture seule pour le public. Le projet est hébergé par Etis, unité de recherche commune au CNRS, à l’Ensea Cergy et à l’Université de Cergy-Pontoise.
Une plateforme à décliner sur d'autres secteurs
Au-delà de l’analyse du discours politique, la structure ainsi créée avec Elasticsearch autour de l’analyse de corpus de tweets peut être déclinée pour de nombreuses autres applications de veille, nous a expliqué le directeur de recherche en linguistique. « L’idée, c’est de le décliner à la carte en fonction des besoins de partenaires », nous a exposé Julien Longhi. Dans des domaines très différents, tels que la culture (musées, peinture, architecture…) ou l’industrie aéronautique, la structure ainsi créée peut être mise à profit pour bâtir un outil de veille permettant de suivre les grandes tendances, cite-t-il en exemple. Pour travailler avec l’industrie, des passerelles peuvent se faire sous forme de contrats de recherche, rappelle-t-il.
« Lorsque l’on voit un fil Twitter, c’est très compliqué pour un utilisateur de tirer parti de tout cela. Il y a une déperdition, un surcroît d’information. L’une des déclinaisons possibles est de pouvoir agréger des sujets de société, par exemple pour une agence de presse. Cela permet d’avoir une visibilité, d’être plus objectif », expose encore Julien Longhi, qui donne également des cours de data journalisme. « Sur les tweets, nous maîtrisons le format, mais on peut aussi imaginer des textes qui sont sur les blogs avec des API qui permettent de récupérer des sites Word Press ».
Commentaire