")
La start-up new-yorkaise Materialize a dévoilé lundi un service de base de données distribuée pour gérer les flux de données. Pour l'instant, elle ne propose ce logiciel qu'à ses clients existants. La société a lancé la version initiale de son logiciel éponyme il y a deux ans sous la forme d'un binaire unique conçu pour récupérer des données à partir de Kafka, en permettant aux utilisateurs d'utiliser le langage SQL standard pour interroger et joindre les flux de données.
Aujourd'hui, la société - qui a été fondée en 2019 et a levé environ 100 millions de dollars auprès d'investisseurs tels que Lightspeed, Kleiner Perkins et Redpoint - affirme avoir incorporé une couche de stockage évolutive dans le logiciel et le propose sur un modèle de base de données en tant que service (DBaaS). Le logiciel remanié n'est donc disponible que pour ses clients, aucune date n'a été annoncée pour sa disponibilité générale. Une base de données distribuée est une database qui s'exécute sur plusieurs clusters dans plusieurs centres de données, mais qui agit comme une seule base de données logique.
Qu'est-ce qu'une base de données en continu ?
Pour Materialize, une base de données de gestion de flux (streaming database) capture en continu des données provenant de différentes sources et exécute des calculs pour répondre à différentes requêtes. L'idée est que la start-up propose aux utilisateurs de la connecter facilement à un ou plusieurs flux de données, a expliqué Carl Olofson, vice-président recherche chez IDC. « La base de données en continu est assez mal nommée puisque la base de données elle-même n'est pas en continu, mais elle s'exécute assez rapidement pour être capable de capturer les données en continu dès qu'elles arrivent », indique Carl Olofson.
Cette annonce intervient à un moment où les entreprises cherchent à analyser de plus en plus de données dans le but d'élaborer une stratégie pour devenir résilientes face aux vents contraires économiques et à l'incertitude géopolitique, ce qui entraîne une augmentation des requêtes de traitement analytique en ligne (OLAP). Ce sont ces dernières fonctions que la base de données de la start-up prétend prendre en charge à un coût moindre que les bases de données offrant des systèmes de traitement par lots. La réduction des coûts est rendue possible par deux frameworks de calcul au sein de la database, décrit Seth Wiesman, directeur de l'ingénierie de support chez Materialize. Le premier, Timely DataFlow, gère et exécute des calculs en parallèle sur des flux de données. Le deuxième, Differential DataFlow, qui fonctionne également en mode parallèle, est conçu pour traiter et répondre efficacement aux changements sur de grands volumes de données.
Des avantages en termes de coût
Habituellement, afin de générer une réponse à une requête, un système de traitement par lots parcourt toutes les données qui ont été saisies dans un système, ce qui le rend coûteux en termes de calcul et fait que la requête n'est pas un processus en temps réel.
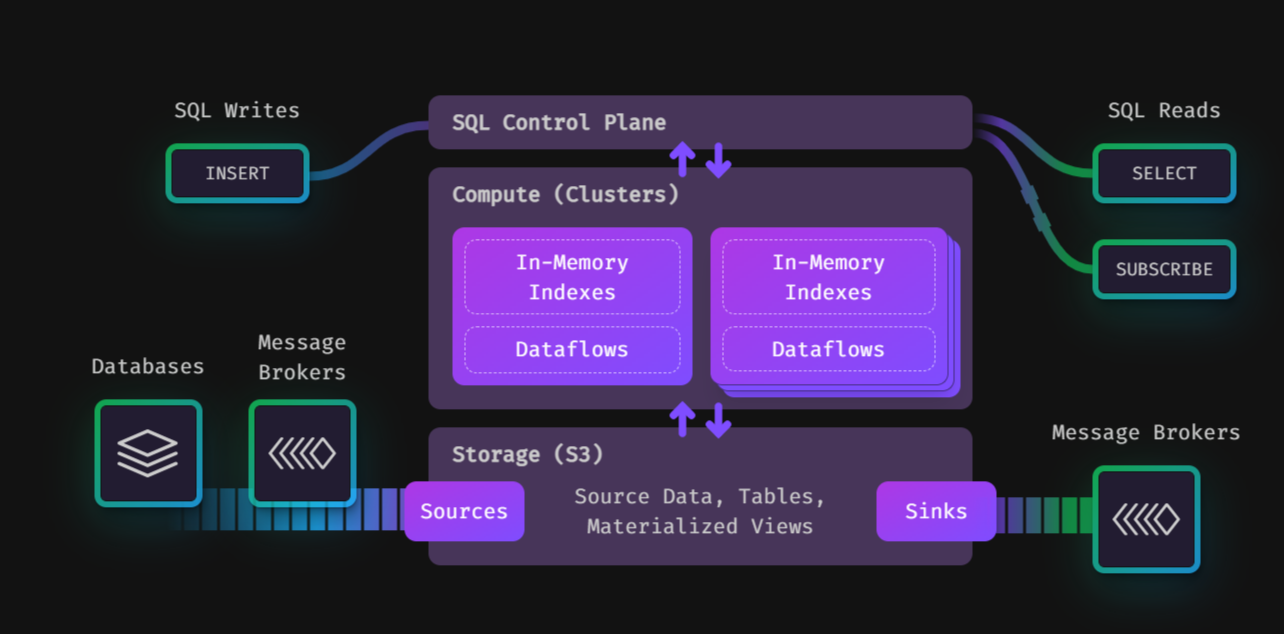
Materialize affirme que son interface, compatible avec PostgreSQL, aide les utilisateurs à tirer parti des outils de requête qu'ils utilisent déjà. (Crédit : Materialize)
En revanche, la société, grâce à ses frameworks de calcul, peut exécuter une requête (ou une « vue » dans le jargon des bases de données), la mettre en cache sous forme de vues matérialisées, détecter toute modification incrémentielle de l'ensemble de données de l'utilisateur (plutôt que de réanalyser l'ensemble des données) et mettre à jour le résultat de la requête, explique Seth Wiesman.
Une disponibilité quasi immédiate
Au fur et à mesure que les utilisateurs créent des tables, des sources et des vues matérialisées et y introduisent des données, la version DBaaS de Materialize enregistre et maintient ces données, et rend les instantanés et les flux de mise à jour immédiatement disponibles pour tous les ordinateurs abonnés au service, selon la société.
« Les utilisateurs de l'entreprise peuvent soit interroger les résultats pour des lectures rapides et à haute fréquence, soit s'abonner aux changements pour des architectures purement événementielles », ajoute Seth Wiesman. Le service de base de données distribuée géré, dans sa version actuelle, utilise le service de stockage S3 d'Amazon Web Services, a indiqué la société, ajoutant que la prise en charge du store d'objets natifs par les principaux fournisseurs de cloud est prévue prochainement.
Prise en charge de PostgreSQL
Selon la société, l'interface de sa solution est compatible avec PostgreSQL et offre un support ANSI SQL complet. Contrairement aux systèmes de données génériques qui nécessitent une programmation pour la capture des données, la DBaaS de Materialize est dotée d'un moteur de flux de données qui ne nécessite qu'une programmation légère, voire aucune programmation, selon la société. Les utilisateurs de l'entreprise peuvent modéliser une requête SQL comme un flux de données capable de recevoir un flux de capture de données de changement, de lui appliquer un ensemble de transformations, puis d'afficher les résultats finaux, ajoute-t-elle.
Selon M. Olofson, Redis, le système de données le plus couramment utilisé pour la capture de données en continu, impose une lourde charge de programmation à l'utilisateur de l'entreprise, car il n'est livré avec aucun schéma ou langage de requête. « Il y a deux produits à considérer comme des concurrents potentiels : SingleStore qui est une mémoire optimisée pour les bases de données relationnelles utilisées, entre autres, pour la capture de données en continu [NDLR : cf notre entretien de Raj Verma, CEO de SingleStore) et CockroachDB », précise-t-il, ajoutant que Hazelcast [cf notre rencontre avec Hazelcast en mars 2022] peut également être considéré comme un rival car il utilise une plateforme de partage de données en mémoire qui a ajouté des capacités de requête à sa liste de fonctionnalités.
Materialize a déclaré suivre le modèle de tarification de Snowflake : les entreprises achètent des crédits pour payer le logiciel sur la base de son utilisation. Le prix des crédits est basé sur la localisation des utilisateurs, précise Seth Wiesman.
Commentaire