
")
Si Nvidia domine aujourd’hui le marché des accélérateurs GPU, ce n’est pas seulement grâce au développement de puces toujours plus performantes. La firme de Santa Clara a compris bien avant ses principaux concurrents (ATI, puis AMD suite au rachat de cette entreprise canadienne à l’origine des GPU Radeon et bien sûr Intel) que le marché du calcul intensif (HPC) nécessitait un écosystème logiciel dédié. A la fois plateforme de calcul parallèle généraliste et modèle de programmation, le kit de développement Cuda (Compute Unified Device Architecture) de Nvidia a été lancé en 2007 - pour ses GeForce 8 - afin d’aider les développeurs à porter leurs applications sur ses GPU pour accélérer certains traitements (compression, finance, simulation de fluides, modélisation du climat, cassage de codes ou encore calculs de structures). Le kit de développement a connu de nombreuses évolutions pour accompagner la sortie des architectures GPU et améliorer sa prise en main, réputée difficile. En complément, Nvidia n’a pas perdu de temps pour adopter la technologie Tensor développée en 2015 par Google pour ses accélérateurs TPU. Nvidia a introduit ses premières unités Tensor en mai 2017 avec la microarchitecture GPU Volta utilisée par les produits Tesla V100.
Si AMD a répondu avec retard à Cuda en lançant Radeon Stream, Intel dégainé Larrabee et le Khronos Group fédéré les initiatives autour d’OpenCL (lancé en 2009), la mainmise de Nvidia n’est toujours pas remise en cause sur un marché dopé par les besoins en IA (générative ou discriminative). Cuda a amélioré et élargi sa portée au fil des ans, plus ou moins en phase avec ses lancements de GPU. En utilisant plusieurs accélérateurs P100, il était possible de réaliser des améliorations de performances jusqu'à 50 fois supérieures à celles des processeurs. Le V100 était encore 3 fois plus rapide pour certaines charges (donc jusqu'à 150 fois que les processeurs), et l'A100 encore 2 fois plus rapide (jusqu'à 300 fois que les processeurs). La génération précédente de GPU pour serveur, le K80, offrait des performances 5 à 12 fois supérieures à celles des processeurs. Aujourd’hui près de 4 millions de développeurs dans le monde s'appuient sur la plate-forme Cuda pour créer des applications (avec ou sans IA) exploitant les performances des GPU.
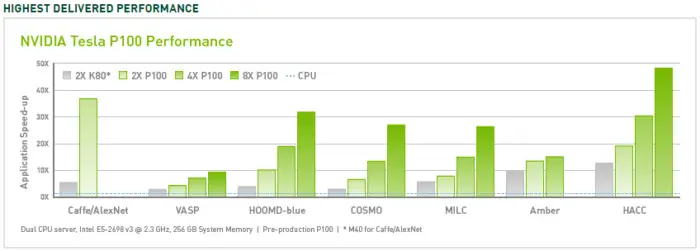
Les progrès des accélérateurs GPU de Nvidia ont été constant ces dernières années. (Crédit Nvidia)
Des fournisseurs regroupés dans l'UXL Foundation
Une coalition de fournisseurs (Arm, Google, Imagination Technologies, Intel, Qualcomm ou encore Samsung) regroupés au sein de la UXL Foundation (une émanation de la puissante Linux Foundation) entend toutefois remettre en cause cette domination en s'attaquant au kit de développement Cuda, qui maintient les développeurs dans l’écosystème GPU de Nvidia. À partir de OneAPI, une technologie développée par Intel, la Fondation UXL prévoit de créer une suite de logiciels et d'outils capables d'alimenter plusieurs types d’accélérateurs. "Nous avons un concurrent open source à la plateforme Cuda de Nvidia pour exploiter les accélérateurs tels que les GPU", avait posté sur X Kelsey Hightower, ancien ingénieur de Google à l’occasion du lancement de la Fondation UXL en septembre dernier. Le projet open source vise à faire fonctionner des applications HPC sur n’importe quel serveur, quels que soient le CPU et le GPU qui l’alimentent.
La fonction SYCLomatic de OneAPI assure la conversion des logiciels (IA ou autres) écrits pour Cuda en code SYCL capable de fonctionner sur les accélérateurs d'autres fournisseurs avec une légére perte en performances. Vinesh Sukumar, responsable de l'IA et de l'apprentissage automatique chez Qualcomm, a déclaré à Reuters que "nous montrons aux développeurs comment migrer à partir d'une plateforme Nvidia". Si le comité de pilotage technique de la Fondation UXL compte affiner les spécifications de son modèle de programmation pour l'IA au cours du premier semestre 2024, OneAPI n’est pas la seule initiative contre Cuda : des start-ups comme Cerebras, Groq ou SambaNova ont développé leur propre ASIC dédié à l’IA avec le logiciel adéquate. Installée depuis plus de quinze ans avec un écosystème particulièrement fourni, la plateforme Cuda ne sera pas facile à déboulonner, même si Nvidia semble s’essouffler comme le montre la sortie de ses récents GPU B200 reposant sur l’architecture Blackwell.
Commentaire