")
Pour gérer ses big data et l’apprentissage machine, Linkedin s’appuie sur Hadoop. Mais d’année en année, le réseau social professionnel a dû doubler la taille de ses clusters pour faire face à la croissance exponentielle du volume de données à traiter. Son plus grand cluster avoisine maintenant les 10 000 noeuds et le passage à l’échelle d’Hadoop Yarn était devenu l’une de tâches les plus difficiles à gérer sur son infrastructure, explique le réseau social dans un billet. Une équipe d'ingénieurs IT de Linkedin y expose en détail le contexte des ralentissements qu’elle a observés à l’approche des 10 000 noeuds, ainsi que les solutions qui ont été développées pour tenter d’y remédier. Par ailleurs, l’un des éléments importants pour évaluer la scalability de Yarn est la capacité à prévoir les performances du gestionnaire de ressources. Pour surveiller de manière proactive les dégradations de performances susceptibles de survenir, Linkedin a donc développé un outil baptisé DynoYarn qui, assure-t-il dans son billet, prévoit de manière fiable les performances de clusters Yarn de taille arbitraire. Cet outil vient d'être mis en open source.
Tel que décrit sur GitHub, DynoYarn fournit un framework pour faire monter en puissance un cluster Yarn à la demande et exécuter des charges de travail Yarn simulées pour tester le passage à l’échelle. L’outil « peut simuler la performance d’un cluster Yarn de 10 000 noeuds sur un cluster Hadoop de 100 noeuds », est-il précisé. Le framework a été créé, d’une part pour évaluer les mises à jour des fonctionnalités Yarn et des versions d’Hadoop sur les performances du gestionnaire de ressources, d’autre part, pour prévoir les performances du gestionnaire de ressources sur les grands clusters Yarn.
Similaire à Dynamometer
Dans leur billet, les ingénieurs de Linkedin expliquent que DynoYarn est similaire à Dynamometer, l’outil de test écrit par l’équipe technique du réseau social pour évaluer les performances futures de NameNode dans HDFS. DynoYarn comporte deux composantes : un driver pour faire monter un cluster Yarn simulé et une charge de travail à rejouer sur ce cluster. Les deux sont mis en oeuvre sous la forme d’applications Yarn, il faut donc un cluster Hadoop fonctionnel pour exécuter la simulation. « En fait, nous exécutons un cluster Yarn au sein d’un cluster Yarn mais avec des contraintes de ressources moindres », indique le billet. Le driver et la charge de travail peuvent être configurés pour monter un cluster et rejouer des charges de tailles arbitraires, ce qui signifie que DynoYarn peut simuler une grande variété de scénarios: on peut rejouer des problèmes de performances rencontrés en production ou prédire les performances du gestionnaire de ressources sur de futures charges de travail et clusters.
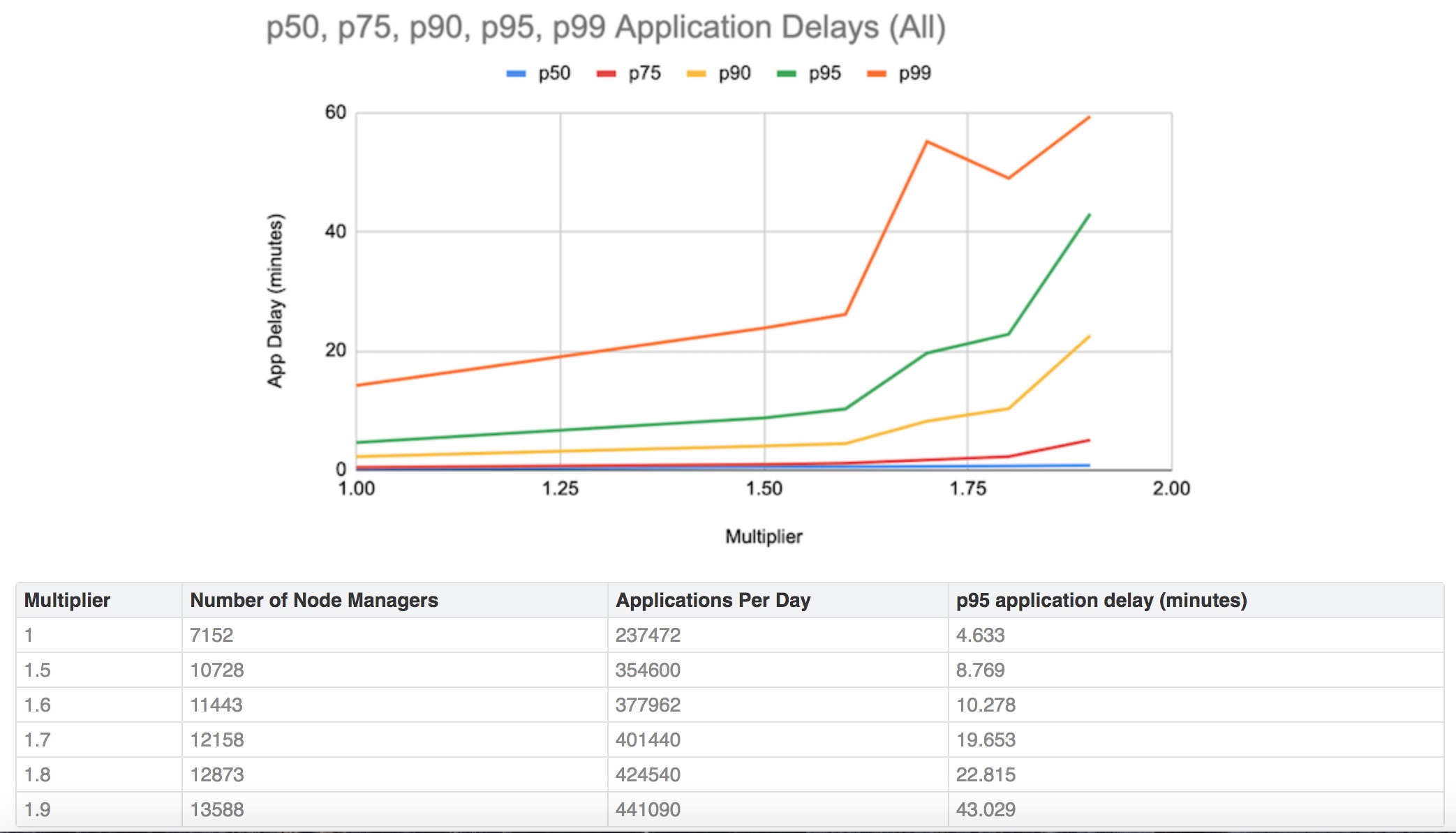
DynoYarn permet de simuler les charges de travail projetées pour évaluer les changements induits sur les performances du gestionnaire de ressources au fur et à mesure d’un passage à l’échelle incrémental des clusters de production.
Au-delà de ces prévisions sur la montée en puissance des clusters, Linkedin utilise DynoYarn pour évaluer l’impact d’importantes fonctionnalités avant de les mettre en production et pour assurer la parité des performances lors de la mise à niveau des clusters vers les versions supérieures. « Par exemple, nous avons utilisé DynoYarn pour comparer les performances du gestionnaire de ressources lors de la mise à niveau de nos clusters de la version 2.7 de Hadoop à la version 2.10 », indique l'équipe d'ingénieurs IT en ajoutant l’avoir aussi utilisé pour faire de l’A/B testing sur l’optimisation du gestionnaire de ressources, ainsi que relaté dans le billet. Compte-tenu de l’intérêt présenté par l’outil pour aider son IT à établir sa feuille de route sur Yarn et déployer les mises à jour, le réseau social l'a donc ouvert au bénéfice de la communauté Yarn.
En pleine migration vers Azure
Dans son billet, l’équipe technique de Linkedin décrit aussi Robin, un service interne qui permet de faire passer les clusters à l’échelle horizontalement au-delà de 10 000 noeuds. Celui-ci se présente comme un équilibreur de charges qui distribue dynamiquement les applications Yarn pour multiplier les clusters Hadoop. Au plus haut niveau, Robin fournit une simple API Rest qui retourne un cluster Yarn pour une tâche donnée.
Racheté par Microsoft en 2016, Linkedin est actuellement en pleine migration vers Azure. Le réseau social étudie en particulier la meilleure façon de gérer et passer à l’échelle son cluster Yarn dans le cloud. Là encore, il y a un certain nombre de défis à relever pour faire passer les 10 000 noeuds ou plus du cluster Hadoop Yarn on-premise vers le cloud, dont la prise en compte des « voisins bruyants », une planification tenant compte de l’utilisation des disques pour réduire les coûts et le job caching.
Commentaire