(Crédit : Google Cloud)")
Pour mieux analyser les volumes croissant de données, Google Cloud veut, à son tour, unifier l'accès aux datawarehouses et data lakes. Des éditeurs spécialisés sur la gestion de données comme Snowflake ou Databricks (par ailleurs partenaire) en ont fait un de leurs principaux atouts, avec le succès que l’on sait. Chez Google Cloud, c’est la vocation de BigLake, un moteur de stockage de data lake annoncé cette semaine, en préversion, par le fournisseur de services cloud. Celui-ci va contribuer à effectuer de façon unifiée des tâches analytiques et des workloads d’apprentissage machine à partir de données stockées sur des data lakes et datawarehouses distincts sans être entravé par le format de stockage sous-jacent et sans devoir déplacer ou dupliquer les données.
Lors d’un point presse, Gerrit Kazmaier, DG et vice-président de l’activité Database, Data Analytics et BI de Google Cloud, a donné la mesure des volumes déjà traités par le fournisseur cloud. Les clients de son datawarehouse BigQuery analysent 110 téraoctets de données par seconde, plusieurs centaines d’entre eux ayant des environnements supérieurs à 1 pétaoctet. Spanner, le service de base de données SQL managé, traite plus de 2 milliards de requêtes par seconde, en pointe. Et Bigtable, le service NoSQL, plus de 5 milliards de requêtes par seconde, en pointe. Autre indicateur, sur l’apprentissage machine, les clients de BigQuery et de la plateforme ML Vertex AI ont multiplié par 2,5 les modèles ML par rapport à 2020.
Support du format Parquet
« Les données de toutes natures sont historiquement stockées à des endroits différents dans les organisations. Au fur et à mesure, ces dernières sont devenues de plus en plus concernées par les problématiques de gouvernance, les risques et les coûts associés. BigLake brise ces silos et facilite la gouvernance », a résumé Sudhir Hasbe, directeur senior produit chez Google Cloud. Avec le moteur BigLake, Google Cloud dit fournir des contrôles d’accès granulaires avec une API qui couvre des formats de fichiers ouverts comme Parquet et prend en compte le moteur de traitement parallèle Spark pour les analyses à grande échelle.
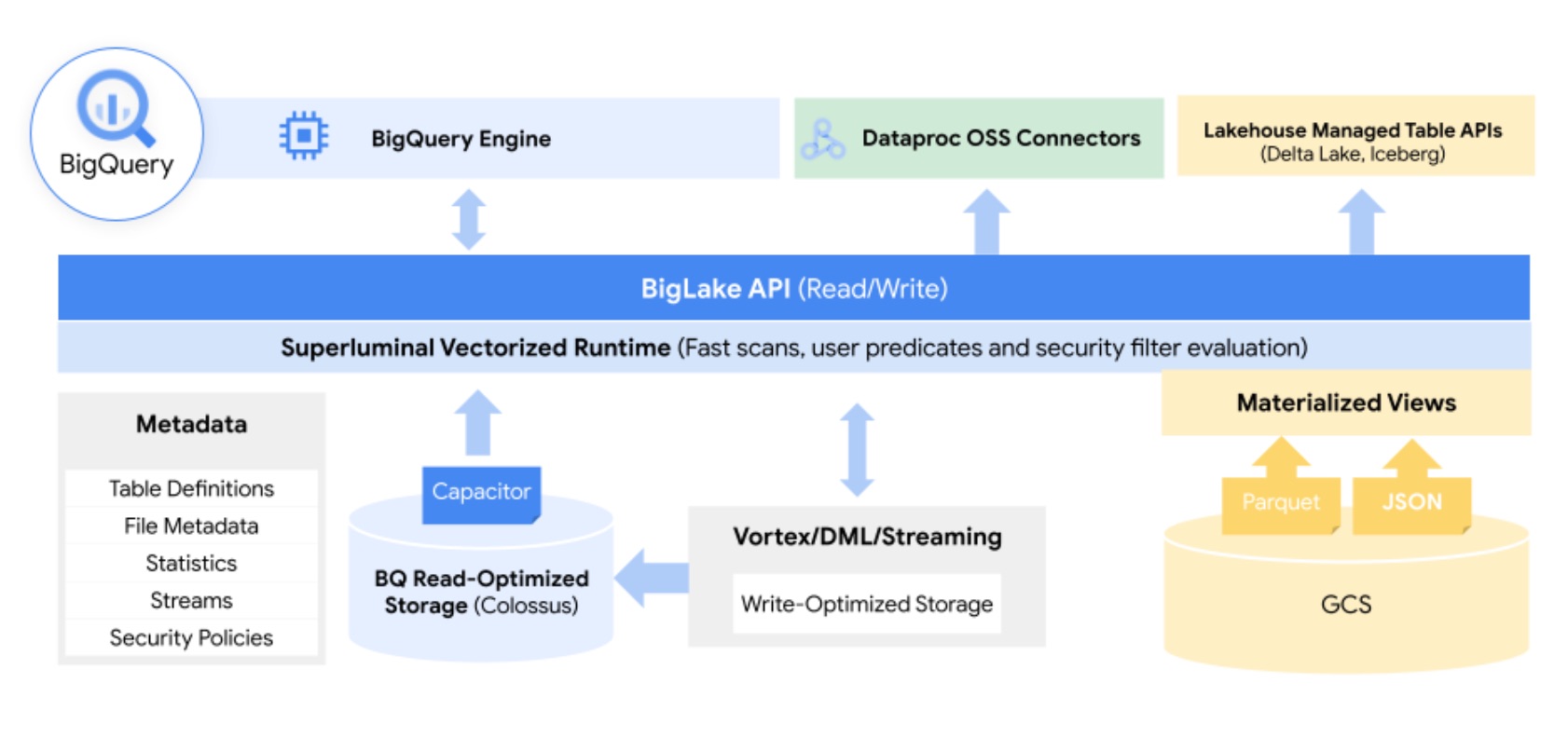
Le rôle de BigLake est d’unifier l’accès aux entrepôts de données et aux data lakes sans se préoccuper du format de fichier sous-jacent. (Crédit : Google Cloud)
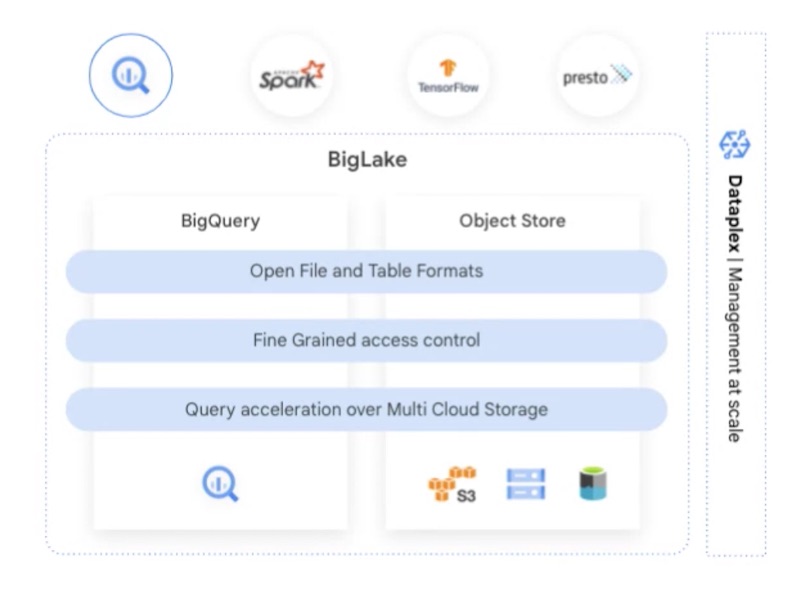
BigLake accepte les formats de données ouverts comme Parquet et s'appuie sur Dataplex, fabric de données pour les sources distribuées. (Crédit : Google Cloud)
En complément, Google Cloud prépare actuellement un autre produit, Spanner change streams, qui arrivera sous peu pour tracer en temps réel les modifications effectuées (insertions, mises à jour, suppressions) au sein du service SQL. L’objectif est de diffuser en temps réel ces changements dans l’ensemble de la database Spanner d’un client pour avoir accès aux données les plus récentes sur les analyses en temps réel faites sur BigQuery et répercuter les changements via pub/sub sur les applications en aval.

Spanner change streams trace les modifications dans les sources de données, également à des fins de conservation et d'audit. (agrandir l'image)
Vertex AI Workbench est disponible
Les efforts de Google Cloud pour unifier la gestion des données concernent également Vertex AI, la plateforme de conception, déploiement et mise à l’échelle de modèles d’apprentissage machine. Sur ce terrain, le fournisseur livre maintenant Vertex AI Workbench, qui réunit au sein de la même interface les outils destinés à l’analytique, aux data scientists et au machine learning. Vertex AI Workbench s’intègre nativement avec BigQuery, avec Serverless Spark, ainsi qu’avec Dataproc, le service Spark et Hadoop managé pour créer rapidement des clusters. Selon Google Cloud, Vertex AI Workbench permettrait de construire, entraîner et déployer des modèles ML cinq fois plus vite que les notebooks classiques. Le fournisseur cloud va par ailleurs apporter à sa plateforme de machine learning un référentiel pour centraliser la découverte, le partage et la gouvernance des modèles ML, incluant ceux de BigQuery ML. Dénommé Vertex AI Model Registry, ce référentiel est pour l’instant en préversion.
Vertex AI Model Registry va apporter un référentiel pour le partage des modèles ML. (Crédit : Google Cloud)
Le train d’annonces de Google Cloud se prolonge sur la BI. Avec Connected Sheets for Looker, les utilisateurs du logiciel Looker pourront interagir avec les données à travers une interface de tableur comme Google Sheets. Il sera également possible d’accéder aux modèles de données de Looker à partir de l’outil de reporting Data Studio de Google.
Pour mettre en oeuvre les capacités qu’il déploie ainsi autour de BigQuery, Google indique proposer à ses clients un support d’ingénierie spécifique et de co-marketing à son écosystème de partenaires, à travers l’initiative Built with BigQuery. Celle-ci s’accompagne de validations sur les solutions bâties par les partenaires sur le datawarehouse.
Une Data Cloud Alliance avec Databricks, Dataiku, MongoDB, Neo4j...
Google Cloud cherche aussi à rallier, principalement autour de ses outils, sur le partage des données avec la Data Cloud Alliance. Cette dernière réunit aussi Databricks, Confluent, le Français Dataiku, Elastic, Fivetran, MongoDB, Neo4j, Redis, Starbust, Accenture et Deloitte. L’objectif est de travailler sur la portabilité et l’accessibilité des données entre environnements disparates.
Parmi les signataires, Databricks, « qui s’intègre déjà de façon transparente avec BigQuery », ainsi que nous l’a rappelé Sudhir Hasbe, va rendre ce mois-ci sa solution Databricks SQL disponible sur Google Cloud. MongoDB de son côté travaille sur l’intégration en temps réel des données opérationnelles de sa database managée avec BigQuery (et vice-versa) via Dataflow Templates. Pour sa part, Fivetran, dont les solutions automatisent la synchronisation entre sources de données, prend en compte le framework Cortex pour les architectures de référence. Autre membre de l'alliance, Starbust fournit une distribution de Trino (ex-Presto SQL). Cet éditeur, qui a ouvert une filiale en France l’an dernier, va pousser une offre packagée pour supporter la fédération de données multisources avec BigQuery et Dataplex. Enfin, la base de données graphe Neo4j lance un service managé pour développer des applications basées sur des algorithmes avec Neo4j Graphe Data Science sur Google Cloud.
Commentaire