
")
« Une nouvelle ère de transparence pour Twitter ». Le ton est donné, l’heure est à la responsabilité. Elon Musk avait évoqué à plusieurs reprises – avant et après le rachat – sa volonté de rendre public le code source de l’algorithme du réseau social. Sous ses airs de girouette, il aura finalement tenu parole ce 31 mars en l’annonçant sur Twitter. Sur GitHub, n’importe qui peut donc trouver deux référentiels (main repo , ml repo) contenant le code source de son algorithme de recommandations. Il a été publié sous licence publique générale GNU Affero v3.0.
A noter que la version ne comprend pas le code lié à la sécurité et la confidentialité des utilisateurs ou la capacité de protéger sa plateforme contre les mauvais acteurs. Dans sa déclaration, Twitter indique également que « la version n'inclut pas non plus le code qui alimente nos recommandations publicitaires. Nous avons également pris des mesures supplémentaires pour garantir la protection de la sécurité et de la confidentialité des utilisateurs, y compris notre décision de ne pas publier les données d'entraînement ou les poids de modèle associés à l'algorithme Twitter à ce stade ».
Un pipeline de recommandations en trois étapes
Dans le détail, la base des recommandations de Twitter est un ensemble de modèles et de fonctionnalités de base qui extraient des informations latentes des tweets, des utilisateurs et des données d'engagement. Ces modèles visent à répondre à des questions importantes sur le réseau Twitter, telles que « Quelle est la probabilité que vous interagissiez avec un autre utilisateur à l'avenir ? ou, « Quelles sont les communautés sur Twitter et quels sont les Tweets à la mode en leur sein ? ». Un service baptisé Home Mixer assure le fonctionnement de For You. Comme l’indique l’équipe d’ingénierie : « Home Mixer est construit sur Product Mixer, notre framework Scala personnalisé qui facilite la création de flux de contenu. Ce service agit comme l'épine dorsale du logiciel qui relie différentes sources de candidats, fonctions de notation, heuristiques et filtres ».
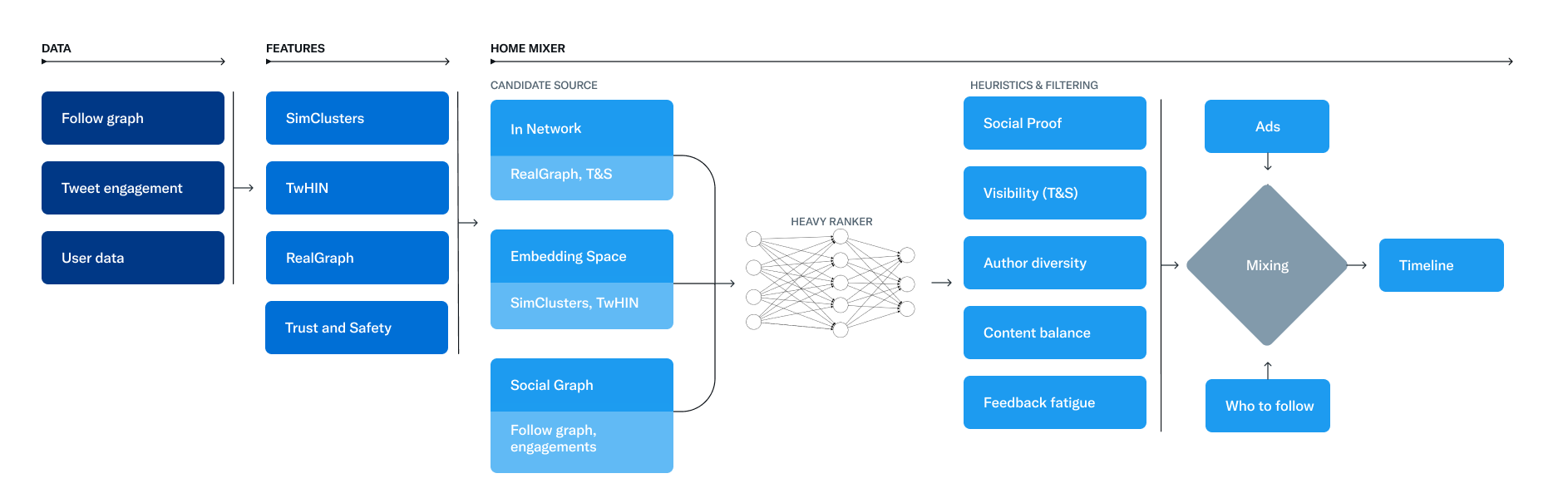
Ce diagramme illustre les principaux composants utilisés pour construire une chronologie. (Crédit : Twitter)
Le pipeline de recommandations est composé de trois étapes principales qui se basent sur ces fonctionnalités. La première consiste à récupérer les meilleurs Tweets à partir de différentes sources de recommandation dans un processus appelé recherche de candidats. Dans un second temps, chaque tweet est classé à l'aide d'un modèle d'apprentissage automatique. Enfin, la dernière étape consiste à appliquer des heuristiques et des filtres, tels que le filtrage des tweets des utilisateurs bloqués, du contenu NSFW (no safe for work) et des tweets déjà vus. Concernant le choix des sources, Twitter admet faire un mix entre les personnes suivies (appelées In-Network) et les personnes non suivies (Out-of-Network). Pour ce faire, il extrait les 1 500 meilleurs tweets d'un pool de centaines de millions via ces sources. Aujourd'hui, la chronologie For You se compose en moyenne de 50 % de tweets In-Network et de 50 % de tweets Out-of-Network, bien que cela puisse varier d'un utilisateur à l'autre.
Lors du classement des messages, celui-ci est réalisé avec un réseau neuronal de 48 millions de paramètres qui est continuellement formé sur les interactions tweet pour optimiser l'engagement positif (par exemple, j'aime, retweets et réponses). Ce mécanisme de classement prend en compte des milliers de fonctionnalités et produit dix étiquettes pour donner à chaque tweet un score, où chaque index représente la probabilité d'un engagement. « Nous classons les tweets à partir de ces scores » précise la firme. Après cette étape, le réseau social applique des modèles heuristiques et des filtres pour implémenter diverses fonctions du produit. L’objectif : créer un flux équilibré et diversifié. Cela comprend notamment le filtrage de la visibilité, la diversité des auteurs, l’équilibrage du contenu (entre les Tweets In-Network et Out-of-Network), etc.
Un pipeline qui s'exécute 5 milliards de fois par jour
A la suite de ces trois étapes, Home Mixer dispose d'un ensemble de tweets prêts à être envoyés sur chaque terminal. Dernière étape du processus, le système mélange les tweets avec d'autres contenus non-tweet comme les publicités, les recommandations de suivi et les invites d'intégration, qui sont renvoyées sur chaque terminal pour s'afficher. Le pipeline s'exécute environ 5 milliards de fois par jour et se réalise en moins de 1,5 seconde en moyenne. Une seule exécution de pipeline nécessite 220 secondes de temps CPU, soit près de 150 fois la latence que l’utilisateur perçoit sur l'application.
Twitter indique par ailleurs être ouvert à toute exposition des problèmes sur GitHub et se dit prêt à recevoir des suggestions sur l'amélioration de l'algorithme de recommandations. « Nous travaillons sur des outils pour gérer ces suggestions et synchroniser les modifications dans notre référentiel interne. Tout problème ou problème de sécurité doit être acheminé vers notre programme officiel de primes de bogues via HackerOne » précise la firme. Espérons que cela soit le début d’un pas en avant vers davantage de transparence de la part de Twitter et que son propriétaire ne se décide pas à en faire deux en arrière dans les semaines à venir.
Commentaire