")
Il y a quelques semaines, l’éditeur français Dataiku a livré son accélérateur no-code CloudStack pour faciliter le déploiement de sa plateforme de gestion de donnés et d’intelligence artificielle dans le cloud public d’AWS. Une fois déployée, les différents utilisateurs, équipes métiers et data scientists, pourront y accéder à partir de leur navigateur web pour travailler sur les données. Les uns pour créer rapports et tableaux de bord, les autres pour bâtir des modèles d’apprentissage machine. Cet accélérateur CloudStack n’est pas facturé en surcoût.
Le déploiement de la plateforme sur AWS se fait en trois étapes que Dataiku décrit dans un billet à l’attention des architectes cloud. La première consiste à créer des permissions sur la topologie de cloud privé virtuel AWS existante, pour la création des instances Dataiku. Vient ensuite le déploiement, à l’aide de quatre modèles prêts à l’emploi comportant ce qu’il faut pour démarrer et développer des projets analytiques et IA et les mettre en production dans le cloud. La troisième étape concerne la maintenance, l’évolution et la mise à jour de la plateforme Dataiku sur AWS par l’équipe IT de l’entreprise. Avec CloudStack, le temps de déploiement se trouve réduit de quelques jours ou semaines à quelques heures, selon son éditeur.
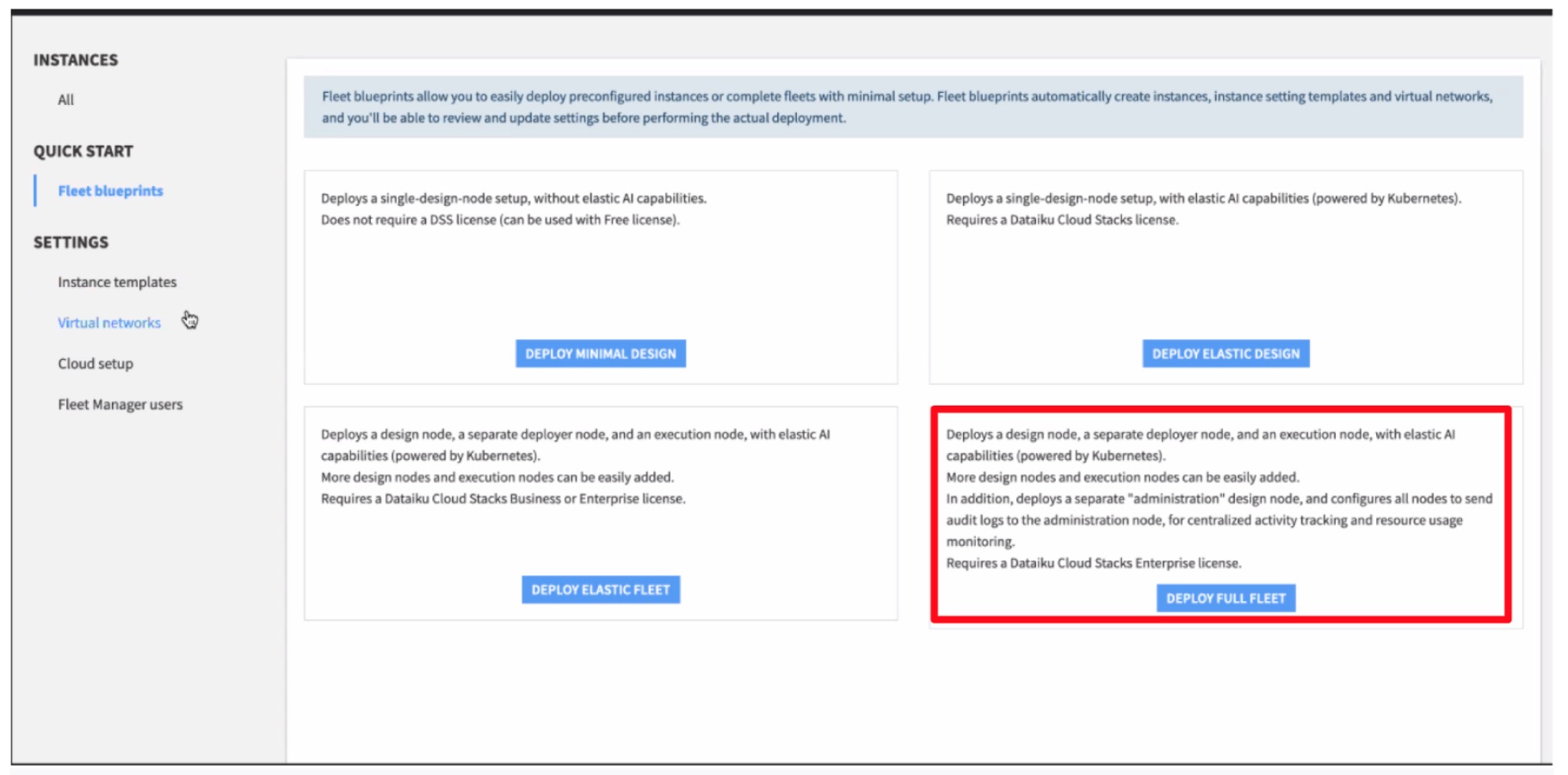
(agrandir l'image) Les quatre modèles de déploiement proposent différents plans d'architecture : environnement de conception à un seul noeud pour la création de pipelines et modèles de données, ou environnements pour équipes de data science ayant besoin de ressources élastiques (clusters Kubernetes). Crédit : Dataiku
Accès à des services d'AWS comme Athena, Glue, Rekognition...
Une fois la plateforme de gestion de données et d'IA déployée sur AWS, les utilisateurs métiers prépareront leurs jeux de données à l’aide des fonctions visuelles no-code de Dataiku ou à l’aide d’un code SQL personnalisé. Les data scientists de leur côté accèderont à la dernière version AutoML de la plateforme pour leurs modèles de machine learning. Ils pourront s’appuyer sur le service EKS (Elastic Kubernetes Service) d’AWS. Parmi les autres fonctionnalités disponibles pour gérer les modèles ML figurent la surveillance des pipelines de données et des modèles, l’alerte en cas de data rift, les tests A/B et la réformation des modèles, précise Dataiku. Des fonctions de gouvernance sont également proposées pour réduire les risques associés aux modèles. Par ailleurs, les utilisateurs de la plateforme pourront aussi se connecter à divers services d'AWS, notamment des services administrés comme Athena et Glue, Comprehend ou Rekognition.
Hommes et femmes de la data science
A la fin de l’année dernière, pour mieux faire connaître les grandes figures de la data science, qui ont fait avancer la discipline et continuent à le faire, Dataiku a lancé le site History of Data Science. C’est le fruit d’un travail de collaboration de plusieurs mois. A côté de figures historiques comme Charles Babbage (1791-1871), qui a décrit le principe de la machine à calculer, ou dans les années 50, l’équipe du Dartmouth Summer Research Project qui a posé les fondements de l’intelligence artificielle, on y découvre les ingénieur(e)s, chercheurs et chercheuses qui sont au coeur de l’innovation en data science aujourd’hui.
Au fil des portraits, défilent par exemple les profils de Fei-Fei Li, professeur d’informatique à l’Université Stanford, Yoshua Bengio, l’un des pionniers de l’apprentissage profond, lauréat du prix A.M. Turing 2018 aux côtés du Français Yann LeCun et de Geoffrey Hinton, ou encore Judea Pearl qui s’est vu décerner le prix en 2011, « connu pour avoir établi une approche probabiliste de l’IA et développé des réseaux bayésiens, ainsi que les principaux algorithmes utilisés pour l’inférence dans ces modèles », relate notamment History of Data Science. Sur le site, on accède aussi au jeu Beat the linear Algorithm Regression, et on peut obtenir un exemplaire de l'album Innovators of Data Science: From Bayes to Bayesian Neural Networks.
Commentaire