Flux RSS
SGBD
377 documents trouvés, affichage des résultats 61 à 70.
| < Les 10 documents précédents | Les 10 documents suivants > |
(29/06/2011 12:16:35)
Oracle lance un programme Exastack pour attirer les éditeurs de logiciels
La migration du traitement des données vers des systèmes spécialisés à haute technicité va à l'encontre de la tendance actuelle plutôt orientée vers les fermes de serveurs. Mais Oracle soutient que son Exadata et son serveur d'application Exalogic contribueront réellement à diminuer les coûts opérationnels globaux des vendeurs de logiciels indépendants (ISV). « Exastack est vraiment la plateforme du futur pour les ISV, » a déclaré Judson Althoff, vice-président senior Worldwide Alliances & Channels, au cours d'un webcast.
Le programme Exastack comporte deux niveaux, Ready et Optimized. Dans le premier, les partenaires pourront appliquer un label indiquant que leurs applications supportent Exalogic, Exadata et la pile logicielle qui tourne sur ces matériels, dont la base de données Oracle, WebLogic Application Server, et les systèmes d'exploitation Linux et Solaris. Les partenaires Optimized du programme Exastack auront accès aux ressources techniques et aux laboratoires spécialisés qu'Oracle a mis en place dans le monde entier, ce qui leur permettra notamment d'adapter plus finement leurs applications Exadata et Exalogic.
« Avant de les diriger vers un laboratoire, Oracle travaillera avec les partenaires pour établir un système d'évaluation des compétences, » a indiqué l'entreprise pendant le webcast. Ils iront ensuite passer une semaine ou deux dans notre laboratoire avec les architectes et les ingénieurs d'Oracle afin de tester les performances en situations réelles et de les confronter aux objectifs établis préalablement. « Le programme Ready est ouvert dès maintenant. Le lancement du programme Optimized est prévu pour plus tard cette année, » a précisé Oracle.
Des annonces attendues à OpenWorld
Certains vendeurs de logiciels indépendants se préparent déjà pour le programme Optimized d'Exastack et la firme de Redwood prévoit de faire quelques annonces à ce sujet lors de la conférence OpenWorld qui aura lieu plus tard cette année, comme l'a déclaré le vice-président. « Aujourd'hui, on compte un millier de systèmes Exadata en opération dans le monde. Oracle prévoit de tripler ce nombre cette année, » a déclaré, la semaine dernière, le vice-président d'Oracle, Mark Hurd, lors de la présentation des résultats financiers du quatrième trimestre. La société californienne n'a pas communiqué de chiffres précis sur les ventes d'Exalogic, mais celles-ci auraient bénéficié d'une accélération encore plus importante qu'Exadata, selon Mark Hurd.
Lors de son intervention, Judson Althoff a également évoqué les changements entrepris par Oracle concernant son réseau de partenaires pour l'exercice fiscal qui a débuté le 1er juin. Celui-ci a notamment fait allusion à certains « défis » opérationnels auxquels devaient faire face Oracle et ses partenaires depuis que l'entreprise a intégré Sun Microsystems. Oracle a bouclé l'acquisition de Sun en janvier 2010, une date qui a marqué également son entrée dans le secteur du hardware. « Nous réalisons que nous avons été en position difficile pour l'exercice 2011, » a déclaré Judson Althoff. « Notre objectif est d'être les meilleurs dans notre secteur. » Déjà, « l'automatisation des commandes a subi des améliorations importantes et d'autres changements sont en cours, comme la mise en place d'un panier unique pour les achats de logiciels et de matériel, » a ajouté le vice-président. « Oracle met également en route un nouveau programme d'incitation financière pour le réseau de partenaires dans le terme fiscal actuel, » a déclaré Judson Althoff.
USI 2011 : des technologies et des hommes
Placée sous le signe de l'informatique qui transforme nos sociétés, la quatrième édition de l'USI 2011 aligne en deux jours une cinquantaine de présentations, articulées autour de quatre thématiques : Autrement, Techniquement, Humainement, Prochainement.
Autrement, car la première journée propose une plongée au sein de problématiques qui montent en puissance. Elle débute notamment par deux sessions consacrées à DevOps, mouvement qui vise à améliorer la qualité des développements. Les sessions techniques de l'après-midi abordent des sujets très diversifiés : la fin des bases de données relationnelles, la rencontre d'OLAP et du CEP, les nouveaux middlewares orientés message (tels que RabbitMQ), les techniques d'accélération GPU, la prolifération des identités numériques ou, encore, les aspects juridiques du cloud.
Les impacts sociétaux de la IT
La deuxième matinée de l'USI 2011 est axée sur les facteurs humains et c'est le philosophe Michel Serres qui l'ouvrira (déjà présent en 2008 sur la première édition de l'USI). A sa suite, les intervenants aborderont les « transitions agiles », d'abord dans le domaine du développement (déployer l'agile à large échelle), mais aussi en explorant le concept du lean start-up, de l'offshore « qui fonctionne » et du modèle métier. Les impacts sociétaux de l'IT seront balisés avec, par exemple, une analyse du consultant en RH Benjamin Chaminade sur les opportunités de la diversité culturelle pour l'entreprise. En fin de matinée, la parole reviendra de nouveau à un philosophe, André Comte-Sponville, avec un exposé portant sur le sens du travail.
Enfin, la dernière séquence de sessions projettera les participants vers demain et les mises en oeuvre en devenir des technologies numériques : les tendances web vues de la Silicon Valley, les interfaces cérébrales, l'évolution de l'informatique dans une perspective cosmogénétique (par Jean-Michel Truong) ou l'interconnexion des objets (présentée par rafi Haladjian, le fondateur de Violet et créateur du Nabaztag).
Organisée par Octo Technology, l'USI 2011 se tiendra le mardi 28 et mercredi 29 juin à Paris, au Pavillon d'Armenonville (Bois de Boulogne, 16e). Les conférences seront également retransmises en streaming vidéo sur www.universite-du-si.com le mardi 28 juin à partir de 8 h 40
Illustration : Les philosophes André Comte-Sponville (à gauche) et Michel Serres (à droite) interviendront sur l'USI 2011. (...)
Boston IT 2011 : NimbusDB, une base de données élastique dans le cloud
Fondée par Barry Morris (CEO, en illustration principale) et Jim Starkey (CTO), une légende dans le petit monde des bases de données, NimbusDB emploie aujourd'hui un peu moins de 20 personnes essentiellement des ingénieurs. Ancien architecte logiciel chez MySQL et créateur d'InterBase, Jim Starkey, qui vit aujourd'hui à Seattle sur un bateau, est à l'origine de cette base de données distribuée (peer to peer), déployable localement et sur le cloud. Les déploiements en ligne qui permettent une allocation dynamique des ressources et une facturation à l'usage sont particulièrement bien adaptés aux applications web, notamment les industries qui connaissent des pics réguliers et temporaires. Mais jusqu'à présent, le provisionnement dynamique ne s'appliquait qu'avec difficultés aux bases de données notamment pour répondre au besoin grandissant des utilisateurs mobiles dans les entreprises.

Jim Starkey, un des gourous de la base de données
Avant de fonder NimbusDB, Jim Starkey avait commencé à développer il y a quelques années une base de données élastique, basée sur SQL, mais qui répondait aux concepts d'ACID (Atomicity, Consistency, Isolation and Durability) pour assurer l'intégrité des opérations. Avec NimbusDB, une nouvelle terminologie basée sur la musicologie fait son apparition pour expliquer la technologie utilisée nous indique Barry White. Ainsi, un « Chorus » désigne un groupe de noeuds sur lesquels repose la base de données qui est composée d'objets baptisés « Atoms ». Et si deux utilisateurs veulent modifier au même moment un bloc (un Atom dans le jargon de Nimbus), un superviseur automatique et temporaire baptisé « Chairman » gère les priorités pour éviter les problèmes de synchronisation. Les noeuds, en local ou en ligne, peuvent être ajoutés ou soustraits du système en fonction des besoins.
Redondance et performance
«Imaginez que vous commencez à travailler à Boston avec une seconde machine redondante à Los Angeles qui pourra offrir une capacité de traitement supplémentaire en cas de besoins », nous a expliqué Barry White. « Imaginez que votre base de données dans votre datacenter avec une autre partie dans un cloud public, et des «cloudbursts » pour supporter des pics de charges dans d'autres clouds. » Et pour trouver les meilleurs prix en ligne pour booster temporairement la base de données, NimbusDB propose une fonction baptisée Connection Brokers. L'architecture de NimbusDB ne repose sur aucun matériel en particulier puisque tout est dans le cloud. Le soft s'installe simplement sur un serveur pour assurer ensuite un pont vers le cloud. Les paramétrages sont réduits au minimum, pour aller plus vite, il suffit de rajouter des machines, précise Barry Morris. 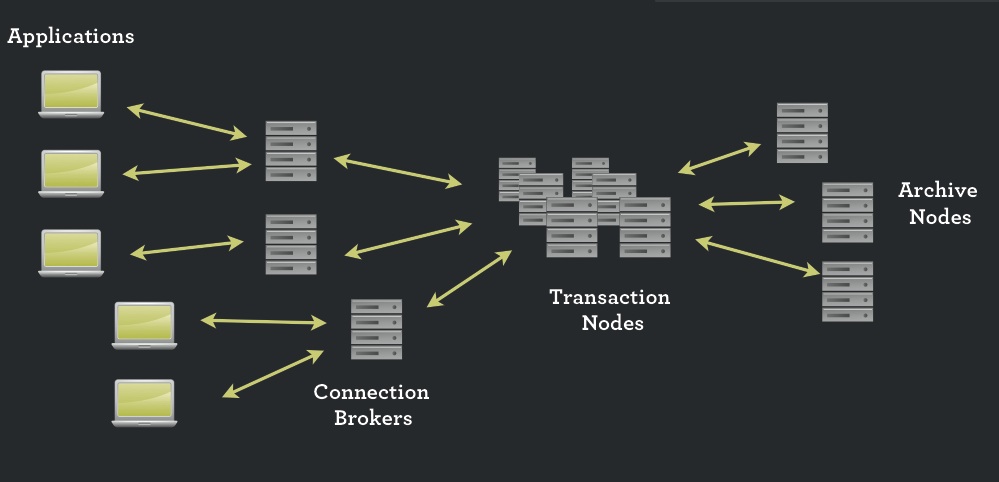
Architecture de la base de données NimbusDB, cliquez pour agrandir l'image
Si la solution de NimbusDB n'est pas encore vendue, elle est déjà testée intensivement chez plusieurs clients. Le produit est presque complet et sa commercialisation ne saurait tarder, complète le dirigeant. Une version gratuite, et parfaitement fonctionnelle est d'ailleurs disponible en téléchargement. Baptisée Duet, elle se limite à deux machines, une pour accueillir le module transaction, l'autre pour héberger les archives. La version Quartet (quatre machines donc serveurs ou VM) sera commercialisée quelques milliers de dollars. La base utilisée est x86 mais un portage vers Sparc ou Itanium est parfaitement envisageable, assure Barry Morris, qui estime ce marché insignifiant. Et pourquoi pas sur iPad conclut-il en forme de boutade.
Les technologies de l'IBM Watson appliquées au big data
Mi-février, le superordinateur Watson conçu par IBM a battu deux champions au jeu télévisé Jeopardy, un quizz de culture générale où il s'agit de trouver une question à partir d'une réponse. Pour y parvenir, Watson a, entre autres, absorbé une quantité phénoménale d'informations disponibles sur le web et d'une qualité toute relative. Des données qui ont nourri ses multiples algorithmes sollicités à chaque réponse pour aboutir rapidement à une question associée à un indice de confiance. Une partie du problème auquel se sont attelés les 25 informaticiens d'IBM qui ont développé Watson est similaire à celui que rencontrent les Google et Facebook lorsqu'il s'agit de scanner d'énormes quantités de données non-structurées pour répondre rapidement à une requête. Un problème, ou plutôt une solution, dont ils ont d'ailleurs fait un modèle d'affaires avec le succès que l'on connaît.
Bien loin des laboratoires de recherche, des plateaux télé et des géants d'Internet, les entreprises, grandes et petites, font face à des défis analogues. D'un côté, elles sont de plus en plus conscientes que l'analyse des données et les découvertes (insights) qui en résultent sont essentielles au pilotage informé de leurs opérations et à leur compétitivité, d'où l'essor des projets de business intelligence. De l'autre, elles croulent sous une masse indigeste d'informations de toutes sortes et de toute provenance le plus souvent négligées et considérées comme un problème. Disposer d'un Watson est sans doute un rêve que caressent beaucoup de leurs décideurs.
Selon une étude IDC commandée par EMC, l'univers digital - la somme de toutes les données numériques - a crû de 1,2 million de pétaoctets en 2010 et pourrait atteindre 35 millions de pétaoctets à l'horizon 2020. L'écrasante majorité de cette masse est constituée de textes et de fichiers audio et vidéo. Donc de données sans structure, contrairement à celles reposant dans une base de données classique. Cette déferlante concerne aussi les entreprises, qui sont sans cesse plus nombreuses à collecter des informations sur les réseaux sociaux, les outils collaboratifs et les centres d'appel. A cela s'ajoute de nouvelles données mises à disposition par des organismes publics ou générées par les senseurs dont sont équipés les smartphones.
Par leur énorme volume de l'ordre de plusieurs téraoctets, par leur qualité incertaine et par leur caractère fugace, ces big data ne ressemblent en rien aux données relationnelles qui alimentent les solutions de business intelligence usuelles (voir le graphique). Leur exploitation diffère tout aussi fondamentalement. Alors que la BI fournit des réponses exactes à des questions précises connues d'avance, l'exploration expérimentale des big data livre des réponses probables à des questions ad-hoc et suggère de nouveaux questionnements. Pour employer la métaphore de Tom DeGarmo, responsable des technologies chez PricewaterhouseCoopers: «Au lieu de trouver une aiguille dans une botte de foin, ces techniques permettent de chercher d'autres bottes de foin».
[[page]]
Il y a quelques années encore, ce type d'analyse à grande échelle était surtout pratiqué par des instituts de recherche scientifique (physique, astronomie, bioinformatique, finance), souvent à l'aide de superordinateurs extrêmement onéreux. Faute visibilité quant à leur potentiel, faute de compétences statistiques et faute de moyens technologiques et financiers, les entreprises ne s'y sont guère intéressées. Sous l'effet de la prolifération de données non-structurées (typiquement 80% des données d'une entreprise), le domaine connaît un intérêt nouveau dans des sociétés qui se demandent comment exploiter ces données brutes qui sommeillent ou qui n'ont pas (encore) fait l'objet de formalisation par les architectes. A l'affût de nouveaux besoins, plusieurs grands fournisseurs IT ont d'ailleurs acquis récemment des sociétés spécialisées dans le domaine du big data: EMC avec Greenplum, IBM avec Netezza, HP avec Vertica ou encore Teradata avec Aster Data Systems début mars. Un mouvement également suivi par plusieurs éditeurs de business intelligence qui élargissent leur offre à l'analyse de larges volumes de données. Le dénominateur commun de la plupart de ces solutions est leur utilisation du projet open source Hadoop dérivé des développements de Google.
Au début des années 2000, face à la croissance folle des contenus internet, Google a en effet dû développer sa propre solution pour être en mesure de continuer à les indexer en des temps raisonnables. Les ingénieurs de la société ont développé un système de stockage robuste et extensible (GFS) et un système de traitement des données répartissant les tâches sur un grand nombre de serveurs fonctionnant en parallèle et à même de synthétiser leurs résultats (MapReduce). Ainsi, au lieu de s'appuyer sur des algorithmes complexes et des ordinateurs surpuissants, la solution de Google utilise des batteries de serveurs standards, qui peuvent être ajoutés ou supprimés, auxquels sont confiées des tâches relativement simples. Le projet Hadoop est en fait une implémentation open source de MapReduce gérée par la fondation Apache, à laquelle sont venus se greffer d'autres composantes destinées aux big data, comme un système de fichiers distribué (HDFS) ou une base de données (HBase). Yahoo! est l'un des pionniers en la matière et coopère avec Facebook, dont le cluster Hadoop serait actuellement le plus gros du monde (voir le lien à droite).
La robustesse, le coût et la flexibilité de cette technologie séduisent également des sociétés hors du monde internet. Le New York Times a ainsi utilisé Hadoop pour générer les PDF de 11 millions d'articles publiés entre 1851 et 1922, et l'emploie désormais pour l'analyse de texte et le web mining. La chaîne de librairies Barnes & Noble l'utilise pour comprendre les comportements d'achats de ses clients sur ses divers canaux de distribution. Disney teste la technologie avec des objectifs similaires en s'appuyant sur des ressources dans le cloud et sur des serveurs inutilisés en raison de ses efforts de virtualisation. McAfee y fait par exemple appel pour détecter des corrélations parmi les spams. Pour simplifier les déploiements, ces sociétés et les autres utilisateurs précoces du big datausent fréquemment d'outils commerciaux basés sur Hadoop qui offrent une large palette de fonctions additionnelles.
[[page]]
Pour Abdel Labbi, responsable de la recherche en analyse de données au centre de recherche d'IBM à Zurich, ces développements technologiques conduisent à une convergence entre les données transactionnelles en mouvement, typiques des acteurs du web, et les données au repos des sociétés traditionnelles». Exemple de cette convergence, l'analyse en temps réel des données récoltées sur les points de vente pour dresser des profils de clients. «Ce n'est plus la requête qui va chercher des données, mais les données qui découvrent des phénomènes», estime le chercheur. Le lien avec Watson - l'ordinateur de Jeopardy - apparaît d'emblée et ouvre de nouvelles perspectives.
Watson : vers une analyse intelligente des données
Pourtant, de prime abord, le superordinateur d'IBM ne représente pas une innovation majeure mais plutôt une manière innovante de combiner des technologies existantes. Au niveau hardware, Watson est «massivement redondant» pour reprendre les termes du responsable de sa conception David Ferucci, avec une kyrielle de transistors économiques. Idem pour les algorithmes qui sont nombreux mais relativement simples. Quatre points cependant en font une machine assez prodigieuse pour disputer la victoire à des humains. Tout d'abord, sa capacité à exécuter simultanément de multiples algorithmes, donc à suivre plusieurs pistes en parallèle, à une très grande vitesse. Ensuite, sa faculté d'apprentissage qui lui permet avec le temps d'évaluer quelles ressources et quels algorithmes donnent les meilleurs résultats. Troisièmement, son habilité à décider entre plusieurs réponses et à leur attribuer un indice de confiance. Enfin, sa compréhension du langage naturel et donc son habileté à résoudre des ambiguïtés.
La combinaison de ces diverses facultés pourrait avoir dans le futur un impact considérable sur l'analyse de données en entreprise. La compréhension du langage permettrait par exemple d'étendre l'analyse aux requêtes orales des clients pour y répondre de manière automatisée. Associée aux recherches en analyse sémantique et des sentiments, ce type d'intelligence pourrait répondre précisément à une question ad-hoc, au lieu de simplement pointer sur une source dans laquelle se trouve la réponse comme le font des moteurs de recherche. Elles pourraient également résoudre le problème des données non-structurées en faisant émerger une structure sur la base de corrélations. Comme le dit Abdel Labbi, on pourrait déboucher sur des systèmes où «la donnée trouve la donnée».
IBM dote les villes d'un outil de gouvernance IT
Karen Parrish, vice-présidente d'IBM sur l'activité solutions industrielles a annoncé « cette plateforme qui doit permettre aux municipalités de faire des économies et d'avoir une réponse rapide en cas de catastrophe ». Ce logiciel, baptisé Intelligent Operations Center, synthétise un ensemble de données issues d'une grande variété de systèmes IT, tels que les réseaux d'eau, la traçabilité des équipements publics, les transports ou la gestion du trafic routier. Il offrira visuellement un résumé des données recueillies, en utilisant un certain nombre de règles développées par IBM.
IOC proposera une série de tableaux de bord, ainsi que des connecteurs pour les différents systèmes de gestion back-end. Il comprend aussi un certain nombre de programmes IBM, comme le serveur d'applications WebSphere et la base de données DB2. « Nous avons construit un centre opérationnel qui est capable de récupérer un ensemble de flux en temps réel, travailler et analyser les données et fournir des renseignements essentiels aux gestionnaires afin qu'ils puissent prendre des décisions plus rapidement et de manière plus efficace », précise Karen Parrish.
Cliquer sur l'image pour l'agrandir
Du sur-mesure avec des « faisceaux de points communs »
IBM a conçu IOC de façon modulaire. Différents modules seront lancés au cours des 12 à 18 prochains mois. Ces unités complémentaires couvrent des données spécifiques, telles que la gestion de l'eau ou la sécurité publique. « Les responsables locaux pourront donc intégrer ces modules en fonction de leurs besoins les plus critiques », souligne Karen Parrish et d'ajouter « nous allons construire ces modules à partir des expériences de plusieurs projets individuels et en extraire les redondances ». Aucun d'eux ne sera néanmoins disponible lors du lancement de la solution.
Pour construire ces unités additionnelles, IBM s'appuie sur 2 000 projets qu'elle a réalisés pour des villes comme New York, Memphis, Washington et Dubuque (on peut citer également la ville de Nice qui a emporté en mars dernier le Challenge Smarter Cities pour bénéficier de l'expertise d'IBM en matière de planification stratégique, de gestion des données et de compétences technologiques). Avec ce travail préalable, Big Blue a remarqué des « faisceaux de points communs», comme la gestion centralisée du personnel ou la décongestion du trafic routier.
IBM prévoit le lancement d'IOC à partir du 17 juin prochain. Karen Parrish n'a pas voulu révéler certains détails comme le prix ou la durée d'intégration d'un tel logiciel. Elle a simplement indiqué que le logiciel se connectera facilement à des systèmes IT normalisés et des adaptations particulières seront nécessaires si les systèmes sont plus anciens. La dirigeante a également indiqué que la version initiale du logiciel sera intégrable directement chez le client, mais une offre en mode hébergée est envisagée dans les futures versions.
Illustration: Intelligent Operations Center
Crédit Photo: IBM
(...)
La base de données d'Oracle disponible sur le cloud d'Amazon
L'annonce avait été faite au mois de février dernier, mais il fallait attendre le deuxième trimestre pour officialiser la disponibilité du service, les tarifs et les conditions d'utilisation. Sur ces dernières, les clients ont le choix entre une option «licence incluse» et une option « licence fournie par le client » (BYOL - bring your own license). Les tarifs de base sont de 0,16 dollars de l'heure pour la première option et de 0,11 dollars de l'heure pour la seconde, selon Amazon. Seule la version Oracle Standard Edition One, une version limitée en fonctionnalités de la base de données d'Oracle, est disponible avec l'option « licence incluse ».
Les clients souhaitant utiliser la version Standard Edition ou la version Enterprise Edition, produit phare de l'éditeur, doivent fournir leurs propres licences, celles dont ils disposent déjà ou celles nouvellement acquises auprès d'Oracle. Les licences d'Oracle Enterprise Edition coûtent 47.500 dollars contre 17.500 dollars pour l'édition Standard. Ces prix affichés ne prennent pas en compte les remises octroyées. La version Enterprise Edition comprend un large éventail d'options, facturées séparément, comme Data Guard, Real Application Clusters et Advanced Compression.
Monitoring et intérêt pour les développeurs
Le service comprend aussi le système de gestion CloudWatch d'Amazon, sans coût supplémentaire, qui permet aux clients de surveiller quelle capacité de stockage et quelle quantité de mémoire ils utilisent. Le système prendra automatiquement en charge l'application des correctifs aux bases de données, mais les clients pourront, s'ils le souhaitent, garder le contrôle du calendrier des mises à jour. Les sauvegardes automatiques sont activées par défaut, et les utilisateurs peuvent prendre des instantanés de leur base de données à tout moment, a ajouté Amazon. « La réplication de base de données, essentielle pour la tolérance aux pannes, n'est pas encore disponible pour Oracle sur Amazon, mais sera ajoutée à un moment ou un autre, » a précisé Amazon. Selon Curt Monash, analyste chez Monash Research « cette fonction n'est généralement pas utile en production, » comme il l'écrit sur son blog.
Mais il pourrait y avoir des exceptions, comme avec les applications à courte durée de vie et destinées à un projet spécifique, ou bien lorsque « l'application est assez petite, ou la situation suffisamment désespérée, afin de compenser les inefficacités par la commodité, » écrit-il. « Il y a là un appel clair à exécuter Oracle sur Amazon, en mode de non-production, » a t-il ajouté. D'une part, « la mise en route rapide d'une instance cloud peut avoir beaucoup d'intérêt pour un développeur, » écrit-il. « La même démarche se justifie si vous voulez vendre une application basée sur Oracle et si vous souhaitez proposer une version test ou la mettre en démonstration. En tous cas, c'est ce que l'on peut observer en général quand un logiciel sur site est proposé dans le Cloud», fait remarquer l'analyste.
« Ces observations sont renforcées par le fait que le seul logiciel d'Oracle qu'Amazon peut effectivement licencier, c'est l'édition bas de gamme. » Ceci étant, « un logiciel aussi cher que Oracle Enterprise Edition peut ne pas être adapté au mode de tarification d'Amazon, » a déclaré Curt Monash dans une interview. « Je ne pense pas que beaucoup de clients souhaiteraient faire tourner Oracle Enterprise Edition dans le cloud, de toute façon, » a t-il ajouté. « Celui qui dispose de l'Entreprise Edition préfèrera au contraire en renforcer l'administration pour optimiser ses performances. » (...)(25/05/2011 10:20:32)
Le MDM en mode projet et maturité, selon Business & Décisions
« Il y a deux ans, on y songeait ; l'année dernière, les pionniers commençaient à parler de retours concrets mais encore expérimentaux et limités ; cette année, on peut parler de projets de MDM [Master Data Management, gestion des données de référence, NDLR] très avancés et globaux dans les entreprises » s'est réjoui Jean-Michel Franco, directeur des solutions de Business & Décision. Il s'exprimait dans le cadre de la Matinale du MDM, organisée par la SSII le 24 mai 2011.
Pour Jean-Michel Franco, les données ont, pour les entreprises un double visage, à la manière du Dr Jekyll et de M. Hyde. Si elles permettent une meilleure connaissance du client ou une saine gestion optimisée, elles forment aussi un déluge ni toujours cohérent, ni toujours maîtrisé, ni même sécurisé, à la merci de fuites ou de piratages (comme dans les récentes affaires Sony ou Wikileaks).
Un pilotage métier indispensable
La gestion des données de référence, selon Business & Décision, implique une modélisation des données, une analyse en continu de celles-ci, la mise en oeuvre d'une gouvernance des données (qui fait quoi avec quelles données?), une intégration des données entre elles afin de les mettre en cohérence et enfin une véritable direction de projet. Jean-Michel Franco avertit : « il faut un pilotage métier à la création du modèle de données afin de répondre à un besoin du métier et pas à une problématique technique. Un pilotage par la DSI aboutit toujours à un échec. » Les producteurs de données ont en effet alors tendance à ne plus s'impliquer et à ne pas construire les données comme attendu.
Un projet de mise en oeuvre de MDM dans une banque internationale a ainsi été lié à une gestion du risque client dans le cadre d'une mise en conformité avec les accords Bâle II. La croissance de la qualité des données liée à leur saine gestion a ainsi permis de mieux mesurer le risque client et d'optimiser les réserves de capitaux. Trop souvent, la SSII Business & Décision aurait été appelée en pompier face à de sérieux problèmes de qualité des données avec des impacts sur les métiers. La durée moyenne d'un projet de MDM est de l'ordre de un an selon Business & Décision. Cette période se décompose en six mois de discussions pour calibrer le modèle de données, trois mois pour le mettre ne oeuvre techniquement et trois mois pour le tester et le facturer.
[[page]]
« Mais le MDM ne doit pas être vu comme comme un projet ponctuel ou comme la mise en place d'un produit : c'est une démarche qui doit être maintenue de manière constante pour tous les types de données (personnes, choses, lieux...) » milite Jean-Michel Franco.
La distribution en pionnier
Les mises en place de cette démarche ont été beaucoup constatées dans la distribution, comme avec Boulanger et Truffaut. Les premiers projets ont en effet beaucoup concerné l'unification des données au travers des différents canaux, à commencer par les produits, comme chez Boulanger, mais aussi, de plus en plus, en se penchant sur les données clients. La fameuse vision « à 360° » du client, totalement unifiée, est souvent galvaudée : il arrive que, soudain, on se rende compte que le service après-vente n'a pas été inclus dans cette vision soi-disant globale. Des projets globaux de gouvernance des données commencent aussi à apparaître dans ce secteur. « Un projet de MDM, c'est avant tout du décloisonnement » résume Jean-Michel Franco.
La distribution ne se limite pas à des magasins. RTE est ainsi une filiale d'EDF spécialisée dans le transport et de distribution d'énergie entre producteurs et consommateurs. Pour accomplir ses missions, RTE doit maîtriser les données de consommation et de production d'énergie. Au-delà de l'équilibrage instantané, il faut en effet disposer de données pour des analyses qui permettront de définir les tarifs. Ajoutons que les compteurs intelligents vont faire exploser les volumes et la richesse des données disponibles. RTE a donc construit un référentiel client unique qui alimente tous les logiciels en ayant besoin. Il n'y a ainsi plus de ressaisies et d'erreurs de réconciliations entre fichiers où les identifiants étaient différents. RTE a débuté son projet en janvier 2011 et sa phase de développement a duré quatre mois. La mise en production est prévue à la rentrée 2011.
Une offre pléthorique et diverse
Jean-Michel Franco indique que, pour répondre aux besoins des entreprises, il existe de nombreuses solutions. Mais, même s'il existe des pure players, la plupart des acteurs actuels ont en fait acquis des fournisseurs plus petits leur permettant de mettre pied dans le MDM mais sans pour autant perdre leur approche historique. Ainsi, certains acteurs partent de la gestion de processus (SAP, Oracle...). D'autres ont débuté dans le décisionnel (Informatica, SAS...). Middleware et synchronisation des données ont fourni une autre famille (avec Tibco, IBM...). Enfin, certains acteurs ont une approche de rupture, originale, comme Exalead qui provient du moteur de recherche.
Sapphire 2011 : Avec ASE, SAP s'attaque à la base de données d'Oracle
Dans les mois qui viennent, SAP aura achevé le portage de son application ERP (enterprise resource planning) pour la base de données Adaptive Server Enterprise (ASE) de Sybase. Cette solution offrira aux clients qui tournent actuellement sous Oracle et autres plateformes, une meilleure alternative en terme de coût. C'est ce qu'a annoncé l'éditeur allemand lors de la conférence Sapphire qui se tient cette semaine à Orlando.
Sybase ASE occupe une toute petite part du marché de la base de données, détenu en grande partie par Oracle, IBM et Microsoft. A une exception près : ASE est largement utilisée par les institutions financières. Ce que ne manque pas de souligner SAP dans un communiqué diffusé auprès de sa clientèle : « Les clients ERP auront désormais accès à la même base de données que celle utilisée par Wall Street. » SAP ajoute que « les prochaines versions de SAP ERP seront certifiées « prêtes à installer » avec les versions de Sybase ASE. »
En outre, le cycle de vie de Sybase ASE sera « parfaitement synchronisé avec les politiques de maintenance de SAP pour simplifier les mises à jour et la planification des déploiements. » La combinaison de ASE avec SAP permettra aux clients de traiter avec une entreprise unique dont l'objectif essentiel sera « d'optimiser le fonctionnement des opérations professionnelles et de proposer des licences et des contrats de maintenance à des conditions attractives, » a poursuivi l'éditeur allemand.
Une intégration soignée pour gagner en performances
Même si ce type d'estimations est difficile à établir, compte tenu des remises importantes souvent accordées sur le prix dans les négociations de contrats logiciels, ce que les clients gagneront en choisissant ASE à la place d'Oracle n'est pas très précis. D'autant que, on ne sait pas comment Oracle pourrait réagir en termes de prix ou d'avantages client, si SAP parvenait à siphonner une partie importante des recettes résultant de la vente de sa base de données.
« Quoi qu'il en soit, des tests récents indiquent un meilleur rapport « prix-performance » pour l'exécution de l'ERP de SAP sur ASE à la place de bases de données concurrentes, » a déclaré dans une interview John Chen, le PDG de Sybase, une entreprise dirigée désormais comme une filiale indépendante de SAP. « Les ingénieurs de Sybase procèdent encore à certains réglages système, et les avantages pourraient être plus importants, » a ajouté le PDG de Sybase.
Deux bases de données chez SAP
Un autre élément qui manque de clarté, c'est la manière dont vont coexister ASE et la base de données in-memory HANA de SAP au fil du temps. Ce produit, plus récent que ASE, était, jusqu'à présent, principalement destiné aux charges de travail analytiques, mais pourrait tout aussi bien être positionné sur les systèmes transactionnels. Selon John Chen, « la probabilité d'assister à des frictions entre les deux produits est faible. D'une part, il faudra un certain temps avant que HANA soit prête pour répondre aux demandes des gros clients SAP en matière de système transactionnel, et l'ASE dispose d'une base installée saine que SAP pourra « servir correctement. »
La question est aussi de savoir comment SAP va réussir à attirer vers elles des vendeurs non-ASE vers la plate-forme. Typiquement, les migrations de base de données ne sont pas une mince affaire, ce dont convient volontiers le PDG de Sybase. « Ce n'est pas la chose la plus facile à accomplir. Les migrations demandent beaucoup d'implication et d'investissement. » Selon lui, « tout dépend de la façon dont les applications compatibles avec la base de données originale ont été écrites. » « S'il n'y a pas de multi-threading, et un minimum de déclencheurs, alors, techniquement, il faudra migrer, compiler et exécuter. »
L'entreprise est « très déterminée à rendre le processus de migration plus facile, » a déclaré John Chen. « Nous avons déjà deux pilotes pour effectuer les migrations, et une demi-douzaine d'autres sous le coude, » a-t-il ajouté. « Les entreprises concernées sont très importantes. Pas dans le premier quart, mais dans le premier tiers du classement mondial, » a-t-il précisé. « Cependant, les plus grandes opportunités pour l'ASE se trouvent dans de nouveaux projets, ceux pour lesquels les clients choisiront le produit de SAP plutôt que celui d'Oracle ou d'autres produits, et non pas les migrations, » a-t-il estimé.
[[page]]
Pendant ce temps, SAP cherche également à profiter de la récente décision d'Oracle d'arrêter le développement de logiciels pour les puces Itanium d'Intel. Les serveurs Integrity de Hewlett-Packard tournent sur des puces Itanium et exécutent son OS HP-UX. SAP s'est engagé à long terme pour HP-UX, tant pour ses applications professionnelles que pour l'ASE. De plus, Red Hat est prêt à offrir à ses clients la possibilité d'exécuter le logiciel SAP avec ASE sur son OS RHEL (Red Hat Enterprise Linux), comme l'a indiqué l'entreprise.
Plus avant, SAP prévoit de certifier Sybase ASE pour les autres produits de son portefeuille, dont CRM (customer relationship management), NetWeaver Portal et NetWeaver Business Warehouse. L'annonce de Sybase ASE, qui met l'accent sur la réduction des coûts opérationnels pour les clients, se démarque du marketing de SAP autour de la mobilité, de l'informatique in-memory et du SaaS (Software as a Service).
Des packs pour Business Suite 7
Dans une autre annonce, plutôt destinée à sa base installée, SAP a informé de la disponibilité d'un « Enhancement Pack » Innovations 2010 pour les utilisateurs de la Business Suite 7. Les packs d'amélioration (EHP) des ERP SAP sont censés offrir aux clients de nouvelles fonctionnalités sans les difficultés d'une mise à niveau complète. Mais, dans la pratique, le processus d'application des packs demande du travail. Le nouveau pack comprend plus de 300 fonctionnalités supplémentaires. « SAP prévoit d'augmenter le rythme de livraison des packs EHP, a indiqué Jim Hagemann Snabe co-CEO de l'entreprise lors d'une keynote. « Nous pensons pouvoir livrer un nouveau pack tous les trois mois, » a-t-il ajouté.
(...)(17/05/2011 10:40:49)Bases de données : IBM met le paquet pour récupérer les clients d'Oracle
Les entreprises exploitant la base de données et les solutions middleware d'Oracle intéressent vivement IBM. Pour les attirer, ce dernier a concocté quelques offres tentatrices. Il leur propose d'abord de réaliser une analyse financière calculant combien d'argent ils économiseraient en passant des produits d'Oracle à sa propre base de données DB2 et à son serveur d'application WebSphere. S'y ajoute une évaluation technique personnalisée et un plan de migration destiné à montrer aux clients la rapidité et la facilité avec laquelle l'opération pourrait s'effectuer.
IBM complète le tout d'une offre d'étude de faisabilité (proof of concept) qui sera réalisée, au choix, dans ses laboratoires ou sur le site du client. L'objectif étant de démontrer les bénéfices potentiels de l'évolution. Des sessions de formation (une centaine) sont également proposées aux équipes techniques spécialisées sur les produits Oracle afin de les aider à se mettre à niveau rapidement sur les technologies IBM, précise le communiqué diffusé vendredi dernier par Big Blue. Et les clients d'Oracle pourront accéder à ces différentes offres sans bourse délier, souligne Bernie Spang (en photo), directeur de la stratégie d'IBM pour l'activité bases de données.
Enfin, Big Blue a également préparé plusieurs solutions de financement pour les entreprises intéressées, l'une d'elles étant assortie d'un taux d'intérêt à 0% pendant douze mois.
Jusqu'à 30% d'économie sur les coûts d'achat
IBM affirme que ses efforts pour faire migrer les clients d'Oracle ont porté leurs fruits. Selon ses chiffres, l'an dernier, plus de 1 000 clients de la base de données concurrente ont choisi de passer à DB2 et plus de 400 utilisateurs de WebLogic ont retenu WebSphere. Parmi ses plus récentes conquêtes, le fournisseur cite la Deutsche Postbank et le Russe Gazprom Neft, pétrolier et fournisseur de gaz. Une précision s'impose néanmoins. Si certains clients ont effectivement réalisé des migrations à grande échelle vers IBM, d'autres ont simplement choisi Big Blue plutôt qu'Oracle dans le cadre d'un nouveau projet, reconnaît Bernie Spang. Par ailleurs, ces chiffres avantageux ne font évidemment pas mention des clients IBM qui seraient passés à Oracle ou qui auraient évolué vers une autre base concurrente au cours des derniers mois.
Malgré tout, les bénéfices d'une migration vers IBM sont significatifs, insiste Bernie Spang. Il indique que certains des clients Oracle qui ont changé pour IBM ont économisé environ 30% dans les seuls coûts d'acquisition sur une période de trois ans, sans compter des dépenses réduites au niveau opérationnelle sur les notes d'électricité et de refroidissement des systèmes.
S'il reconnaît que migrer une base de données n'est pas tâche aisée, le directeur de la stratégie d'IBM souligne que la firme d'Armonk a réalisé ces dernières années deux mises à jour de DB2 qui facilitent ce type de mise en oeuvre. Au nombre de ces améliorations figure une couche de compatibilité supposée permettre aux applications écrites pour Oracle de tourner sur DB2 avec un minimum de modifications, voire aucune. « Cela a radicalement changé la donne économique de la migration », affirme Bernie Spang.
La concurrence s'exacerbe entre IBM et Oracle
Quoi qu'il en soit, les présentes offres mettent en lumière, s'il en était besoin, la concurrence exacerbée que se livrent IBM et Oracle depuis que ce dernier est devenu constructeur de matériel à la suite du rachat de Sun Microsystems. L'argumentaire d'Oracle s'appuie maintenant sur la complétude de ses solutions intégrées allant de la couche stockage aux serveurs, pour la partie matérielle, et du middleware aux applications métiers, pour la partie logicielle. IBM se révèle moins puissant qu'Oracle sur la dernière catégorie, celles des applications d'entreprise, en particulier sur la partie ERP.
Plutôt que d'acquérir ou de développer son propre ERP, IBM a choisi de se focaliser sur des partenariats avec des éditeurs tels que SAP ou Lawson Software, apportant son infrastructure matérielle et logicielle comme socle sous-jacent à ces applications. On peut néanmoins imaginer qu'à moyen ou plus long terme, les relations entre IBM et SAP pourraient être altérées, ce dernier portant actuellement la Business Suite, son ERP vedette, sur la base de données Adaptive Server Enterprise (ASE) qu'il a acquise avec le rachat de Sybase. On s'attend à voir un jour l'éditeur allemand inciter ses clients exploitant actuellement la base de données d'Oracle (et ils sont nombreux) à utiliser plutôt Sybase ASE pour économiser de l'argent. En revanche, on ignore encore s'il procédera de la même façon avec DB2. « Les relations entre IBM et SAP sont aujourd'hui très solides, rappelle Bernie Spang en soulignant que SAP lui-même s'appuie sur DB2 pour gérer ses propres activités.
Illustration : Bernie Spang, directeur de la stratégie d'IBM pour l'activité bases de données (crédit : IBM)
SkySQL s'implante chez Virgin Mobile
Le prestataire de maintenance alternatif pour la base de données open-source MySQL s'est constitué suite au rachat de la base de données libre par Sun, lui-même absorbé par Oracle. La communauté des utilisateurs s'était émue des évolutions du service proposé par ces entreprises. Le caractère open-source de MySQL a rendu possible la mise en place d'un tel support alternatif, évidemment moins onéreux.
Les conditions exactes consenties à Virgin Mobile n'ont pas été rendues publiques mais SkySQL a indiqué qu'il s'agissait d'une offre forfaitisée de son catalogue, très légèrement modifiée.
Un SGBD libre et un support alternatif pour le coeur de métier
Virgin Mobile utilise, depuis son lancement, des bases de données MySQL pour délivrer tous ses services mobiles texte, e-mail données et web. D'une manière générale, cet opérateur a fondé les applicatifs au coeur de son métier sur l'architecture LAMP (Linux, Apache, MySQL, PHP/Perl/Python), essentiellement pour baisser les coûts par rapport aux technologies propriétaires équivalentes.
Celles-ci doivent bien sûr bénéficier d'une haute disponibilité et d'un support 24 heures sur 24, 7 jours sur 7. Philippe Maugest, secrétaire général de Virgin Mobile France explique : « nous garantissons la continuité de nos investissements : SkySQL est en effet capable de fournir le support technique de haute qualité dont nous avons besoin, avec une équipe d'experts MySQL que nous connaissons déjà. »
| < Les 10 documents précédents | Les 10 documents suivants > |